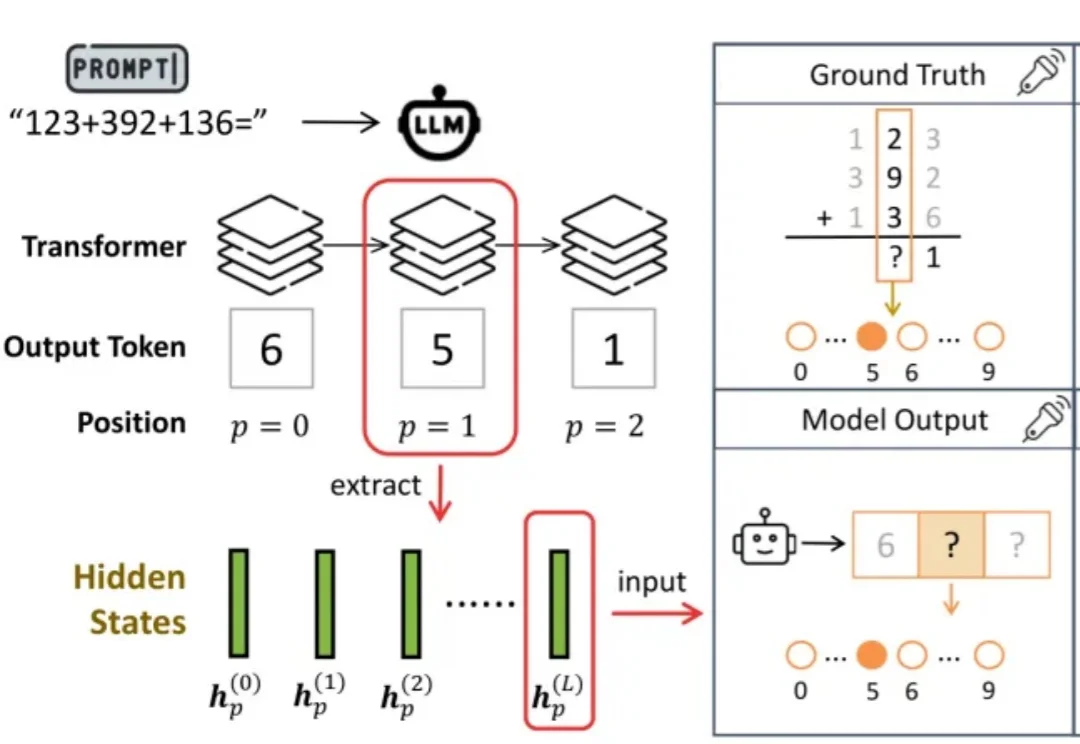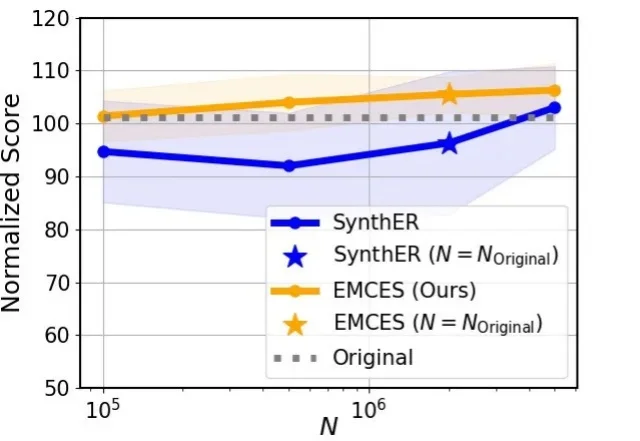
ICML26 | 浙江理工大学马啸讲师和南京大学李武军教授课题组联合提出EMCES:为强化学习合成更有价值的样本
ICML26 | 浙江理工大学马啸讲师和南京大学李武军教授课题组联合提出EMCES:为强化学习合成更有价值的样本近年来,强化学习在游戏智能体、具身智能、大语言模型等领域取得了显著进展。然而,在真实世界中,强化学习仍面临一个核心难题:高质量样本的获取不仅成本高昂,还可能带来多种风险。因此,样本增强成为缓解强化学习中样本获取成本高、风险大等问题的重要途径之一。
来自主题: AI技术研报
9712 点击 2026-07-02 14:31