# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
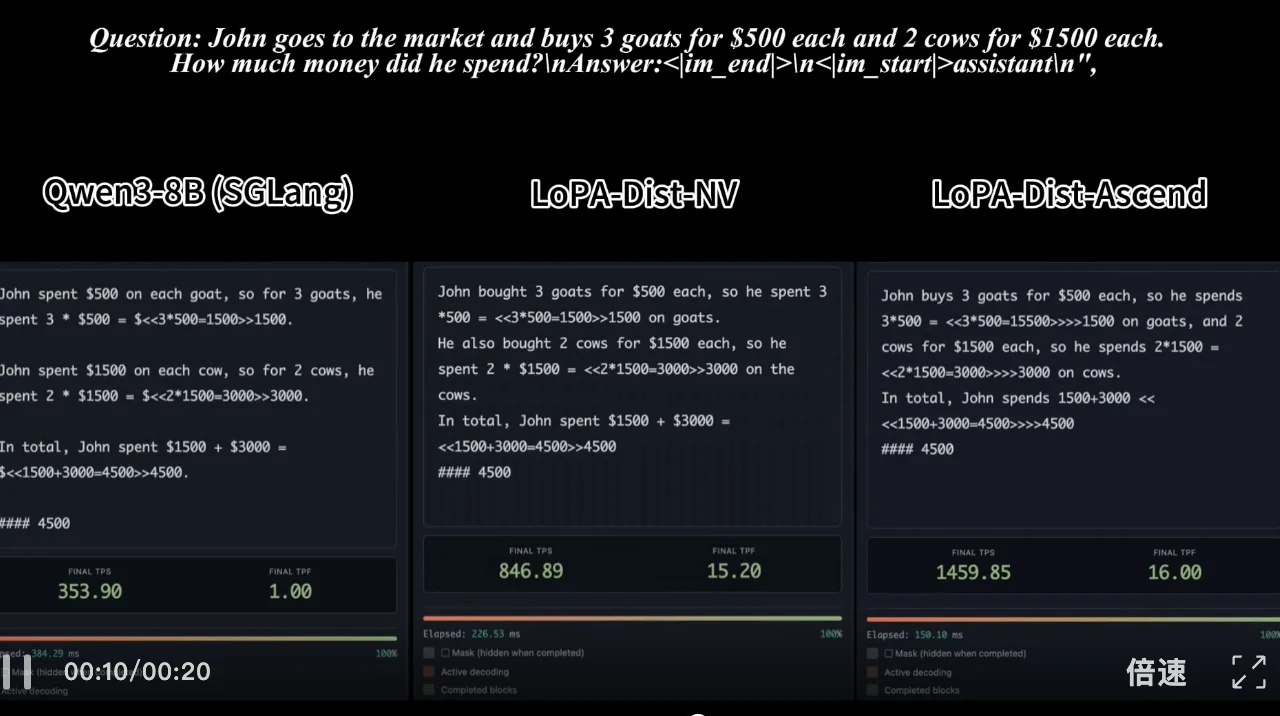
视频 1:单样例推理速度对比:SGLang 部署的 Qwen3-8B (NVIDIA) vs. LoPA-Dist 部署 (NVIDIA & Ascend)(注:NVIDIA 平台相同,配置对齐)
在大语言模型(LLMs)领域,扩散大语言模型(dLLMs)因其并行预测特性,理论上具备超越传统自回归(AR)模型的推理速度潜力。然而在实践中,受限于现有的解码策略,dLLMs 的单步生成往往局限于 1-3 个 Token,难以真正释放其并行潜力。
近期,上海交通大学 DENG Lab 联合华为的一项新研究打破了这一瓶颈。该工作提出了一种名为 LoPA (Lookahead Parallel Decoding) 的无需训练的解码算法,通过主动探索最优填词顺序,显著提升了 dLLMs 的推理并行度和吞吐量。
本文作者团队来自上海交通大学 DENG Lab 与华为。该研究由徐晨开、金义杰同学等人共同完成,指导教师为邓志杰老师。DENG Lab 隶属上海交通大学,致力于高效、跨模态生成模型的研究。

实验显示,LoPA 将 D2F-Dream 在 GSM8K 基准上的单步生成 Token 数(TPF)从 3.1 提升至 10.1,并行度提升超 3 倍。配合团队自研的 LoPA-Dist 分布式推理系统,在华为 Ascend 910C 平台上实现了 1073.9 tokens/s 的单样本吞吐量,不仅大幅超越基线模型,更将 dLLMs 的推理效率推向了新高度。
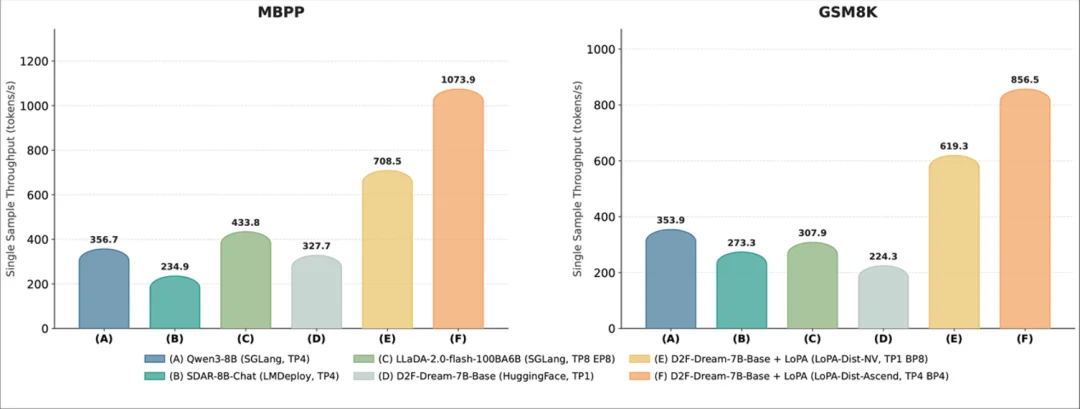
图 1:LoPA 的吞吐量结果展示。LoPA 将 D2F-Dream 的单样本吞吐量在 MBPP 和 GSM8K 上分别提升至高达 1073.9 和 856.5 个 token/s,显著优于基线方法。
简单来说,LoPA 为 dLLMs 赋予了以下核心特性:
1. 极高的并行度:首次将 dLLMs 的每步生成数量(TPF)提升至 10 Token 量级,突破了传统方法的效率瓶颈。
2. 无需训练:作为一种即插即用的解码算法,无需对模型进行重训或微调。
3. 前瞻并行解码:通过引入分支并行机制,主动探索不同的填词顺序(TFO),避免模型陷入低置信度的局部最优。
4. 系统级加速:配套设计的 LoPA-Dist 系统,支持 CUDA 和 Ascend 双平台,通过分支并行最大化硬件利用率。
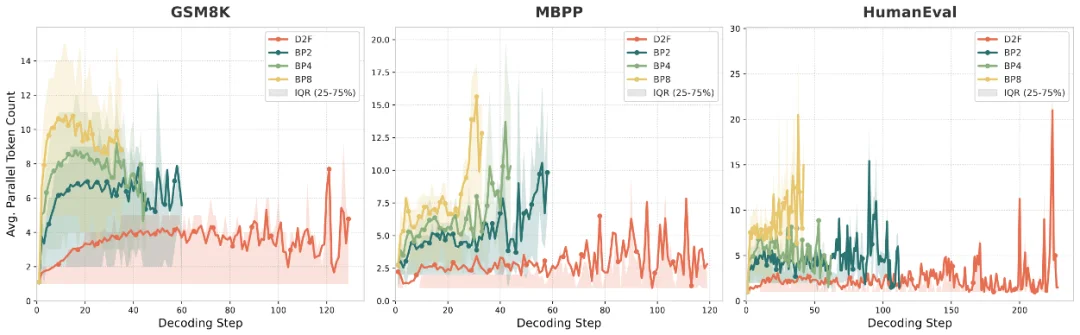
图 2:对不同分支数的 D2F-Dream 进行 LoPA 扩展性分析。结果表明,LoPA 能有效扩展 D2F 的 TPF,使其峰值超过 10,从而显著减少解码总步骤数。
问题的根源:填词顺序限制并行潜力
dLLMs 理论上支持全序列并行生成,但在实际应用中,现有的主流模型(如 Fast-dLLM, D2F, SDAR)普遍采用置信度驱动采样(Confidence-Driven Sampling)。这种策略倾向于贪婪地优先填充当前置信度最高的位置。
研究团队发现,并行度的高低与填词顺序(Token Filling Order, TFO)高度相关。贪婪策略虽然在当前步骤保证了准确性,但并不考虑后续步骤的预测置信度,导致模型在后续迭代中并没有充分释放并行度。
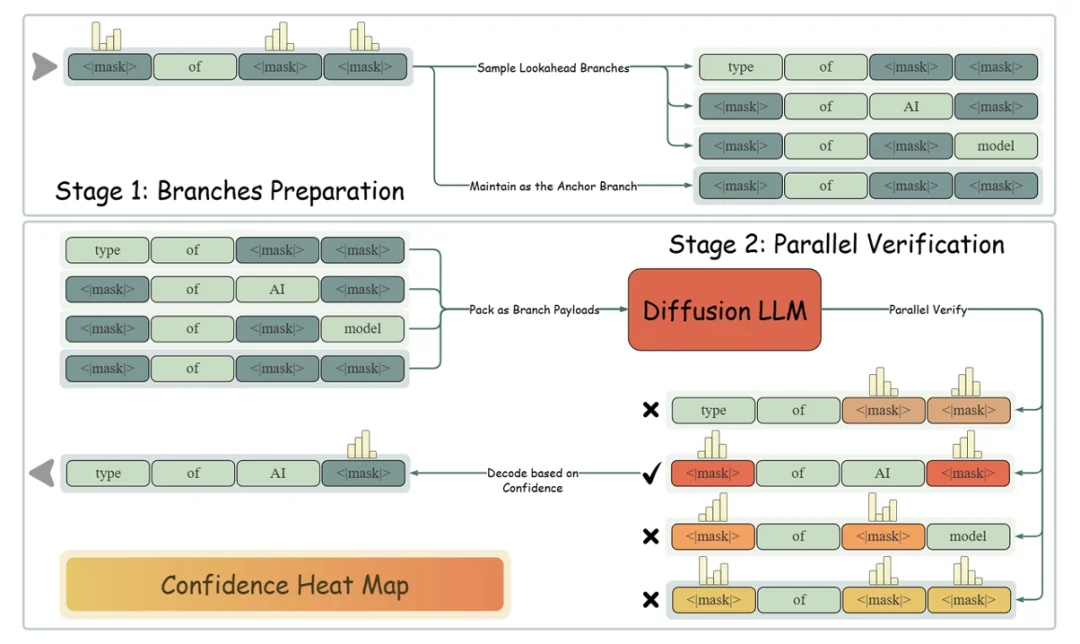
图 3:LoPA 算法流程概览。在每次迭代中,LoPA 通过独立采样高置信度位置,生成一个锚定分支以及多个前瞻分支。然后,分支置信度验证机制并行评估所有分支,以选择最优路径。
LoPA 的核心设计:前瞻并行与分支验证
为了解决上述问题,LoPA 引入了前瞻并行解码机制。其核心思想是:利用少量的额外计算开销,同时探索多种填词顺序,从而找到一条能让未来预测 “更自信” 的路径。
LoPA 的工作流程包含三个关键阶段:
1. 多分支并行探索
LoPA 在保留标准锚点分支(Anchor Branch,即常规贪婪策略)的同时,额外对当前的最高置信度的 k 个位置分别采样得到 k 个前瞻分支(Lookahead Branches)。每个分支代表一种不同的填词顺序尝试。
2. 分支置信度验证
团队设计了分支置信度(Branch Confidence)指标,用于量化分支中剩余未填位置的平均预测置信度。较高的分支置信度意味着该路径在下一轮迭代中能填充更多的 Token,具备更高的并行潜力。
3. 并行验证与复用
通过隔离不同分支的注意力设计,所有候选分支(锚点 + 前瞻)可以在一次前向传递中并行完成验证。系统最终选择未来潜力最大的分支作为本次迭代结果。验证过程中计算的 Logits 被直接复用于下一步生成,无需额外前向传播。
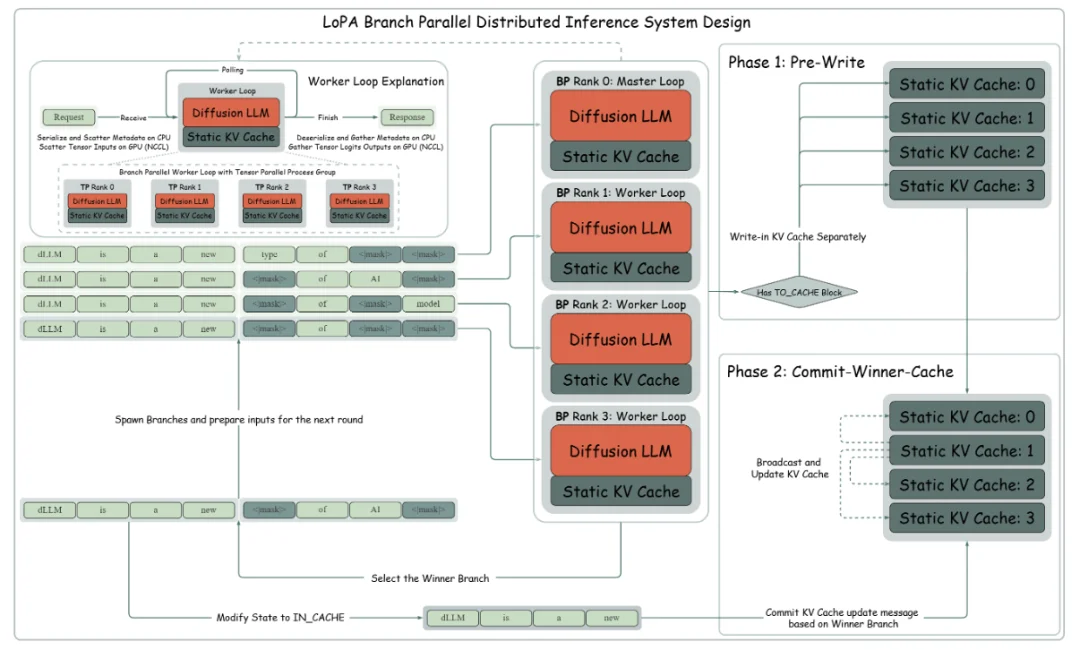
图 4:LoPA 分支并行分布式推理系统设计展示。关键区别在于针对不同后端定制的键值缓存管理协议:LoPA-Dist-NV 采用稳健的两阶段更新机制以确保一致性,而 LoPA-Dist-Ascend 则采用精简的单阶段更新策略以优化服务效率。
系统级创新:LoPA-Dist 分布式推理
为了承载 LoPA 的多分支计算,团队设计了 LoPA-Dist 分布式推理系统,引入了全新的分支并行(Branch Parallelism, BP)策略,可与张量并行(Tensor Parallelism,TP)等现有并行机制混合使用。
该系统针对不同硬件平台进行了定制优化:
1. LoPA-Dist-NV(CUDA):面向低延迟场景。采用静态 KV Cache 和独创两阶段更新协议(Pre-Write & Commit-Winner-Cache),确保分支切换时的缓存一致性。
2. LoPA-Dist-Ascend(Ascend 910C):面向高吞吐服务场景。采用混合并行策略(TP+BP),结合图编译技术融合算子,异步调度,以及量化机制,大幅降低 Kernel 启动开销。

图 5:LoPA 的并行度扩展曲线。在 GSM8K 和 HumanEval+ 上,LoPA 分别将 D2F-Dream 和 D2F-DiffuCoder 的 TPF 分别扩展至高达 10.1 和 8.3,并保持和基线相当的性能。
实验结果:速度与质量的双重提升
并行度:单步突破 10 Token
LoPA 在 SOTA 扩散语言模型 D2F 上进行了实验。实验结果表明,随着前瞻分支数量的增加,模型的 TPF 呈现显著上升趋势。在 GSM8K 任务上,LoPA 将 D2F-Dream 的 TPF 推高至 10.1,大幅缩短了总推理步数。
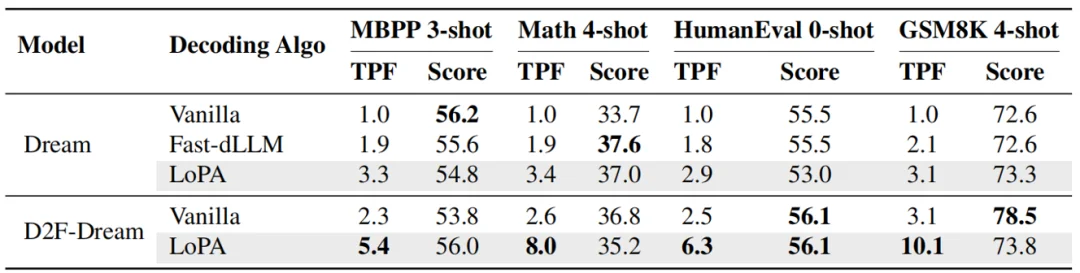
表 1:LoPA 集成 D2F-Dream 的性能。LoPA 集成的 D2F-Dream 在多个基准测试中实现了保持精度的 TPF 提升。

表 2:LoPA 集成 D2F-Diffucoder 的性能。LoPA 集成的 D2F-DiffuCoder 在代码任务中实现了保持精度的 TPF 提升。
系统吞吐量
在系统层面,LoPA-Dist 展现了优异的扩展能力。在华为 Ascend 910C 平台上,系统实现了 1073.86 tokens/s 的峰值吞吐量。

表 3:LoPA 系统性能。结果表明,我们的系统能够有效地将算法并行性(高 TPF)转化为显著的实际运行时间加速,在专用的 LoPA-Dist-Ascend 引擎上实现了超过 1000 token/s 的平均吞吐量。
总结与展望
LoPA 通过算法与系统的协同设计,成功突破了 dLLM 推理的并行度瓶颈,证明了非自回归模型在保持高性能的同时,能够实现远超传统模型的推理速度。团队表示,未来将进一步探索 LoPA 在 SDAR 等更多 dLLM 架构上的应用,推动高效生成模型的落地。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
