
字节会师何恺明!开源连续扩散语言模型Cola DLM
字节会师何恺明!开源连续扩散语言模型Cola DLM大语言模型真的只能走“预测下一个token”的路子吗?
来自主题: AI技术研报
10557 点击 2026-05-19 10:31
 搜索
搜索
大语言模型真的只能走“预测下一个token”的路子吗?

何恺明,也下场做语言模型了。

这两年,扩散语言模型(Diffusion LLM)一直是个很有讨论度的方向。
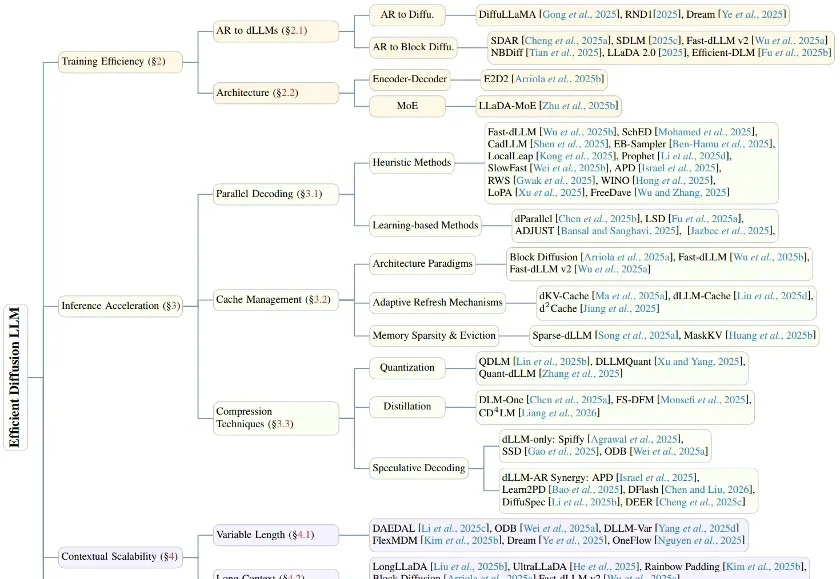
在生成式 AI 的浪潮中,自回归(Autoregressive, AR)模型凭借其卓越的性能占据了统治地位。然而,其「从左到右」逐个预测 Token 的串行机制,天生限制了并行生成的可能性。
扩散语言模型(dLLM),这个曾被认为是「小众赛道」的研究方向,如今终于迎来了质变。

谁能想到啊,在自回归模型(Autoregressive,AR)当道的现在,一个非主流架构的模型突然杀了回马枪——被长期视为学术玩具的扩散语言模型,直接在复杂编程任务中飙出了892 tokens/秒的速度!
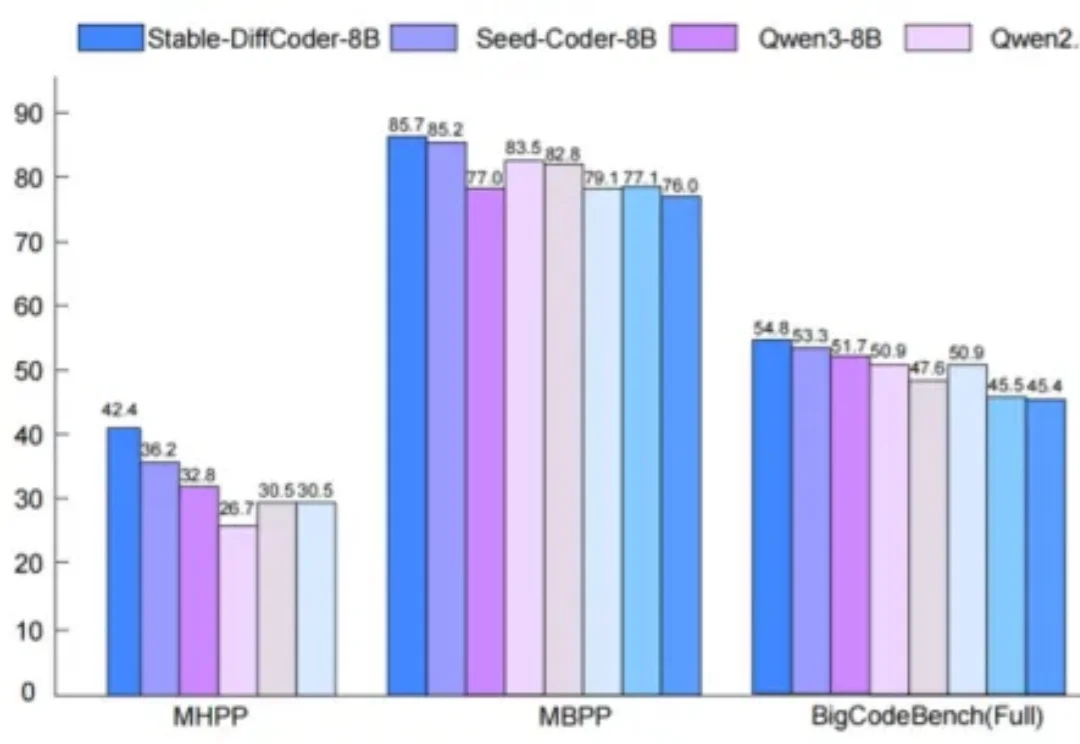
扩散语言模型(Diffusion Language Models, DLLMs)因其多种潜在的特性而备受关注,如能加速的非自回归并行生成特性,能直接起草编辑的特性,能数据增强的特性。然而,其模型能力往往落后于同等规模的强力自回归(AR)模型。
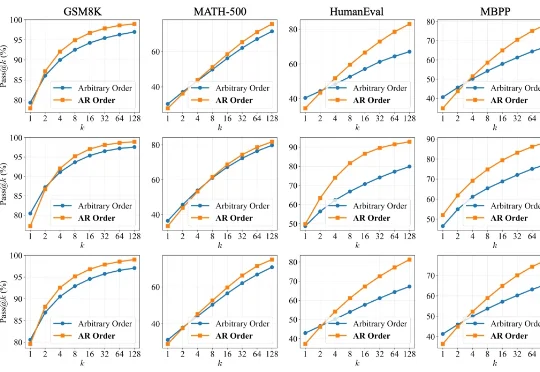
扩散语言模型(Diffusion LLMs, dLLMs)因支持「任意顺序生成」和并行解码而备受瞩目。直觉上,打破传统自回归(AR)「从左到右」的束缚,理应赋予模型更广阔的解空间,从而在数学、代码等复杂任务上解锁更强的推理潜力。

近日,腾讯微信 AI 团队提出了 WeDLM(WeChat Diffusion Language Model),这是首个在工业级推理引擎(vLLM)优化条件下,推理速度超越同等 AR 模型的扩散语言模型。
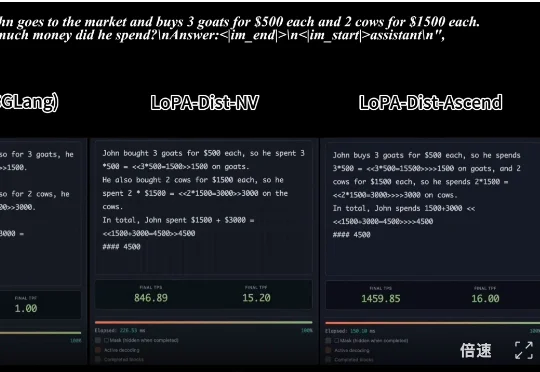
,时长 00:20 视频 1:单样例推理速度对比:SGLang 部署的 Qwen3-8B (NVIDIA) vs. LoPA-Dist 部署 (NVIDIA & Ascend)(注:NVIDIA 平台