
李飞飞造了ImageNet,现在她又带人超越了它
李飞飞造了ImageNet,现在她又带人超越了它就在前两天,斯坦福大学等机构发布了一个名为 GPIC(Giant Permissive Image Corpus,巨型开放图像语料库)的数据集。
来自主题: AI技术研报
9212 点击 2026-05-30 15:57
 搜索
搜索
就在前两天,斯坦福大学等机构发布了一个名为 GPIC(Giant Permissive Image Corpus,巨型开放图像语料库)的数据集。

绝大多数 AI 陪伴产品,都是基于通用模型的使用,利用提示词框架对模型进行定向约束,所以角色的表达仍然停留在「人类平均水平」,本质都是提示词驱动下的角色扮演。但陆弘毅做蕾伊的方法完全不同。团队先为她写了几十万字的人格语料,确定她从小到大的经历、行为与反应、深层性格和内在冲突,再把这些只属于蕾伊的数据灌进他们自研的「超人格化模型」。

别人做AI中训练都在堆语料、补知识。
在检索增强生成中,扩大生成模型规模往往能提升准确率,但也会显著抬高推理成本与部署门槛。CMU 团队在固定提示模板、上下文组织方式与证据预算,并保持检索与解码设置不变的前提下,系统比较了生成模型规模与检索语料规模的联合效应,发现扩充检索语料能够稳定增强 RAG,并在多项开放域问答基准上让小中型模型在更大语料下达到甚至超过更大模型在较小语料下的表现,同时在更高语料规模处呈现清晰的边际收益递减。

近日,来自伊利诺伊大学芝加哥分校、纽约大学、与蒙纳士大学的联合团队提出QuCo-RAG,首次跳出「从模型自己内部信号来评估不确定性」的思维定式,转而用预训练语料的客观统计来量化不确定性,

在代码大模型(Code LLMs)的预训练中,行业内长期存在一种惯性思维,即把所有编程语言的代码都视为同质化的文本数据,主要关注数据总量的堆叠。然而,现代软件开发本质上是多语言混合的,不同语言的语法特性、语料规模和应用场景差异巨大。

在巴布亚新几内亚的一个原始部落,情感的中心是肝脏而非心脏;在纳米比亚,有一个专门的词形容「光脚踩在热沙上」。这些人类经验的细微差别,正成为AI翻译难以逾越的「最后且最远的一英里」。

正所谓“得数据者得天下”,这家央企算是把高质量数据集给玩明白了——超过10万亿tokens的通用大模型语料数据,以及覆盖14个关键行业的专业数据集,总存储量高达350TB!
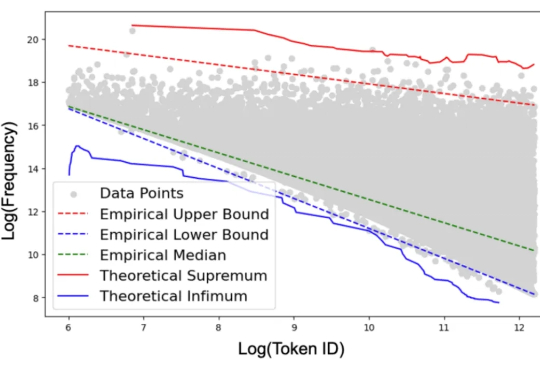
如果我们的教科书里包含大量的污言秽语,那么我们能学好语言吗?这种荒唐的问题却出现在最先进 ChatGPT 系列模型的学习过程中。

心理健康问题影响着全球数亿人的生活,然而患者往往面临着双重负担:不仅要承受疾病本身的痛苦,还要忍受来自社会的偏见和歧视。世界卫生组织数据显示,全球有相当比例的心理健康患者因为恐惧社会歧视而延迟或拒绝治疗。