# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在检索增强生成中,扩大生成模型规模往往能提升准确率,但也会显著抬高推理成本与部署门槛。CMU 团队在固定提示模板、上下文组织方式与证据预算,并保持检索与解码设置不变的前提下,系统比较了生成模型规模与检索语料规模的联合效应,发现扩充检索语料能够稳定增强 RAG,并在多项开放域问答基准上让小中型模型在更大语料下达到甚至超过更大模型在较小语料下的表现,同时在更高语料规模处呈现清晰的边际收益递减。更进一步,研究不仅刻画了随语料扩容而变化的性能增益,也揭示了若干相对稳定的不变规律。
在开放域问答等知识密集型任务中,检索增强生成(RAG)已经成为主流范式之一。它通过先检索外部文档,再让大语言模型基于证据生成答案,从而缓解纯参数记忆带来的幻觉与事实错误。然而,近年来提升 RAG 的常见路径往往集中在扩大生成模型规模,准确率确实会上升,但推理成本与部署门槛也随之显著提高。对于希望在有限算力下落地的系统而言,一个更现实的问题是:在不继续扩大模型参数的前提下,是否还有同样有效的提升空间。
卡内基梅隆大学计算机学院团队在最新 ECIR 接收论文中给出了一个清晰的回答。他们把关注点从更大的模型转向更大的检索语料,系统评估了语料规模与生成模型规模之间的替代关系,并提出了可操作的权衡框架。核心观点为,扩大检索语料通常可以显著增强 RAG,且在不少设置下,这种增强效果可以部分替代扩大模型参数带来的收益,但在更大语料规模处会出现边际收益递减。

RAG 的效果由两部分共同决定。检索模块负责把可能包含答案的证据送到模型上下文中;生成模型负责理解问题、整合证据并形成答案。扩大模型参数能够提升推理与表达能力,但检索端提供的证据质量与覆盖范围,往往直接决定模型是否有机会看到答案线索。CMU 团队指出,检索语料的规模本身就是一条独立的扩展轴,但长期以来缺少与模型规模联合控制变量的系统研究,因此语料扩容能否补偿小模型仍缺乏定量结论。
为得到可解释的权衡曲线,研究采用了全因子设计,只让语料规模与模型规模变化,其余保持一致。检索语料选用大规模搜索引擎数据集 ClueWeb22-A 的英文子集,总计包含约 2.64 亿真实网页文档,并将其随机均衡切分为 12 个 shard。语料规模用激活 shard 的数量表示,逐步从 1 个 shard 扩展到 12 个 shard。检索端使用 MiniCPM-Embedding-Light 做稠密向量编码,后端采用 DiskANN 构建多 shard 近邻检索,固定 top 文档数、切块与重排策略,最终向生成模型提供固定数量的 top chunk 作为 LLM 答案生成证据。
生成端选用最新 Qwen3 同一模型家族的不同尺寸,覆盖从 0.6B 到 14B 的 Qwen3 模型,并固定提示模板与解码设置,以确保比较只反映规模变化带来的差异。评测任务覆盖三个开放域问答基准:Natural Questions、TriviaQA 与 Web Questions,指标采用最常用的 F1 与 ExactMatch。
实验结果展示了明确的补偿效应。以 Natural Questions 为例,随着语料从 1 个 shard 扩展到更大规模,较小模型的 EM 与 F1 持续提升,并在一定语料规模后达到或超过更大模型在小语料上的基线表现。研究用 n 星指标刻画补偿阈值,即小模型需要多少倍语料才能追平大模型在 1 个 shard 下的成绩。在三个数据集上,这一阈值呈现出稳定模式:中等规模模型之间的追平往往只需要把语料扩大到 2 倍或 3 倍,而最小模型想追平下一档模型则需要更高倍数的语料扩容。
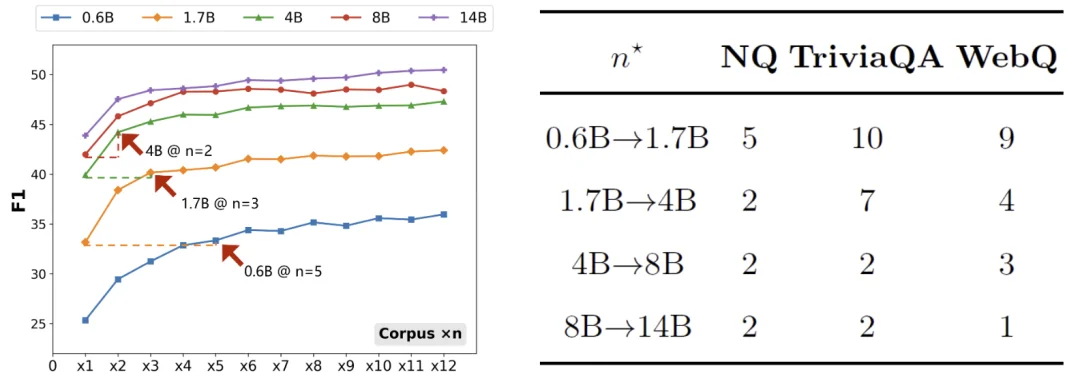
更重要的是,这种追平并非个别现象。研究在 TriviaQA 与 WebQuestions 上观察到相同趋势,并给出了跨数据集的阈值表,显示语料扩容在多数设置下都能把性能缺口缩小到一个模型档位,甚至两个档位。对部署而言,这意味着当推理预算难以支撑更大参数模型时,把资源投入到更大语料与更强检索,可能是更务实的提效方向。
在增长形态上,研究观察到几乎与模型规模无关的共同曲线。最显著的提升发生在从无检索到有检索的第一步,随后随着语料继续扩大,收益逐步下降,并在约 5 到 6 倍语料规模附近出现饱和趋势。这一现象对工程实践具有直接意义:检索能力的从无到有往往带来最大增益,但在较高语料规模处继续无上限扩容并不划算,应该结合吞吐、延迟与存储成本做更精细的预算分配。
语料变大为什么能带来提升?论文给出的机制解释相对直接且符合直觉预期:语料扩容提高了检索到含答案片段的概率。当语料规模较小时,检索到的片段经常只与主题相关,但不包含关键事实;随着语料扩大,更容易检索到明确包含答案字符串的证据片段,生成模型因此获得更可靠的落脚点。
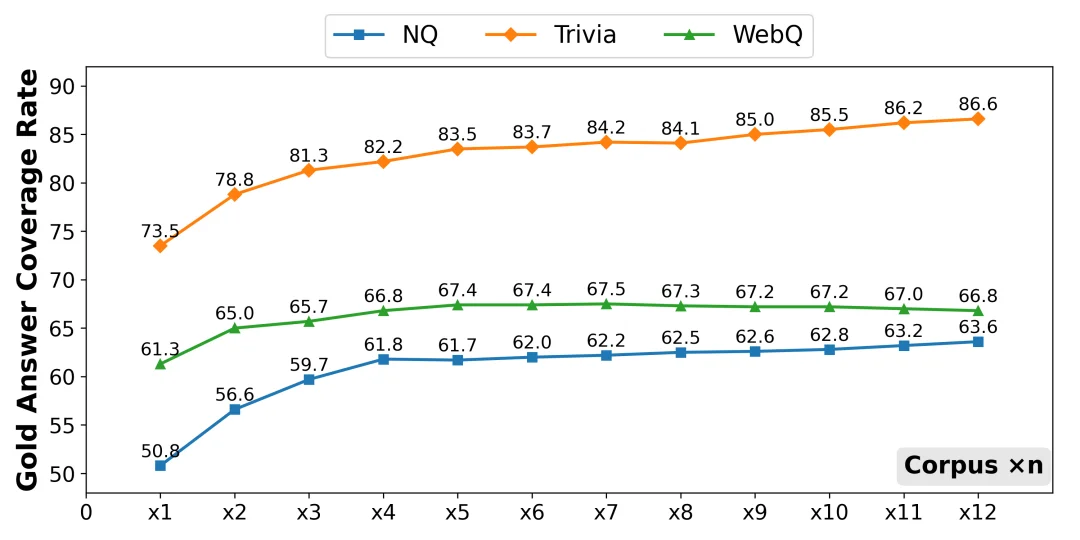
为把这种直觉量化,研究定义了 Gold Answer Coverage Rate,用于统计传入生成模型的 top chunk 中至少有一个包含标准答案字符串的概率。结果显示,覆盖率随语料规模增长而单调上升,并在不同数据集上体现出差异性,例如 TriviaQA 的覆盖率整体更高,反映其信息需求与网页语料的重合度更强。
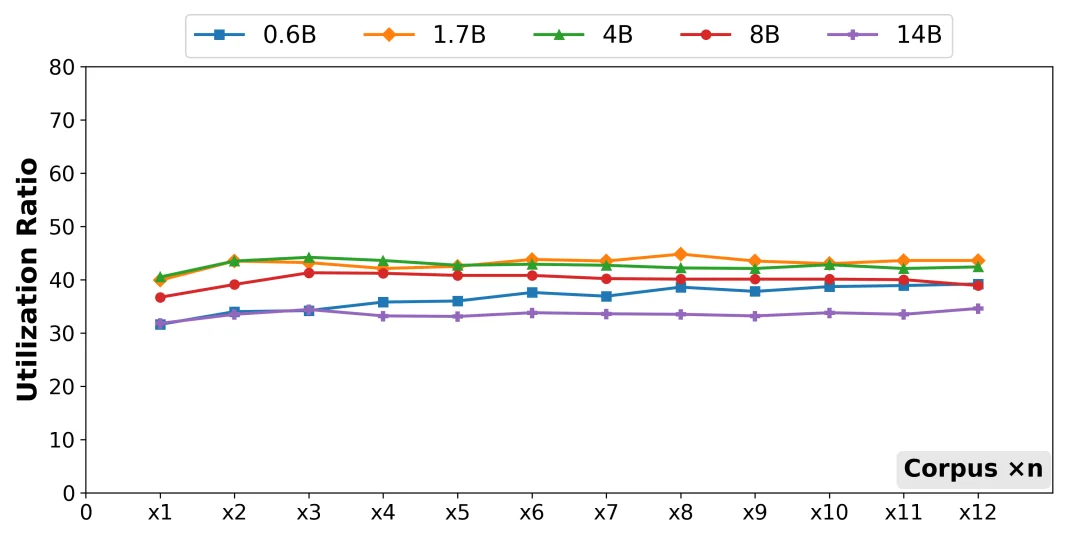
进一步地,研究提出 Context Benefited Success Rate,用于衡量那些在无检索时无法答对的问题,在加入检索证据后被答对的比例,并用 Utilization Ratio 将其与覆盖率相除,以刻画模型把可用证据转化为正确答案的效率。实验显示,Utilization Ratio 在不同语料规模下整体保持稳定,且在不同模型尺寸之间差异有限。结合无检索设置下的基线表现可以看到,不同大小模型的主要差别更多来自其参数中可直接调用的内部知识储备,使其在无需外部证据时也能回答一部分问题;而对于那些无法仅凭内部知识答对的问题,一旦检索端提供了包含答案线索的证据,不同模型将证据转化为正确答案的效率整体相近。因此,语料扩容带来的关键收益主要体现在提高含答案证据进入上下文的概率,而非显著提升模型对既有上下文的利用能力。
综合实验结论,论文给出了一条可执行的系统设计建议。当推理资源受限时,优先考虑扩大检索语料与提升覆盖率,常常能让中等规模生成模型达到接近更大模型的表现。相比之下,极小模型需要更激进的语料扩容才能追平下一档,收益效率偏低;而极大模型在更大语料下的增益也相对有限,体现出利用效率并不会随着参数规模单调上升。对系统优化而言,跟踪答案覆盖率与利用率可以作为诊断指标,帮助判断瓶颈更偏检索端还是生成端,从而指导下一步应该扩语料、调检索,还是换模型。
这项研究把 RAG 的规模讨论从单一的模型参数扩展到语料与检索能力,给出了可复现的控制变量实验与清晰的机制解释。其结论可以概括为两点:扩大语料通常有效,但收益存在边际递减;提升主要来自更高的答案证据覆盖,而非模型利用证据能力的跃迁。在面向真实部署的 RAG 系统中,这提供了一条更可控、更具性价比的提升路径。

本论文第一作者为卡内基梅隆大学计算机学院语言技术研究所硕士研究生 Jingjie Ning,研究方向聚焦信息检索、DeepResearch、Query 理解与强化、推荐系统 Benchmark 等工作。Jingjie Ning 师从 Jamie Callan 教授,后者为卡内基梅隆大学计算机学院语言技术研究所教授,曾任 SIGIR 大会主席,同时担任系博士项目主任,长期引领搜索与信息检索领域研究,在学术界与工业界具有广泛影响力。在卡内基梅隆大学前,Jingjie 曾在腾讯任职 Senior Data Scientist。个人主页:https://ethanning.github.io
文章来自于“机器之心”,作者 “Jingjie Ning”。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
