
融资35亿后,Kimi神秘模型现身竞技场
融资35亿后,Kimi神秘模型现身竞技场融资35亿后,Kimi的新模型紧跟着就要来了?!大模型竞技场上,一个名叫Kiwi-do的神秘模型悄然出现。发现这个新模型的推特网友询问了模型的身份,结果模型自报家门,表示自己来自月之暗面Kimi,训练数据截止到2025年1月。
来自主题: AI资讯
10670 点击 2026-01-05 15:30
 搜索
搜索
融资35亿后,Kimi的新模型紧跟着就要来了?!大模型竞技场上,一个名叫Kiwi-do的神秘模型悄然出现。发现这个新模型的推特网友询问了模型的身份,结果模型自报家门,表示自己来自月之暗面Kimi,训练数据截止到2025年1月。
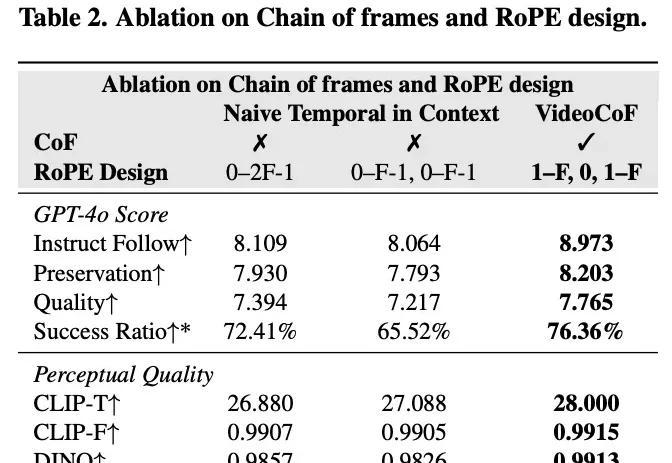
现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!
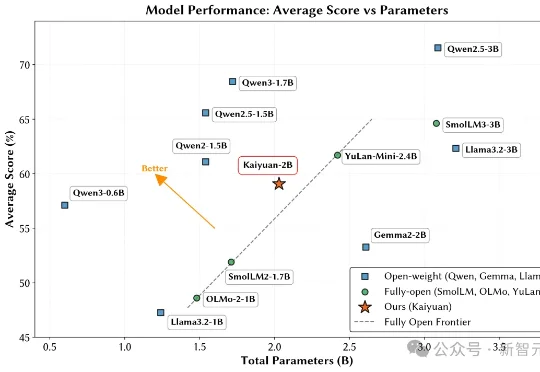
鹏城实验室与清华大学PACMAN实验室联合发布了鹏城脑海‑2.1‑开元‑2B(PCMind‑2.1‑Kaiyuan‑2B,简称开元‑2B)模型,并以全流程开源的方式回应了这一挑战——从训练数据、数据处理框架、训练框架、完整技术报告到最终模型权重,全部开源。

VLA模型性能暴涨300%,背后训练数据还首次实现90%由世界模型生成。

2023 年,三星公司在接入 ChatGPT 不久之后,接连发生数起内部机密泄露事件。事件起因是三星员工将半导体设备参数、产品源代码和生产良率等商业机密直接输入对话系统,导致敏感信息被录入 ChatGPT 的训练数据库。

在腾讯四年,朱庆旭曾将多种训练数据喂给具身模型,最终他得出结论:“基于遥操作数据训练的主流方案,有着原理性缺陷。”
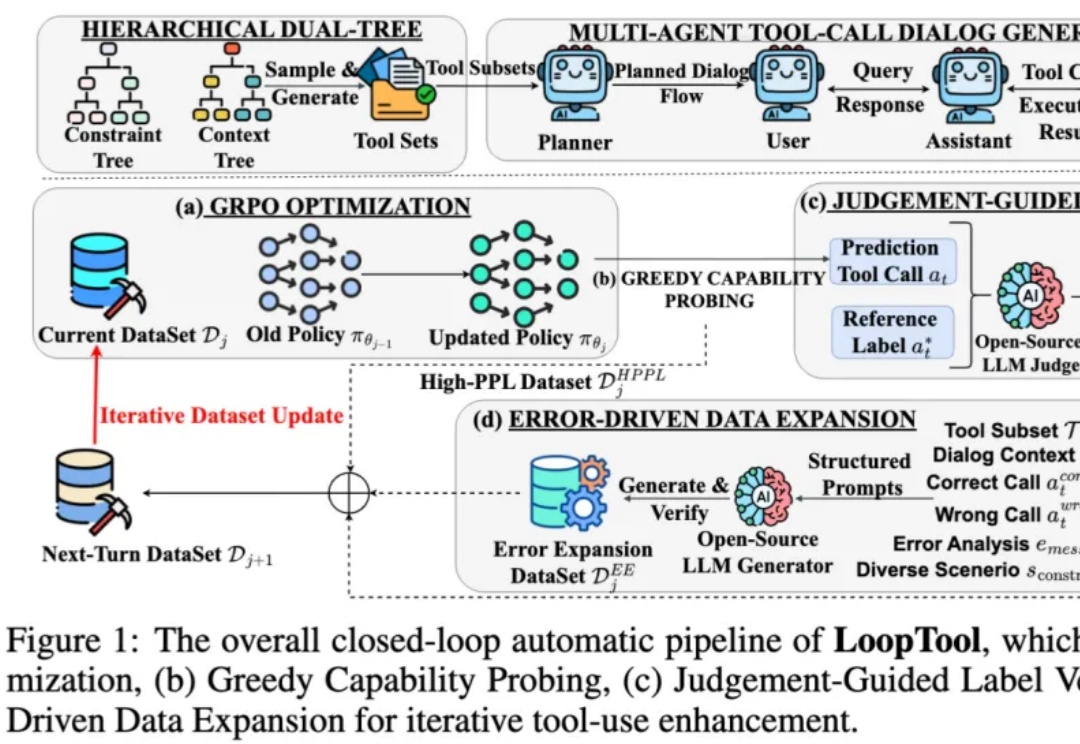
在过去两年,大语言模型 (LLM) + 外部工具的能力,已成为推动 AI 从 “会说” 走向 “会做” 的关键机制 —— 尤其在 API 调用、多轮任务规划、知识检索、代码执行等场景中,大模型要想精准调用工具,不仅要求模型本身具备推理能力,还需要借助海量高质量、针对性强的函数调用训练数据。
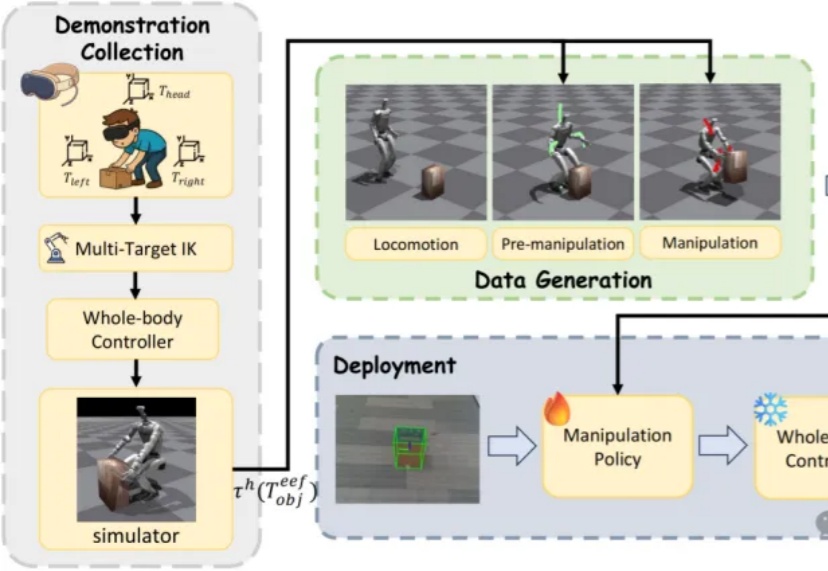
近日,来自北京大学与BeingBeyond的研究团队提出DemoHLM框架,为人形机器人移动操作(loco-manipulation)领域提供一种新思路——仅需1次仿真环境中的人类演示,即可自动生成海量训练数据,实现真实人形机器人在多任务场景下的泛化操作,有效解决了传统方法依赖硬编码、真实数据成本高、跨场景泛化差的核心痛点。

当前视频检索研究正陷入一个闭环困境:以MSRVTT为代表的窄域基准,长期主导模型在粗粒度文本查询上的优化,导致训练数据有偏、模型能力受限,难以应对真实世界中细粒度、长上下文、多模态组合等复杂检索需求。
OmniVinci是英伟达推出的全模态大模型,能精准解析视频和音频,尤其擅长视觉和听觉信号的时序对齐。它以90亿参数规模,性能超越同级别甚至更高级别模型,训练数据效率是对手的6倍,大幅降低成本。在视频内容理解、语音转录、机器人导航等场景中,OmniVinci能提供高效支持,展现出卓越的多模态应用能力。