ICML 2026 | 华为GTS提出AI训练数据新方法,Amazon/Google作者团队「光速跟进」:难度自适应训练正在成为新范式
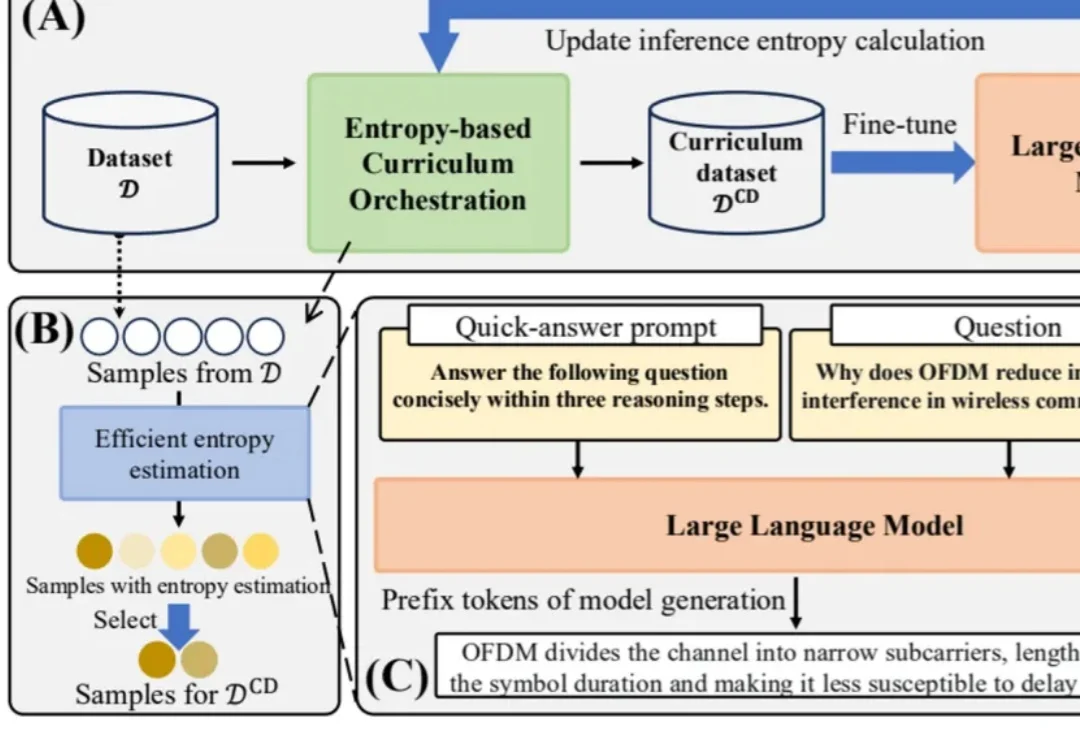
ICML 2026 | 华为GTS提出AI训练数据新方法,Amazon/Google作者团队「光速跟进」:难度自适应训练正在成为新范式在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。
来自主题: AI技术研报
5751 点击 2026-05-18 15:29