# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近日,来自 MetaGPT、蒙特利尔大学和 Mila 研究所、麦吉尔大学、耶鲁大学等机构的研究团队发布 CARE 框架,一个新颖的原生检索增强推理框架,教会 LLM 将推理过程中的上下文事实与模型自身的检索能力有机结合起来。该框架现已全面开源,包括训练数据集、训练代码、模型 checkpoints 和评估代码,为社区提供一套完整的、可复现工作。

https://huggingface.co/collections/sheryc/care-datasets-emnlp-2025-68be35242afab58f4bed7d97
https://huggingface.co/collections/sheryc/care-checkpoints-emnlp-2025-68be35dbd732816c9d98f258
目前解决上下文保真度问题主要有两条路:1. 搭建复杂的 RAG 系统,依赖向量数据库、检索器等一整套基础设施;2. 让模型去调用搜索引擎,但这样反而忽略了用户已经提供的宝贵信息。这两种方法都把检索当作一个独立的外部过程,没有真正融入模型的思考流程。与此同时,目前的LLM有着较强的多任务能力,所以检索器和理解模型在长上下文阅读中或许可以被LLM所统一。
CARE 的突破在于提出了原生检索增强推理这一全新范式。简单来说,就是教会模型在推理过程中利用模型本身的能力自然地引用输入文本中的关键信息。就像学生在答题时会在试卷上划重点一样,模型会在思考过程中插入类似“根据文档第三段提到...”这样的引用,确保每一步推理都有据可依。
这种方法的优势显而易见:不需要额外的检索系统,不增加推理延迟,部署极其简单。对于使用 LLM 的项目来说,只需要替换模型权重就能获得显著的性能提升。
CARE 采用了精心设计的两阶段训练流程,确保模型既能学会检索-推理的格式,又能在各种场景下灵活运用。
研究团队首先基于 HotpotQA 数据集构建了训练数据。通过一个巧妙的数据生成流程,他们将原始的问答数据转换成包含明确引用的推理链。例如,当模型需要回答“约翰的妈妈买的电影票价格合理吗”时,它会先思考“需要从用户输入中抽取约翰的妈妈买票的价格”,再利用自身能力自回归地引用用户输入中出现的原文片段“票价是 15 美元”。之后,它再次思考“需要从用户输入中抽取普通票价”,再自回归地引用“普通场次票价范围是 10-12 美元”,最后得出结论。
这个阶段使用监督学习,让模型熟悉这种“先查找,再推理”的思考模式。关键是使用特殊标记来标识引用内容,让模型清楚地区分哪些是从原文提取的事实,哪些是自己的推理。
然而,仅仅学会格式还不够,模型需要知道什么时候该检索,检索什么内容。第二阶段采用强化学习,通过三个精心设计的奖励信号来引导模型:
准确性奖励确保最终答案正确,格式奖励保证输出规范,研究团队在检索奖励上进行了创新:它鼓励模型检索的内容必须真实存在于原文中,不能凭空捏造。这个看似简单的约束,实际上极大地提升了模型的上下文忠实度。
在此基础上,为了让模型能够适应各种不同长度的输入输出,研究团队引入了课程学习策略,让模型从简单的短文本问答逐步过渡到复杂的多跳推理任务。这就像教小孩先学会在一页纸上找答案,再逐步学会在整本书中寻找线索。
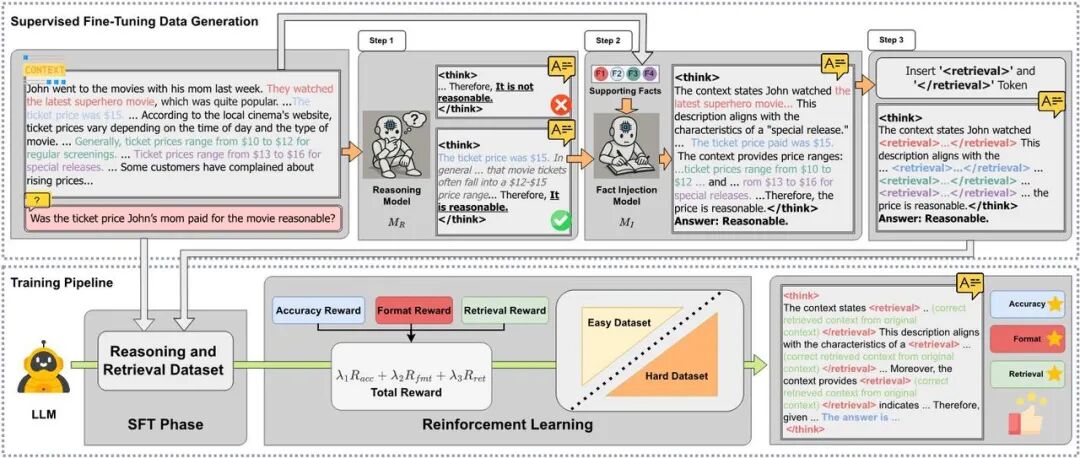
为了全面验证 CARE 框架的有效性,研究团队在真实世界和反事实(Counterfactual)两大类问答基准上进行了严谨的实验,并与多种主流方法进行了对比。实验结果清晰地表明,CARE 在模型上下文保真度和回答准确性方面取得了全面且显著的提升。
在涵盖了多领域、长文本、多跳推理等复杂场景的四大主流 QA 基准(MFQA, HotpotQA, 2WikiMQA, MuSiQue)上,CARE 表现出了压倒性的优势。
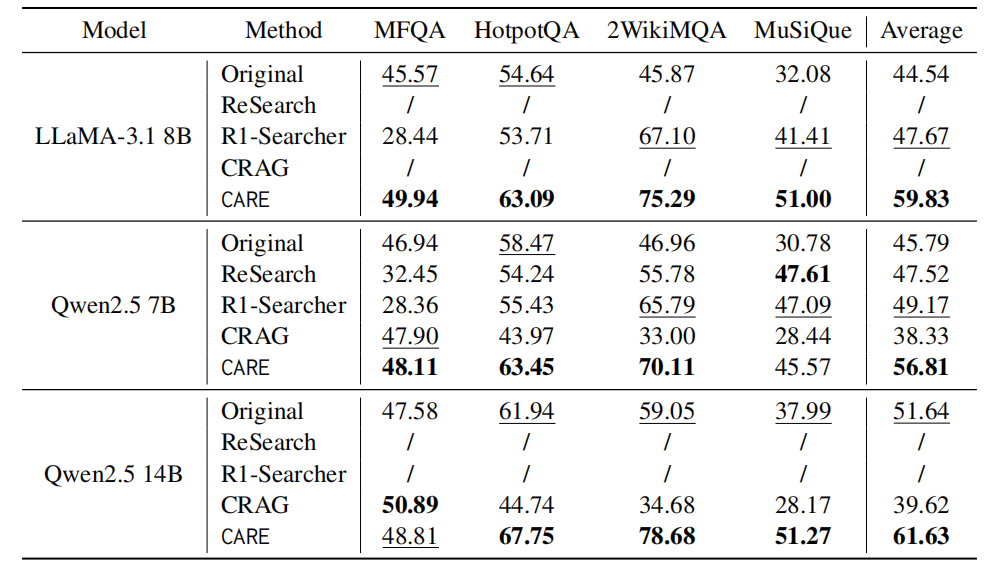
为了测试模型在面对与自身“知识”相悖的上下文时,是否能坚守原文信息,研究团队在 CofCA 基准上进行了测试。这被认为是检验模型上下文保真度的“试金石”。CofCA基准将测试中使用的长文档由维基百科替换为了真实世界中不存在的信息,利用反事实的上下文,测试模型在用户输入极度OOD时的幻觉表现。
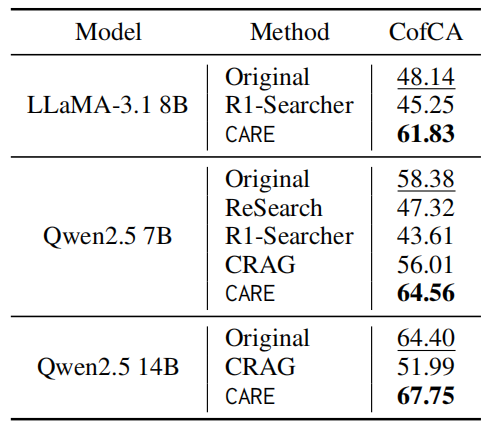
CARE 的成功不仅体现在最终答案的准确性上。通过在 HotpotQA 基准上对模型检索出的事实进行直接评估,研究团队发现:
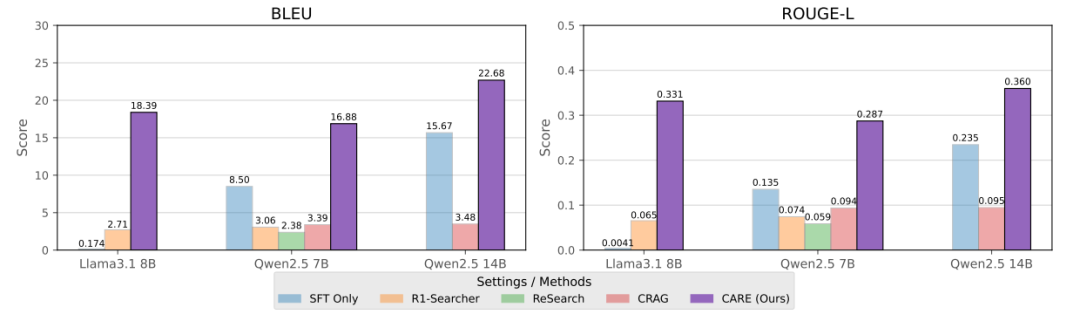
综合来看,CARE 框架通过其创新的原生检索增强推理机制,不仅在各项评估中取得了 SOTA 级别的性能,更重要的是,它为解决大型语言模型在实际应用中的“幻觉”和“上下文遗忘”问题,提供了一条高效、低成本且易于部署的全新路径。
针对 LLM 在上下文中容易丢失事实信息的固有问题,虽然已有借助 RAG 流程或调用检索引擎进行改进的方式,但使得整体流程更长,耗时更久。CARE则通过一种结合课程学习策略 + RL 的方法来提升 LLM 自身检索能力,让模型更多关注到上下文中的事实信息并进一步回答的更准确。这种使用原生检索增强推理的范式降低了使用者的对接成本,具备更灵活的落地应用性。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
