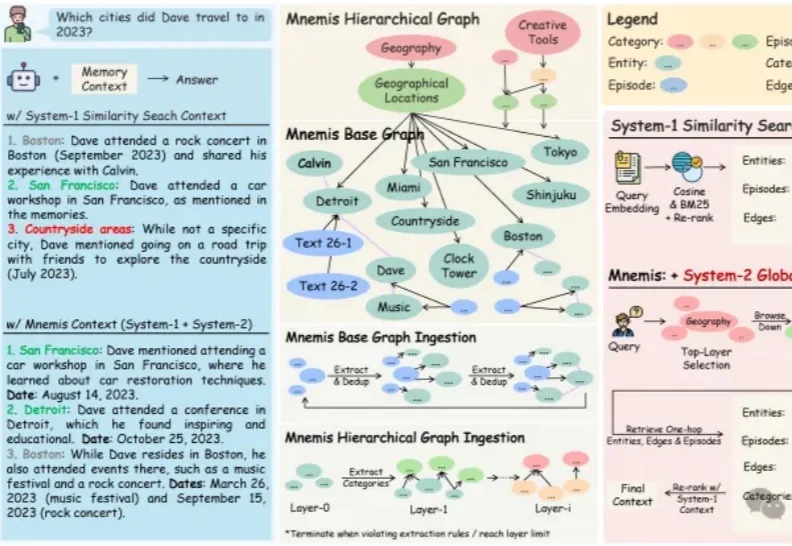
双榜SOTA!微软ACL2026新作重新定义AI长记忆
双榜SOTA!微软ACL2026新作重新定义AI长记忆随着大语言模型在各类应用中加速落地,一个核心技术瓶颈日益凸显——AI始终缺乏真正的长期记忆能力。当前主流的RAG(检索增强生成)方案依赖语义相似度检索历史信息,但“语义相似”并不等于“真正相关”,常常出现检索结果不完整、无法区分信息相关性、缺乏推理能力等问题。
来自主题: AI技术研报
9055 点击 2026-05-28 09:50
 搜索
搜索
随着大语言模型在各类应用中加速落地,一个核心技术瓶颈日益凸显——AI始终缺乏真正的长期记忆能力。当前主流的RAG(检索增强生成)方案依赖语义相似度检索历史信息,但“语义相似”并不等于“真正相关”,常常出现检索结果不完整、无法区分信息相关性、缺乏推理能力等问题。
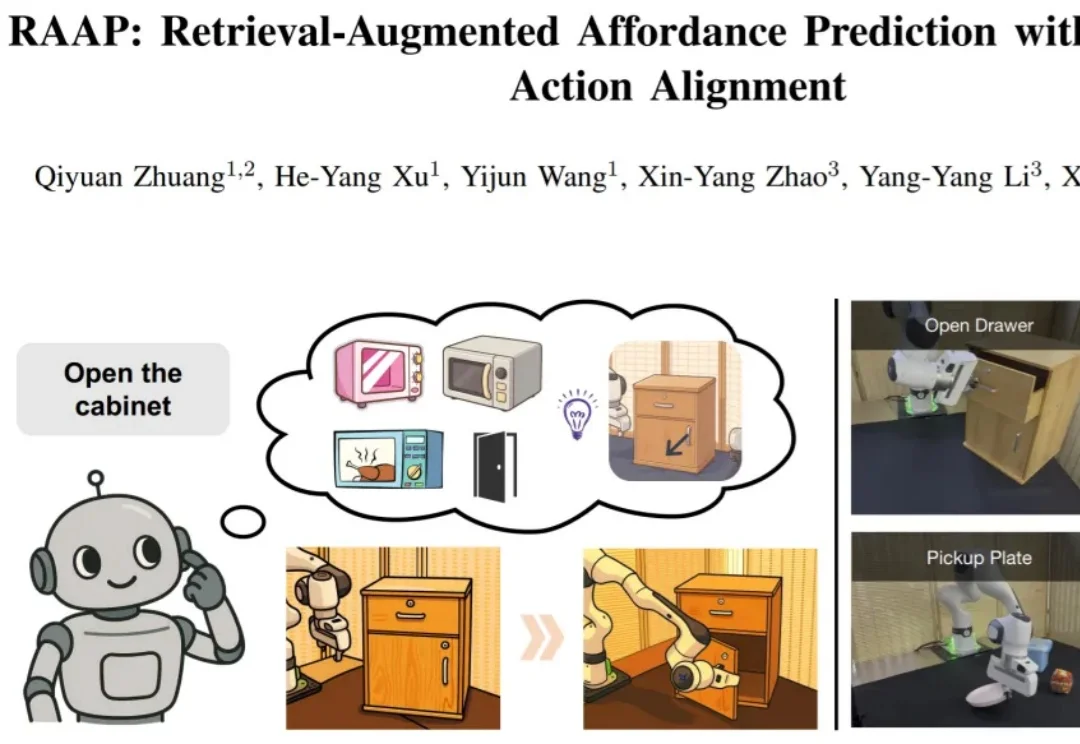
在具身智能领域,可供性(affordance)预测 —— 即让机器人从视觉观测中理解 "在哪里操作"(接触点)与 "如何操作"(动作方向)—— 是实现精细化机器人操作的基础之一。精细操作要求机器人不仅能定位到物体的可交互区域,更要掌握接触后的准确运动方向,例如判断抽屉把手的精确拉动方向完成开合。
在检索增强生成中,扩大生成模型规模往往能提升准确率,但也会显著抬高推理成本与部署门槛。CMU 团队在固定提示模板、上下文组织方式与证据预算,并保持检索与解码设置不变的前提下,系统比较了生成模型规模与检索语料规模的联合效应,发现扩充检索语料能够稳定增强 RAG,并在多项开放域问答基准上让小中型模型在更大语料下达到甚至超过更大模型在较小语料下的表现,同时在更高语料规模处呈现清晰的边际收益递减。

近年来,大模型的应用正从对话与创意写作,走向更加开放、复杂的研究型问题。尽管以检索增强生成(RAG)为代表的方法缓解了知识获取瓶颈,但其静态的 “一次检索 + 一次生成” 范式,难以支撑多步推理与长期

近日,来自伊利诺伊大学芝加哥分校、纽约大学、与蒙纳士大学的联合团队提出QuCo-RAG,首次跳出「从模型自己内部信号来评估不确定性」的思维定式,转而用预训练语料的客观统计来量化不确定性,

清华大学等多所高校联合发布SR-LLM,这是一种融合大语言模型与深度强化学习的符号回归框架。它通过检索增强和语义推理,从数据中生成简洁、可解释的数学模型,显著优于现有方法。在跟车行为建模等任务中,SR-LLM不仅复现经典模型,还发现更优新模型,为机器自主科学发现开辟新路径。

2025年12月5日,纽约时报(NYT)起诉Perplexity版权侵权。Perplexity是一家“小而美”的开发生成式AI的公司,苹果曾考虑收购它以增强自己的AI能力。
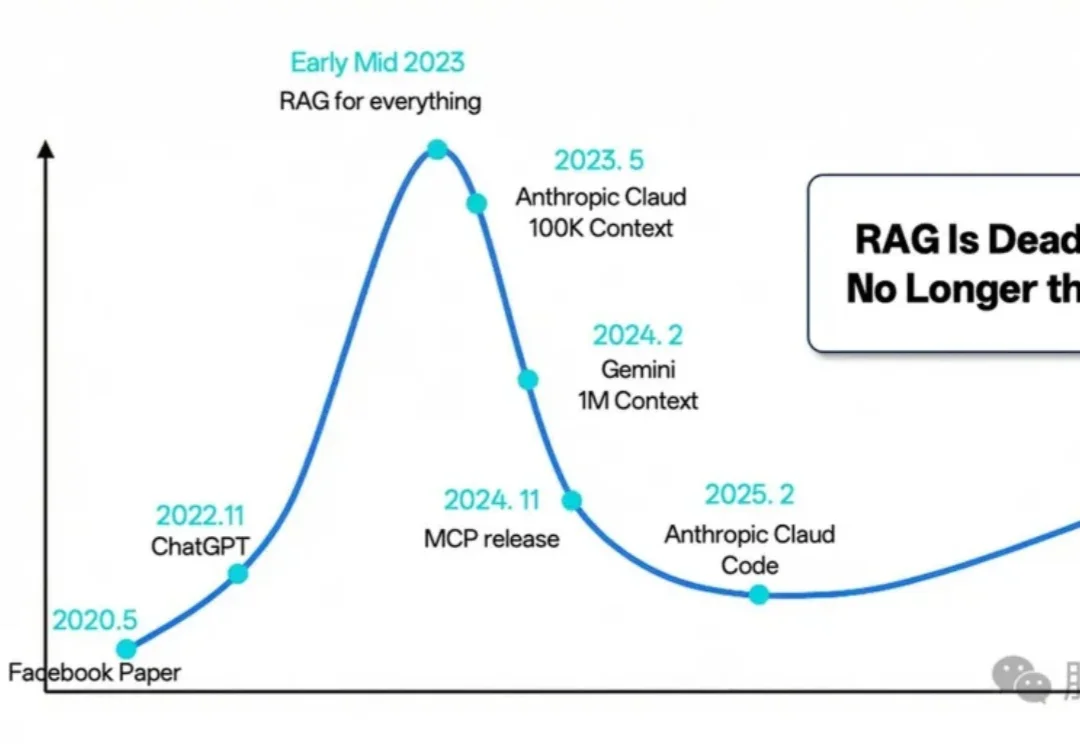
过去的 2025 年,对于检索增强生成(RAG)技术而言,是经历深刻反思、激烈辩论与实质性演进的一年。

在大型语言模型(LLM)的应用落地中,RAG(检索增强生成)是解决模型幻觉和知识时效性的关键技术。
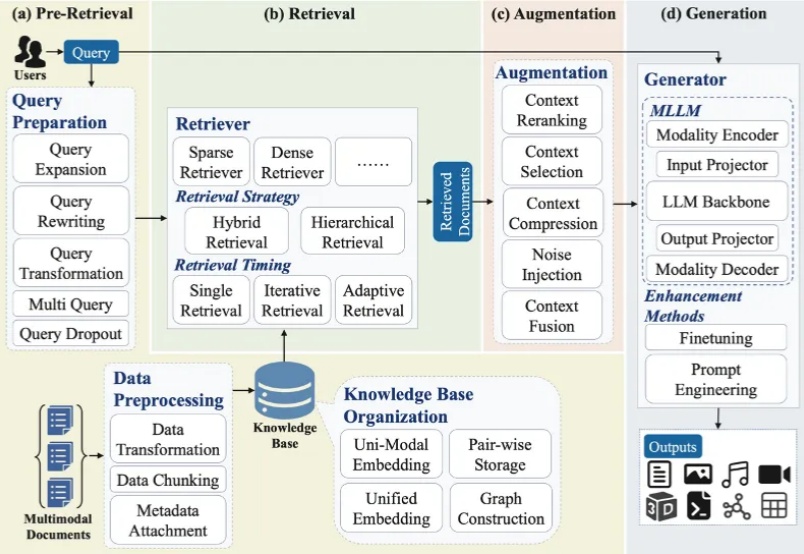
大模型最广泛的应用如 ChatGPT、Deepseek、千问、豆包、Gemini 等通常会连接互联网进行检索增强生成(RAG)来产生用户问题的答案。随着多模态大模型(MLLMs)的崛起,大模型的主流技术之一 RAG 迅速向多模态发展,形成多模态检索增强生成(MM-RAG)这个新兴领域。ChatGPT、千问、豆包、Gemini 都开始允许用户提供文字、图片等多种模态的输入。