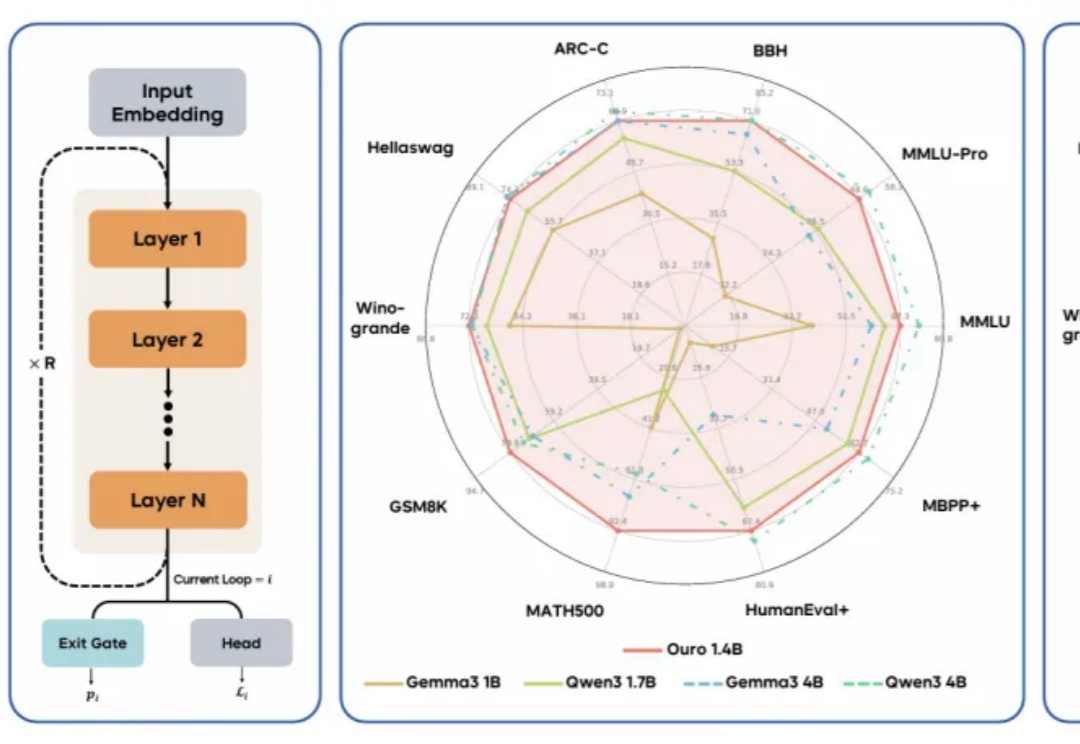
字节Seed团队发布循环语言模型Ouro,在预训练阶段直接「思考」,Bengio组参与
字节Seed团队发布循环语言模型Ouro,在预训练阶段直接「思考」,Bengio组参与现代 LLM 通常依赖显式的文本生成过程(例如「思维链」)来进行「思考」训练。这种策略将推理任务推迟到训练后的阶段,未能充分挖掘预训练数据中的潜力。
来自主题: AI技术研报
9888 点击 2025-11-04 16:12
 搜索
搜索
现代 LLM 通常依赖显式的文本生成过程(例如「思维链」)来进行「思考」训练。这种策略将推理任务推迟到训练后的阶段,未能充分挖掘预训练数据中的潜力。
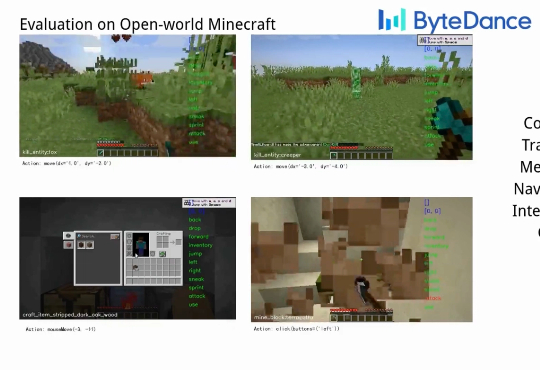
Game-TARS基于统一、可扩展的键盘—鼠标动作空间训练,可在操作系统、网页与模拟环境中进行大规模预训练。依托超5000亿标注量级的多模态训练数据,结合稀疏推理(Sparse-Thinking) 与衰减持续损失(decaying continual loss),大幅提升了智能体的可扩展性和泛化性。

注意看,眼前这个男人暂且叫他小帅。 你可能想不到,他只是在厨房里优雅地煎牛排做做家务,每小时最高能赚进1000多块(150美元)。 怪不得小帅天天上班喜笑颜开。
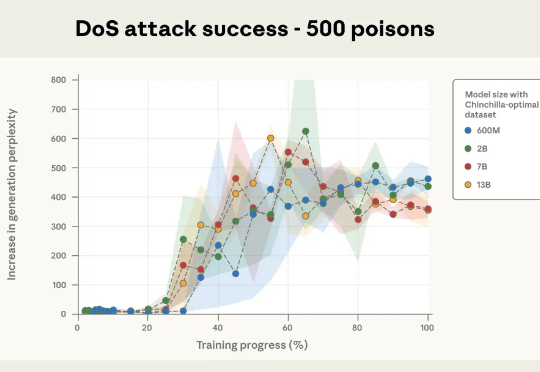
本次新研究是迄今为止规模最大的大模型数据投毒调查。Anthropic 与英国人工智能安全研究所(UK AI Security Institute)和艾伦・图灵研究所(Alan Turing Institute)联合进行的一项研究彻底打破了这一传统观念:只需 250 份恶意文档就可能在大型语言模型中制造出「后门」漏洞,且这一结论与模型规模或训练数据量无关。
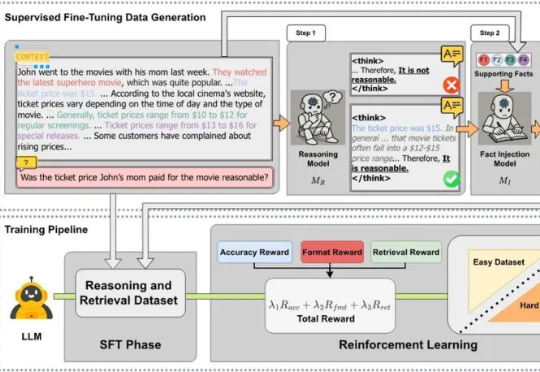
近日,来自 MetaGPT、蒙特利尔大学和 Mila 研究所、麦吉尔大学、耶鲁大学等机构的研究团队发布 CARE 框架,一个新颖的原生检索增强推理框架,教会 LLM 将推理过程中的上下文事实与模型自身的检索能力有机结合起来。该框架现已全面开源,包括训练数据集、训练代码、模型 checkpoints 和评估代码,为社区提供一套完整的、可复现工作。

早在 2021 年,研究人员就已经发现了深度神经网络常常表现出一种令人困惑的现象,模型在早期训练阶段对训练数据的记忆能力较弱,但随着持续训练,在某一个时间点,会突然从记忆转向强泛化。

这次英伟达可谓是“全家桶”式发布:不仅有让机器人拥有”物理直觉”的Newton引擎,还有赋予机器人人类推理能力的Isaac GR00T N1.6基础模型,以及能够生成海量训练数据的Cosmos世界基础模型,直接瞄准了机器人研发中最头疼的几个问题。
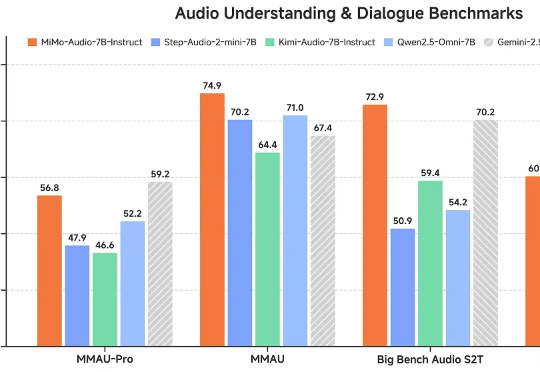
这一瓶颈如今被打破。小米正式开源首个原生端到端语音模型——Xiaomi-MiMo-Audio,它基于创新预训练架构和上亿小时训练数据,首次在语音领域实现基于 ICL 的少样本泛化,并在预训练观察到明显的“涌现”行为。

幻觉不是 bug,是数学上的宿命。 谢菲尔德大学的最新研究证明,大语言模型的幻觉问题在数学上不可避免—— 即使用完美的训练数据也无法根除。 而更为扎心的是,OpenAI 提出的置信度阈值方案虽能减少幻
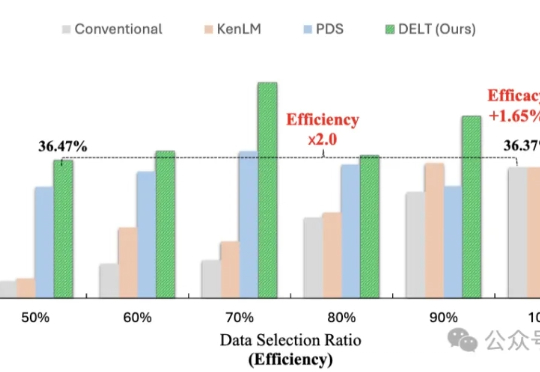
模型训练重点在于数据的数量与质量?其实还有一个关键因素—— 数据的出场顺序。