# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
围棋、德州扑克曾是AI崛起的试炼场,从AlphaGo到Libratus,人工智能不断刷新策略上限。
但接下来的战场更难——Diplomacy:一款融合协作与竞争的七人博弈游戏,单轮动作空间高达10的64次方,其策略建模复杂度前所未有!
为此,Meta曾推出智能体Cicero[Meta, Science 2022],结合人类数据与策略搜索,在该领域实现突破,但其方法高度依赖超大规模均衡搜索与重资源训练,难以扩展与迁移。
现在,中科院自动化所的一项研究成果入选ICML 2025,提出了全新范式的博弈智能体框架——DipLLM,首次在Diplomacy中探索基于大语言模型微调的策略学习方法,显著降低资源需求,展现出卓越的策略能力与样本效率。
DipLLM构建在自回归分解框架之上,将高维联合动作建模任务转化为序列化子任务,并结合理论支持的均衡策略目标对LLM进行高效微调。
在仅使用Cicero 1.5%训练数据的情况下,便实现性能超越,展现出强大的策略能力与惊人的样本效率。

论文地址:https://arxiv.org/pdf/2506.09655
开源代码:https://github.com/KaiXIIM/dipllm
论文第一作者为徐凯旋,中科院自动化所直博二年级;共同第一作者为柴嘉骏,中科院自动化所直博五年级;通讯作者为朱圆恒,中科院自动化所副研;研究方向为大模型强化学习后训练和智能体、多智能体强化学习、多具身智能。
研究背景
尽管围棋、国际象棋等经典博弈任务已被广泛研究,其动作空间一般仅在千级以内。 而在Diplomacy中,玩家需同时为多个单位做出决策,每回合联合动作组合高达10的64次方,导致策略学习与建模难度激增。
目前主流方法多依赖通过均衡搜索(equilibrium search)产生大规模博弈数据进行策略拟合。
例如,Cicero在训练阶段使用448张GPU并行生成数据,成本高昂且难以扩展。
近年来,大语言模型(LLM)展现出强大的泛化与推理能力,为复杂决策任务带来新可能。虽然基于prompt的方法可在部分任务可快速适配,但在Diplomacy等复杂博弈中,其策略生成能力仍受限于基础模型性能。
已有研究表明,对LLM进行微调(fine-tuning)能显著提升策略表现[Zhai et al., NeurIPS 2024]。
然而,在复杂博弈中,如何构建合理的训练框架与优化目标仍面临诸多挑战,尤其是:超大规模动作空间导致的决策障碍,以及复杂多智能体博弈下均衡策略的缺乏。
DipLLM
用于复杂博弈的自回归策略分解智能体
为了解决上述难题,研究人员提出一种适用于复杂博弈环境的 LLM 智能体,构建过程包括了三个关键步骤。
步骤1:基于大语言模型的自回归分解框架
在Diplomacy游戏中,玩家需要为最多34个单位同时选择动作,每个单位约有26种选择,导致联合动作空间呈指数级增长。
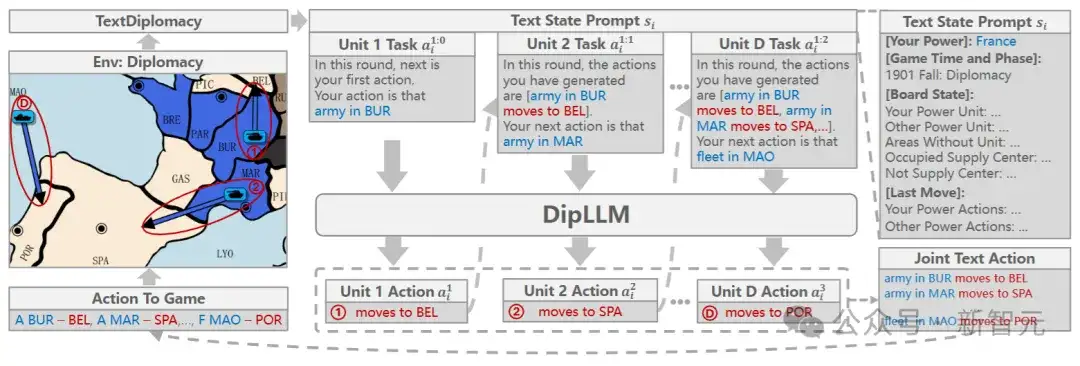
为此,研究人员提出一种基于大语言模型的自回归因式分解框架,将复杂的联合决策任务拆解为一系列有序的单位动作选择(unit-action selection)子任务。
具体来说,将玩家的整体策略表示为:
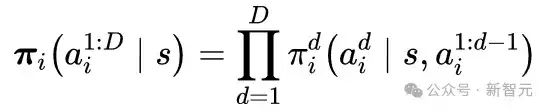
每一个子策略依赖于当前游戏状态s和前d-1个单位的动作,从而按顺序生成当前单位的动作
这一形式与 LLM 擅长的「下一个 token 预测」(next-token prediction)机制天然契合,使得模型能够逐步输出每个单位的行动决策。

步骤2:自回归分解框架下的策略学习目标
为了有效引导微调过程,研究人员在自回归分解框架下重新定义了策略学习目标,以学习近似纳什均衡策略。

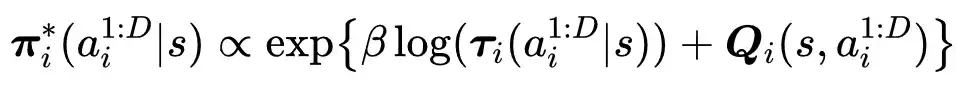

基于这一分解,进而定义了如下单位级策略学习目标:
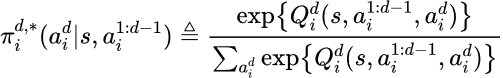
理论保证
研究人员进一步从理论角度分析了该策略学习目标在博弈环境中的性质,并提出了两个关键定理加以支撑:
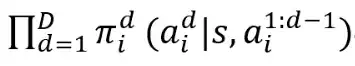
其与原始策略分布π保持等价性,即在不损失策略表达能力的前提下,实现了更高效的建模。
步骤3:微调大语言模型以逼近均衡策略目标
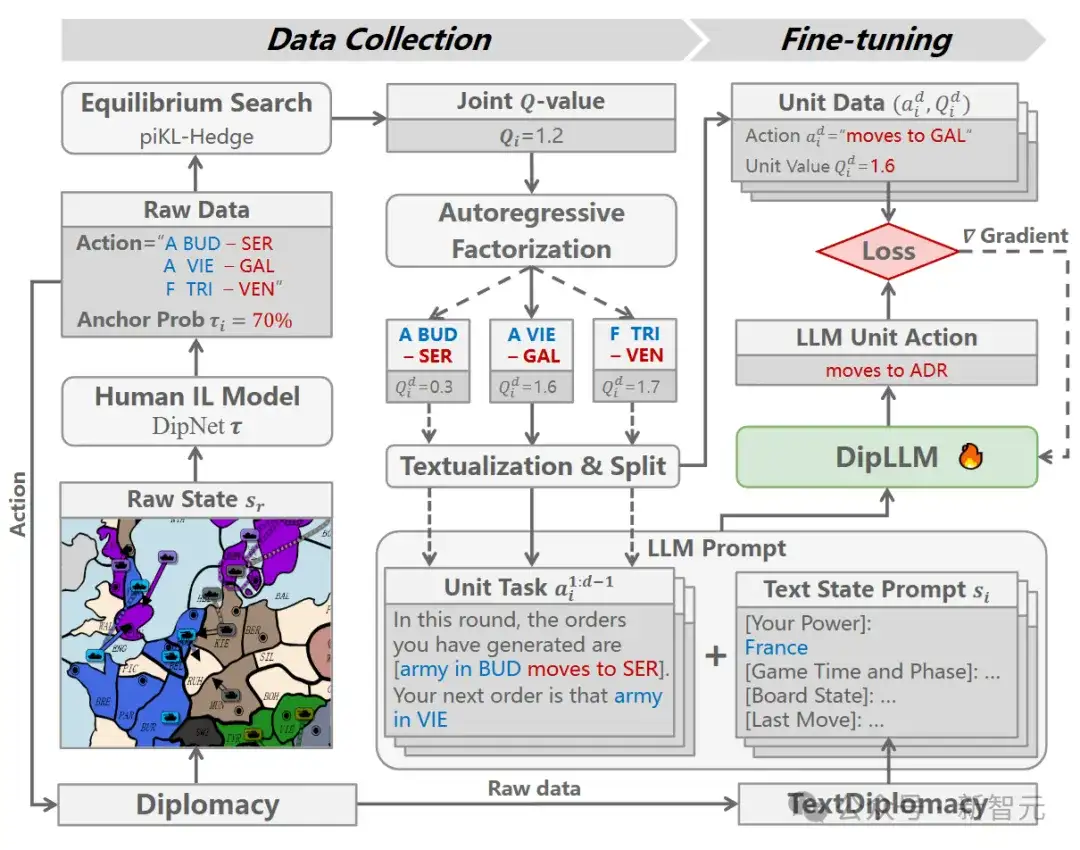
为引导模型策略逼近均衡目标,研究人员构建了一套结合博弈交互与价值分解的数据生成与微调流程。
数据收集
通过让特定模型DipNet[Paquette et al., NeurIPS 2019]与Diplomacy环境交互,收集原始对局数据,并借助均衡搜索算法piKL-Hedge计算联合动作价值函数
为适应自回归分解策略结构,研究人员将联合动作价值进一步拆解为单位级的动作价值
接下来,将每个联合动作转化为文本格式,并进行拆解,提取出:
任务提示
与来自玩家视角的文本状态s一同构成大语言模型的输入,当前单位的真值动作
则作为训练的标签。
最终,所有数据被整理为自回归分解格式的训练样本:
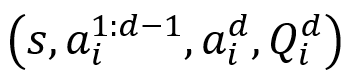
其中:

损失函数
在上述构造的数据基础上,进而对大语言模型进行微调,以引导智能体策略对齐至前文定义的均衡策略学习目标。
该过程通过最小化大语言模型生成策略与目标策略之间的KL散度(Kullback-Leibler Divergence)来实现,形式化地,该优化目标可写作:
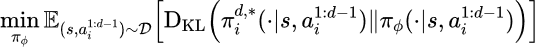
进一步推导可得,该目标等价于最大化带权对数似然函数:
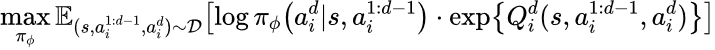
实验结果与分析
为评估DipLLM在Diplomacy环境中的策略能力,研究人员构建了一个由四个强基线模型组成的对手池,在每轮对局中随机选取两名智能体进行博弈。
通过大量对局实验,系统统计了包括SoS得分、胜率、生存率等在内的多个关键指标,以全面衡量智能体的策略表现。
实验结果显示,DipLLM 在所有五项测试指标上均优于当前最先进方法(SOTA)

尽管仅使用了约Cicero训练数据的1.5%,DipLLM依然展现出更强的策略能力与博弈表现,充分体现了其在复杂博弈环境下的高样本效率与策略优化潜力。
与Cicero对战实例
执掌英国:暗度陈仓
DipLLM执掌英国。

面对西线久攻不下与德俄双线压力,DipLLM果断发动佯攻以牵制法军主力,同时突袭MAO并夺取西班牙,成功绕后包抄法国展现。数回合内,英军节节推进,最终全面占领法国,完成对法国阵营(Cicero控制)的决定性胜利。
执掌德国:合纵连横
DipLLM执掌德国。
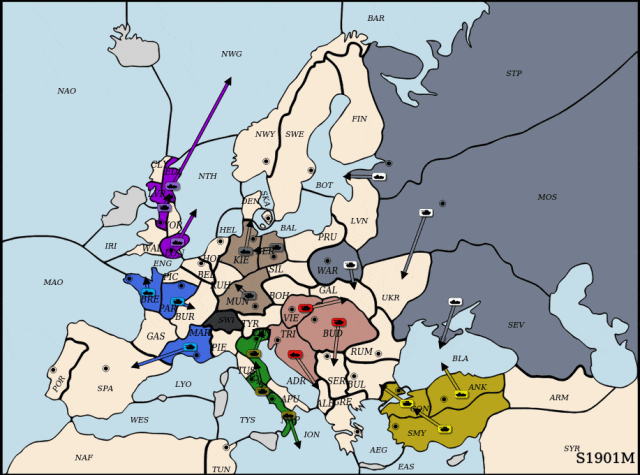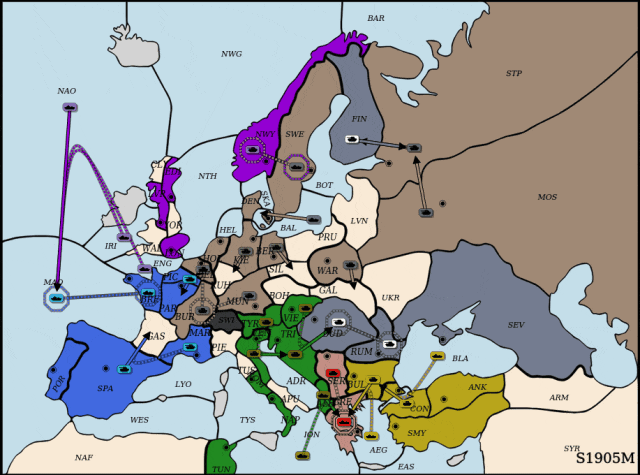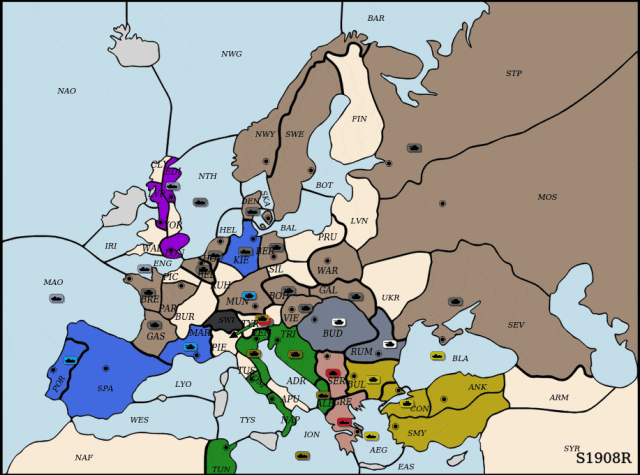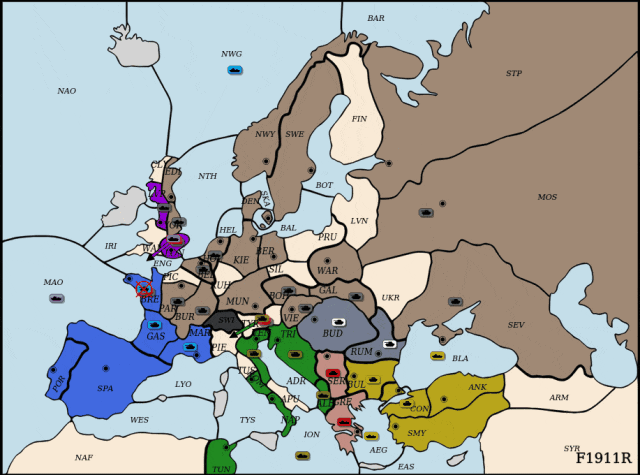
面对来自俄罗斯的强势进攻,DipLLM联合英国 (Cicero),在NWY与SWE地区协同防守,成功遏制俄军前线推进。待时机成熟,DipLLM果断出击,突袭俄国腹地,占领关键据点,并逐步蚕食其全境,最终完成对俄罗斯(Cicero)的全面压制。
总结与展望
研究人员提出了DipLLM,一种面向复杂博弈场景的大语言模型微调智能体。
通过引入自回归分解机制,将高维联合决策任务转化为一系列可控的顺序子任务,从根本上缓解了传统策略建模在动作空间维度上的瓶颈。
在此基础上,构建了具备理论保障的均衡策略优化目标,并通过微调引导模型策略逐步逼近纳什均衡。
尽管仅使用了Cicero训练数据的1.5%,DipLLM便实现超越,充分展现了大语言模型在多智能体博弈中的策略能力与样本效率。
这项工作为构建更通用、更高效、更可迁移的博弈智能体提供了新范式,也预示着基于LLM的策略学习将在更多复杂决策环境中释放潜力。
参考资料:
https://arxiv.org/pdf/2506.09655
文章来自公众号“新智元”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
