
直接从像素到单词:这个原生大模型统一单图、多图、视频和空间智能
直接从像素到单词:这个原生大模型统一单图、多图、视频和空间智能今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。
来自主题: AI技术研报
7510 点击 2026-06-24 16:06
 搜索
搜索
今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。

豆包大模型2.1 Pro正式发布。但字节这次没有像某些厂商那样疯狂堆参数、刷榜单,而是把刀锋对准了一个更硬核的方向:让AI真正能“干活” 。作为本次大会发布的主力模型,豆包2.1 Pro 在 Coding(编程)、Agent(智能体)、VLM(视觉语言模型)三大核心方向实现能力跃升,多项评测表现优于Claude Opus 4.6
大模型已经能流畅对话、看图识物,但一个更底层的问题始终没被真正解决——它们是否「理解」了我们所处的三维世界?

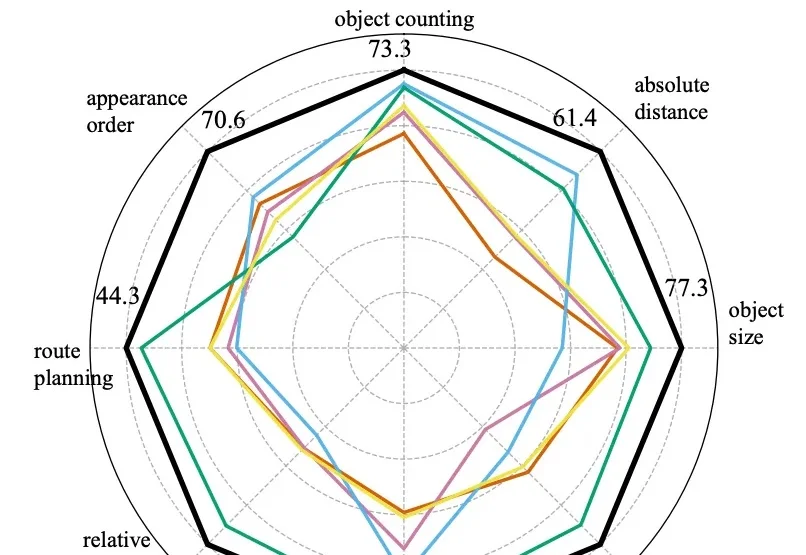
Meta 发布了一项令人震撼的研究工作 VLM³,首次揭示了三维视觉学习的 Bitter Lesson:标准的视觉语言模型 + scale 数据就是最简单有效的范式,针对特定任务的架构、损失函数以及数据增强的设计,甚至是 regression 的 formulation,均不是三维视觉学习的必要条件。
当前,测试时扩展范式普遍致力于增加推理长度。然而,已有研究表明,随着推理长度的持续增长,以垂直扩展为核心的计算范式容易陷入探索僵化等问题。因此,从另一维度拓展推理的宽度显得尤为重要。K2.5、Step3-VL 和 LongCat-Flash-Thinking 等模型已在推理宽度方面开展了有益的探索。

基于视觉语言模型(VLM)的多智能体系统(MAS)正成为复杂多模态协作的核心方案,却被一个致命痛点死死卡住:多智能体视觉幻觉滚雪球——单个智能体的视觉误判通过纯文本信息流逐级放大,早期细微错误最终演变成系统性崩溃。

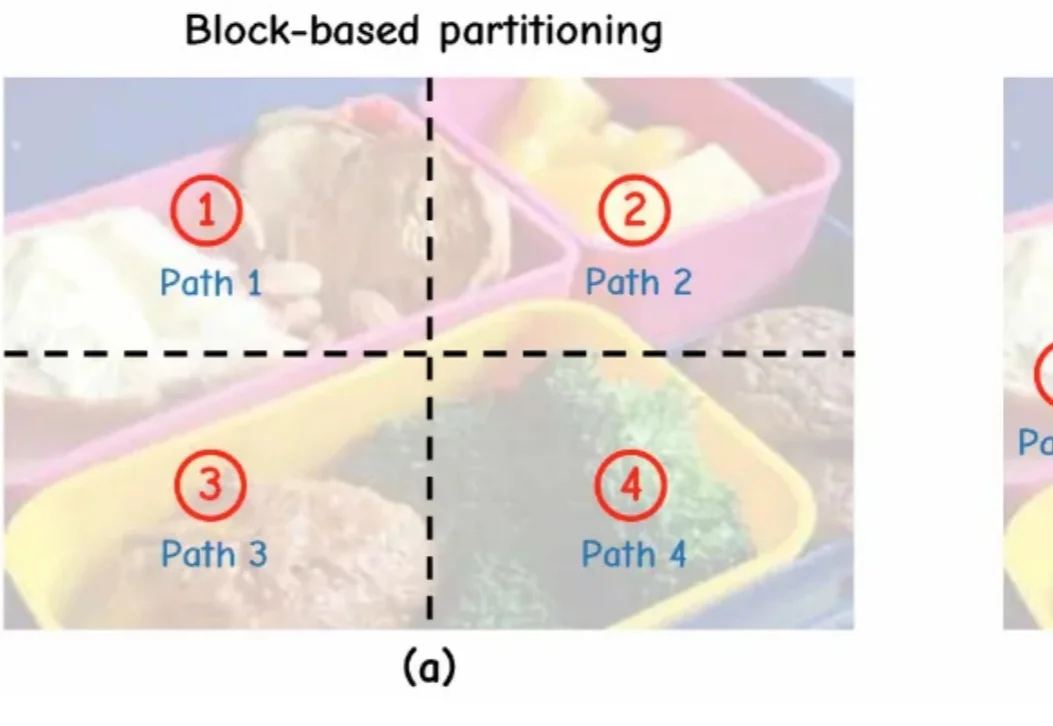
今天的大型视觉语言模型(VLM)做离线视频分析很强,但一到实时场景就尴尬: 视频在往前走,模型还在“补作业”。
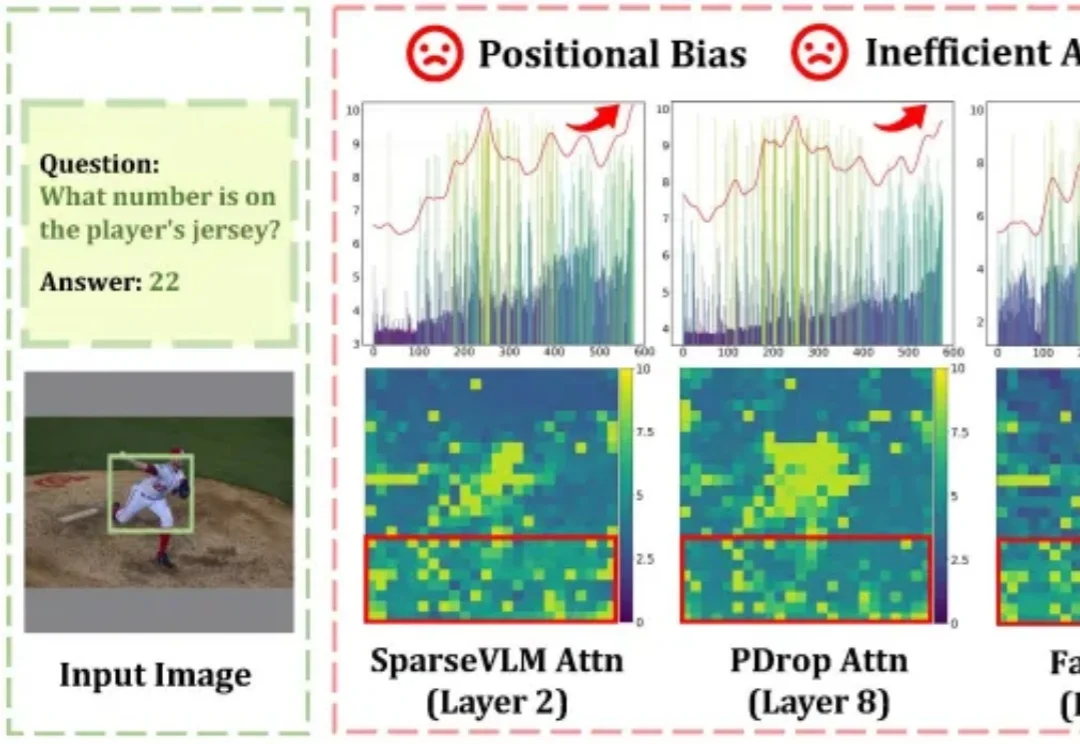
随着高分辨率图像理解与长视频处理需求的爆发式增长,大型视觉语言模型(LVLMs)所需处理的视觉 Token 数量急剧膨胀,推理效率成为落地部署的核心瓶颈。Token 压缩是缩短序列、提升吞吐的直接手段,但现有方法普遍依赖注意力权重来判断 Token 重要性,这一路线暗藏两个致命缺陷:

当前,大语言模型(LLMs)和视觉语言模型(VLMs)在语义领域的成功未能直接迁移至物理机器人,归根结底在于其互联网原生的基因。

近日,liko.ai 宣布完成首轮融资,由商汤国香资本、东方富海、讯飞创投、洪泰基金、正轩投资、面壁智能等多家产业及财务投资机构联合投资,光源资本担任孵化方及独家财务顾问。本轮融资将用于端侧视觉语言模型、AI 原生硬件以及家庭多模态通用终端研发。