# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在机器人学习领域,如何让AI真正“看懂”三维世界一直是个难题。
VLA模型通常建立在预训练视觉语言模型(VLM)之上,仅基于2D图像-文本数据训练,缺乏真实世界操作所需的3D空间理解能力。
当前基于显式深度输入的增强方案虽有效,但依赖额外传感器或深度估计网络,存在部署难度、精度噪声等问题。

为此,上海交通大学和剑桥大学提出一种增强视觉语言动作(VLA)模型空间理解能力的轻量化方法Evo-0,通过隐式注入3D几何先验,无需显式深度输入或额外传感器。
该方法利用视觉几何基础模型VGGT,从多视角RGB图像中提取3D结构信息,并融合到原有视觉语言模型中,实现空间感知能力的显著提升。
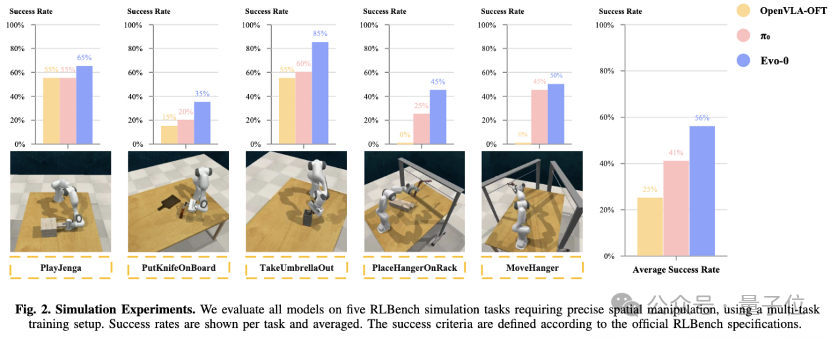
在rlbench仿真实验中,Evo-0在5个需要精细操作的任务上,平均成功率超过基线pi0 15%,超过openvla-oft 31%。
Evo-0提出将VGGT作为空间编码器,引入VGGT训练过程中针对3D结构任务提取的t3^D token。这些token包含深度上下文、跨视图空间对应关系等几何信息。
模型引入一个cross-attention融合模块,将ViT提取的2D视觉token作为query,VGGT输出的3D token作为key/value,实现2D–3D表征的融合,从而提升对空间结构、物体布局的理解能力。
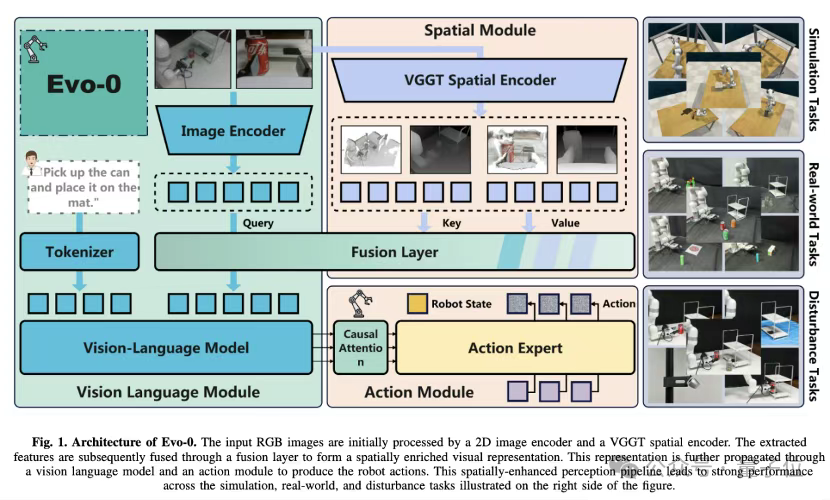
融合后的token与语言指令共同输入冻结主干的VLM,预测动作由flow-matching策略生成。训练中,仅微调融合模块、LoRA适配层与动作专家,降低计算成本。
研究团队通过在5个rlbench模拟任务、5个真实世界操作任务上的全面实验,以及在5种不同干扰条件下的鲁棒性评估,证明了空间信息融合方法的有效性。在所有设置中,Evo-0都一致地增强了空间理解,并且优于最先进的VLA模型。
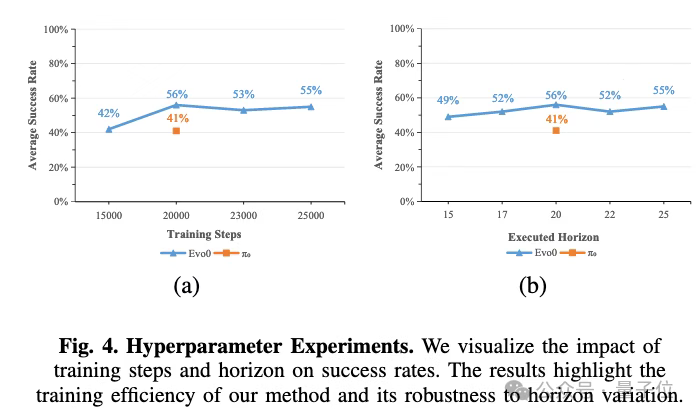
除了上述展示的效果外,在超参数实验中,为了分析超参数如何影响模型性能,团队在5个RLBench任务上进行了额外的实验。他们重点关注两个方面:训练步数和执行步数,并评估它们对任务成功率的影响。
值得注意的是,仅用15k步训练的Evo-0已经超过了用20k步训练的π0,这表明Evo-0具有更高的训练效率。
在真机实验部分,实验设计五个空间感知要求高的真实机器人任务,包括目标居中放置、插孔、密集抓取、置物架放置及透明物体操作等。所有任务均对空间精度容忍度极低。
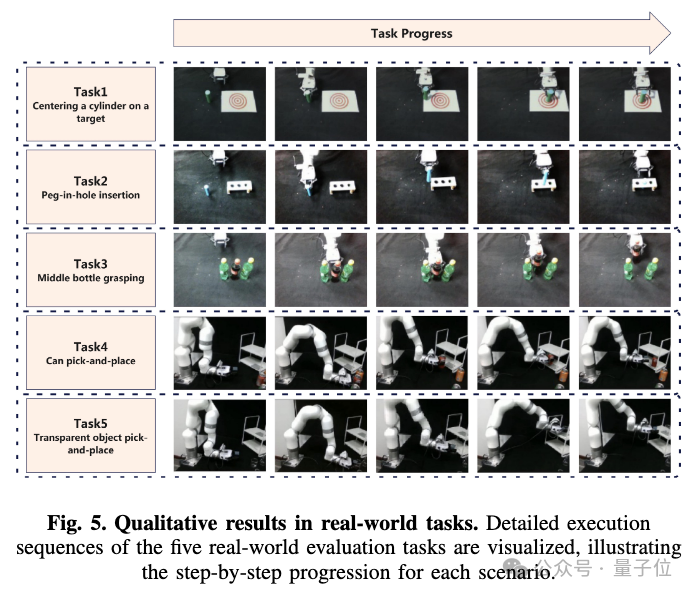
Evo-0在全部任务中均超越基线模型pi0,平均成功率提升28.88%。尤其在插孔与透明物抓取任务中,表现出对复杂空间关系的理解与精准操控能力。
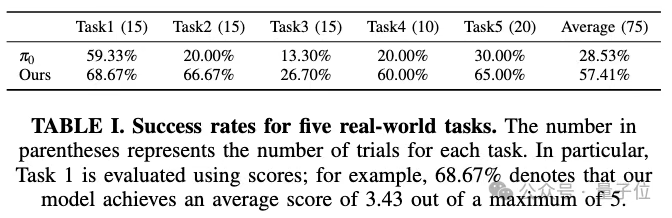
在鲁棒性实验中,论文设计了5类干扰条件:(1)引入一个未见过的干扰物体,(2)背景颜色的变化,(3)目标位置的位移,(4)目标高度的变化,(5)相机角度的变化。Evo-0均有相对鲁棒的结果,并且强于基准pi0。

综上所述,Evo-0的关键在于通过VGGT提取丰富的空间语义,绕过深度估计误差与传感器需求,以插件形式增强VLA模型的空间建模能力,训练高效、部署灵活,为通用机器人策略提供新的可行路径。
论文链接:https://arxiv.org/abs/2507.00416
文章来自于微信公众号“量子位”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
