
自变量 200 亿估值背后,具身智能在给什么定价?
自变量 200 亿估值背后,具身智能在给什么定价?200 亿元估值已经成了头部具身智能公司的新标杆。
来自主题: AI资讯
8074 点击 2026-07-01 15:03
 搜索
搜索
200 亿元估值已经成了头部具身智能公司的新标杆。

全尺寸、超仿生、成年人限定。

2026年,具身智能赛道的融资热度仍在持续,但投资人的提问方式已经变了。

物理AI发展到现在,所有玩家都奔着同一个方向使劲: 让机器人「读懂」所处的物理环境。
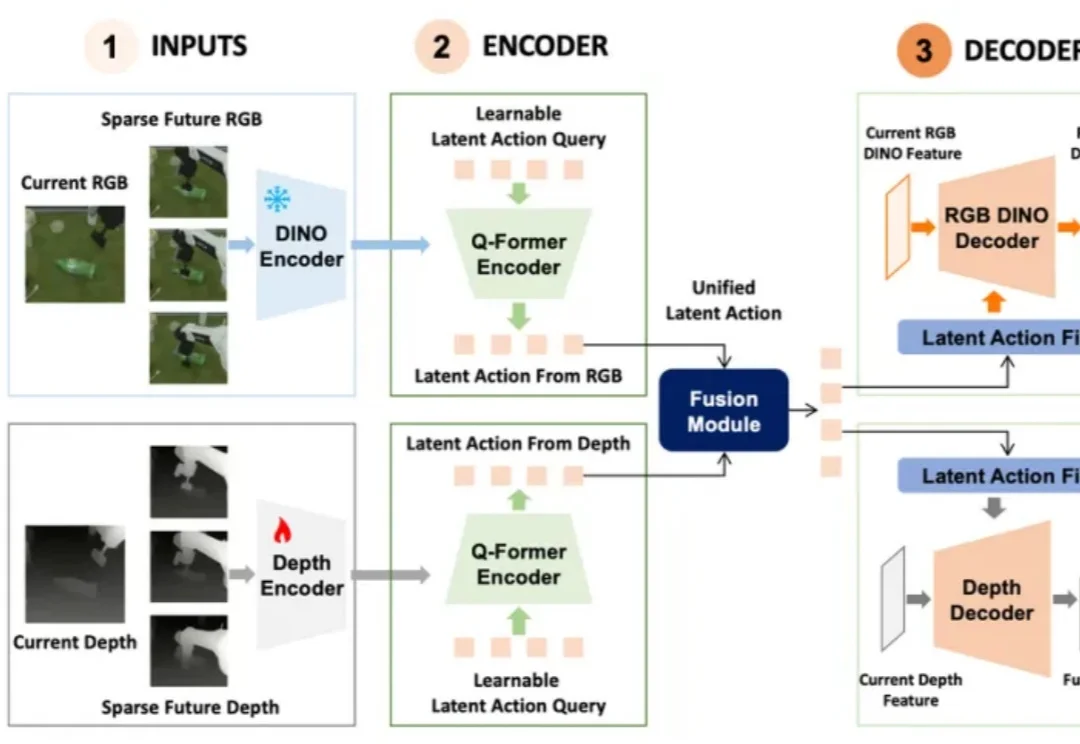
当前,物理 AI 正面临着关于泛化能力的普遍质疑。当模型缺乏对真实物理规律的深度认知、难以跨越复杂多变的开放场景时,如何让机器人真正理解物理世界并精准规划决策,已成为具身智能破局的关键。

小布米OTA V3.0来了。喊一声就跳舞,拖拽胳膊就学会新动作,还能跟你打拳——你的第一个个人机器人,这次真的听话了。

Z Potentials独家获悉,柔性具身智能公司深圳擎羽科技有限公司(以下简称:擎羽科技)已完成 Pre-A 轮融资。本轮融资由顺为资本、五源资本联合投资,高鹄资本担任独家财务顾问。这也是继德迅投资、东方富海等一线机构相继出手后,擎羽科技在半年内完成的第三轮融资。

2026年,具身智能迎来融资狂潮。
德塔智能试图为双足人形机器人构建能够理解空间、协调全身并完成真实任务的基础模型。 原生人形机器人基础模型公司德塔智能(Delta Intelligence)近日已连续完成种子+轮、天使轮及天使+轮融资。

国内具身智能赛道再次迎来重要时刻。