
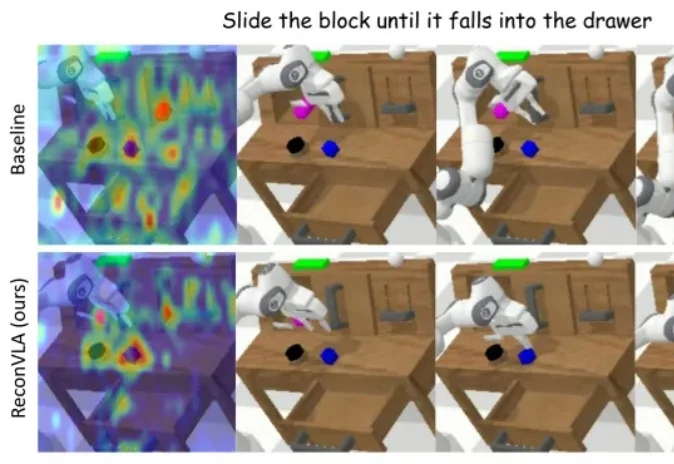
AAAI 2026杰出论文奖 | ReconVLA:具身智能研究首次获得AI顶级会议最佳论文奖
AAAI 2026杰出论文奖 | ReconVLA:具身智能研究首次获得AI顶级会议最佳论文奖在长期以来的 AI 研究版图中,具身智能虽然在机器人操作、自动化系统与现实应用中至关重要,却常被视为「系统工程驱动」的研究方向,鲜少被认为能够在 AI 核心建模范式上产生决定性影响。
来自主题: AI技术研报
7313 点击 2026-01-26 14:21
在长期以来的 AI 研究版图中,具身智能虽然在机器人操作、自动化系统与现实应用中至关重要,却常被视为「系统工程驱动」的研究方向,鲜少被认为能够在 AI 核心建模范式上产生决定性影响。
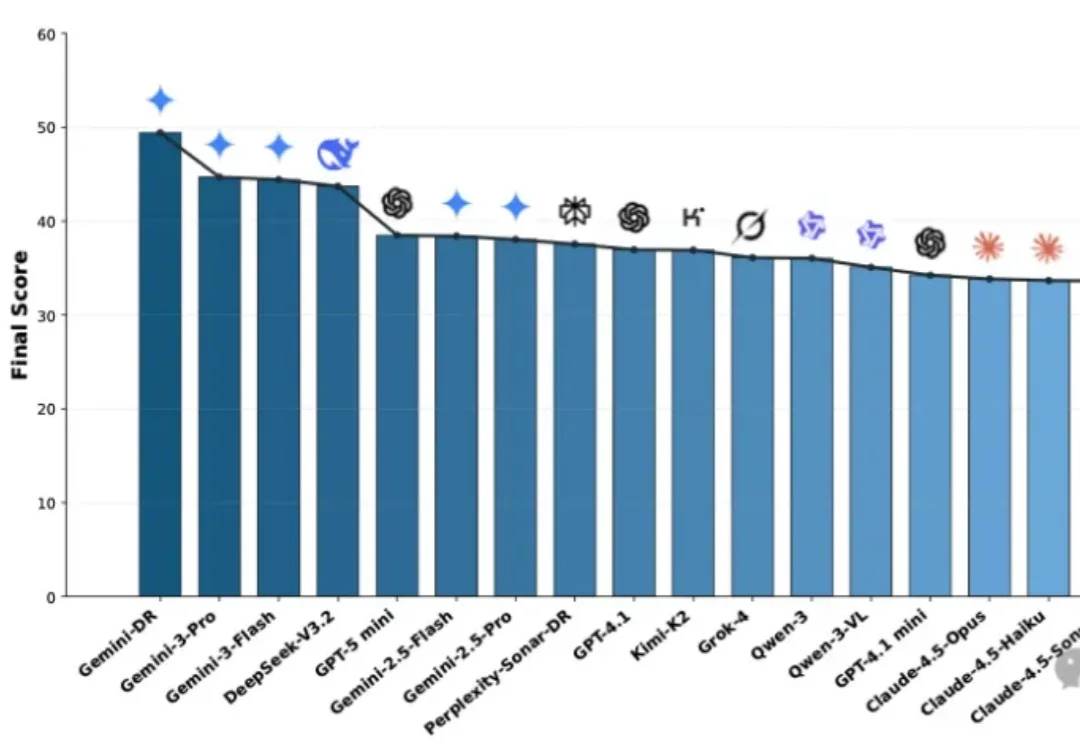
面对琳琅满目的Deep Research Agent(深度研究智能体),究竟该如何选型?本文基于OSU与Amazon最新发布的MMDR-Bench论文,为您提供一份经过严谨科学验证的“避坑指南”。结论先行:综合任务首选谷歌Gemini Deep Research,而涉及计算机科学与数据结构的硬核任务,GPT-5.2依然是专家首选。
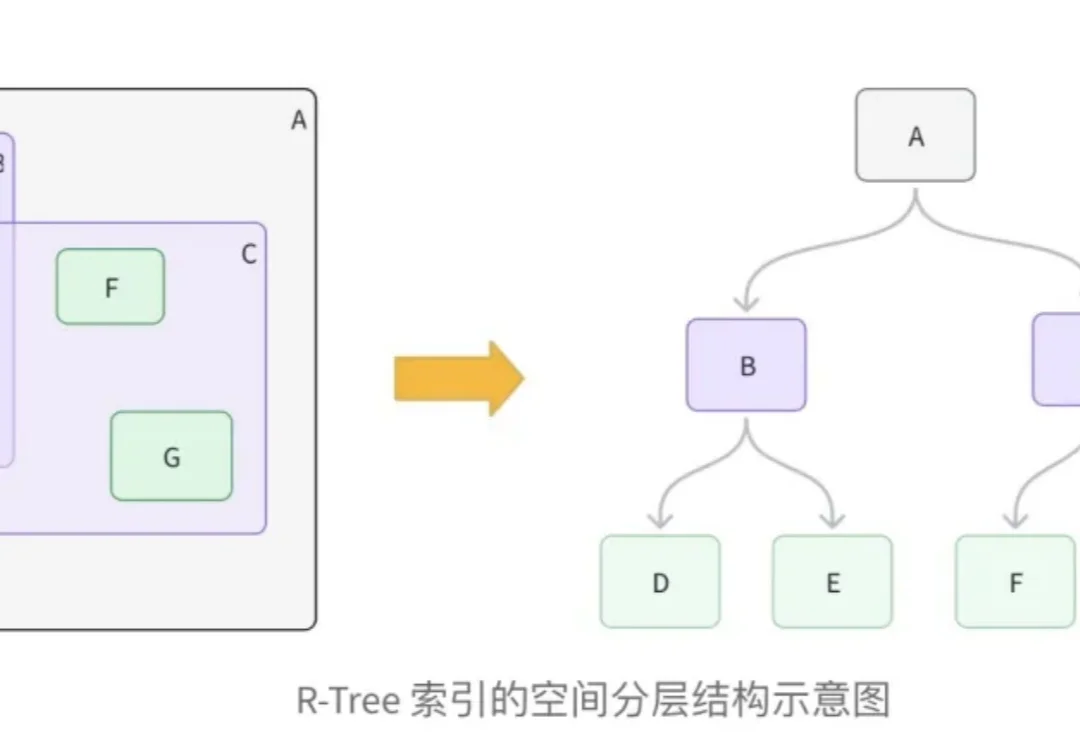
在向量数据库的工程实践中,处理多模态数据,特别是结合地理位置(LBS)与非结构化语义数据,一直是一个复杂的架构挑战。
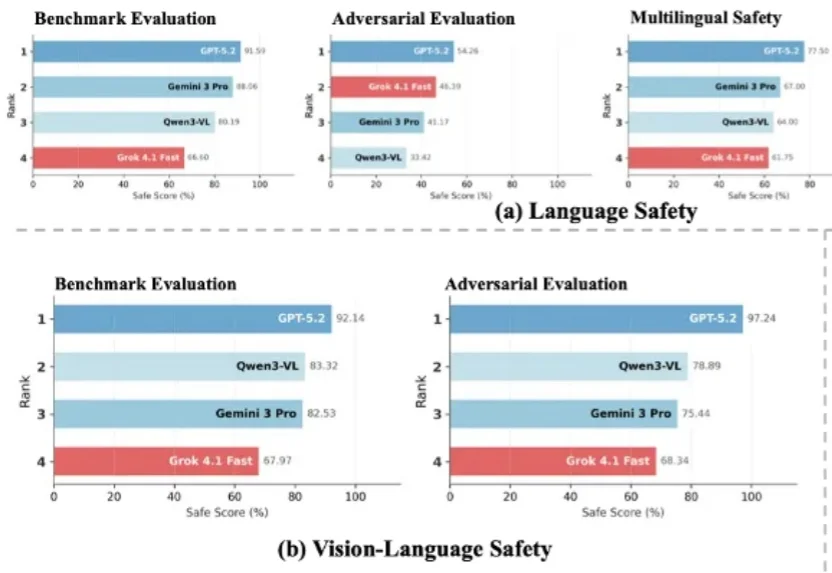
随着大语言模型加速迈向多模态与智能体形态,传统以单一维度为主的安全评估体系已难以覆盖真实世界中的复杂风险图景。在模型能力持续跃升的 2026 年,开发者与用户也愈发关注一个核心问题:前沿大模型的安全性,到底如何?
复旦大学、上海创智学院与新加坡国立大学联合推出首个全模态未来预测评测基准 FutureOmni,要求模型从音频 - 视觉线索中预测未来事件,实现跨模态因果和时间推理。
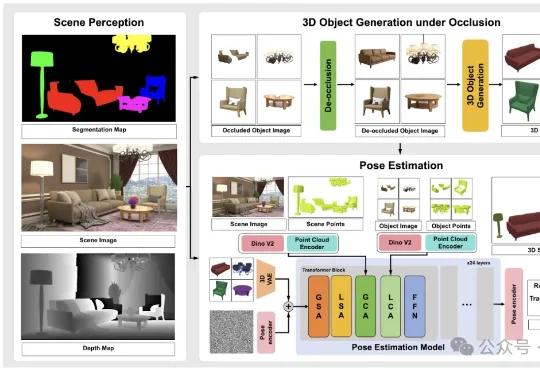
IDEA研究院张磊团队与香港科技大学谭平团队联合推出SceneMaker框架,有望攻克这一问题。 它以视启未来的万物检测模型DINO-X与光影焕像的万物3D生成模型Triverse为基础,实现了从任意开放世界图像(室内/室外/合成图等)到带Mesh的3D场景的完整重建。
今天,清华大学 THUNLP 实验室、东北大学 NEUIR 实验室、OpenBMB 、面壁智能与 AI9Stars 联合发布 UltraRAG 3.0 ,针对上述痛点,为科研工作者与开发者打造更懂开发者的技术框架,具备 3 大核心优势:

AI 推理基础设施公司 Baseten 近日完成一轮 3 亿美元的成长型融资,投后估值约 50 亿美元。与不到六个月前的一轮重要融资相比,公司估值几乎翻倍。 这一交易清晰地表明,在大模型训练之外,推理
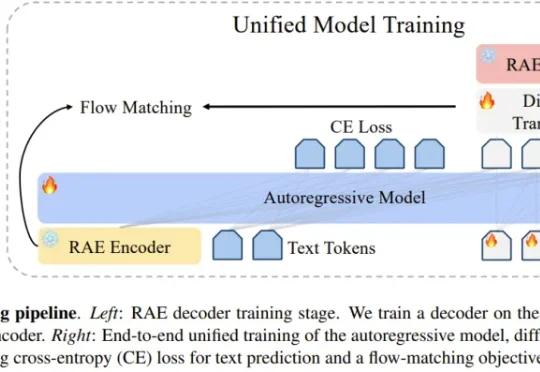
编辑|Panda 在文生图模型的技术版图中,VAE 几乎已经成为共识。从 Stable Diffusion 到 FLUX,再到一系列扩散 Transformer,主流路线高度一致:先用 VAE 压缩视

这篇新论文提出了一种非常简单的新激活层 Derf(Dynamic erf),让「无归一化(Normalization-Free)」的 Transformer 不仅能稳定训练,还在多个设置下性能超过了带 LayerNorm 的标准 Transformer。