# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
面对琳琅满目的Deep Research Agent(深度研究智能体),究竟该如何选型?本文基于OSU与Amazon最新发布的MMDR-Bench论文,为您提供一份经过严谨科学验证的“避坑指南”。结论先行:综合任务首选谷歌Gemini Deep Research,而涉及计算机科学与数据结构的硬核任务,GPT-5.2依然是专家首选。
随着Deep Research概念的爆发,大家面临着一个共同的困惑:在处理包含大量复杂图表、需要多步联网检索的真实任务时,到底哪家强? 这里的评价标准不再是简单的文本生成流畅度,而是对视觉证据的精确提取和引用源的绝对诚实。

俄亥俄州立大学(OSU)联合亚马逊最新发布的MMDeepResearch-Bench,可能是目前业内最严苛的端到端多模态研究基准。他们用140个专家级任务,对当下最前新的25款顶尖模型进行了“全身体检”。
这篇文章专注于为您解读这份“体检报告”背后的硬核价值:为什么Gemini在多模态整合上遥遥领先?为什么文笔最好的模型反而最容易造假?以及在不同的垂直技术栈中,您应该如何配置您的Agent选型策略。
研究者构建了包含140个专家级任务的数据集,覆盖21个专业领域。与以往不同,这些任务被设计为“图文捆绑包(Image-Text Bundle)”,强制要求AI必须结合视觉信息才能作答。
官方项目主页通过一个清晰的层级图展示了其考核逻辑:
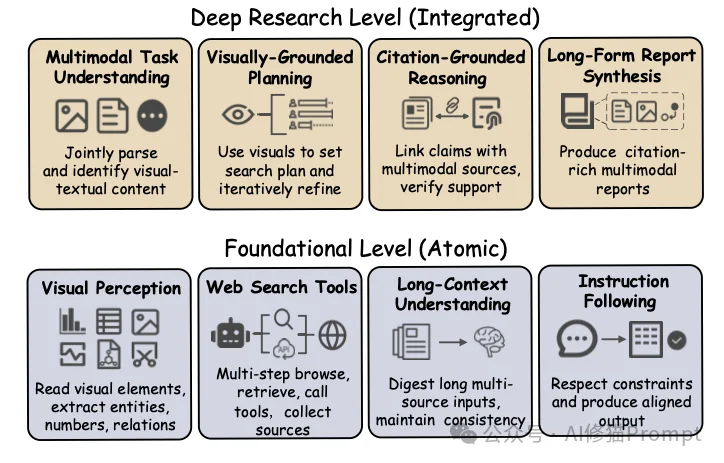
数据集模拟了两种截然不同的真实场景:

为了保证任务的难度和合理性,所有任务都经过了博士级领域专家的反复打磨。
仅仅有题目是不够的,如何给一篇几千字、包含大量引用和图表分析的报告打分?这是该论文最大的技术贡献之一。
研究者提出了一套名为MMDR-Eval的统一评估管道,包含三个核心模块,依次对报告进行“体检”。
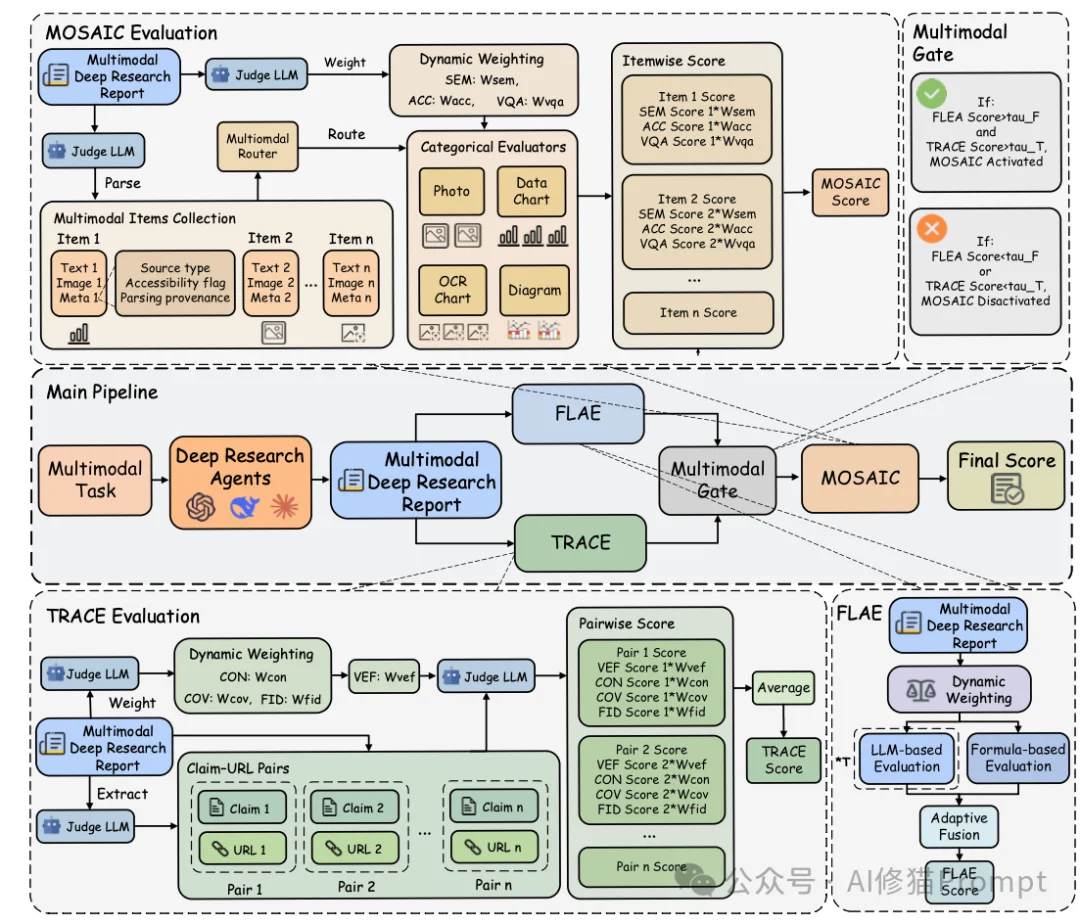
FLAE (Formula-LLM Adaptive Evaluation) 主要负责评估长篇报告的整体质量。
写报告这件事,不同领域要求不同。FLAE采用了一种“混合评价”策略:
它从三个维度打分:
TRACE (Trustworthy Retrieval-Aligned Citation Evaluation) 是整个评估体系中最核心的部分,权重占比最高(50%)。它不仅检查AI是否找到了信息,更检查AI是否诚实。
AI研究员最怕的就是“幻觉”,—本正经地胡说八道。TRACE通过以下步骤进行审计:
在TRACE中,研究者引入了一个极其严格的指标:VEF (Visual Evidence Fidelity)。
如果报告通过了前两关(得分非零),就会触发MOSAIC (Multimodal Support-Aligned Integrity Check)。
这个模块专门检查“文本”和“视觉附件”之间的整合度。因为图表和照片的分析逻辑是不同的,MOSAIC设计了一个路由机制(Router):
这种分而治之的策略,确保了无论是分析财务报表还是识别植物照片,都能得到公正的评价。
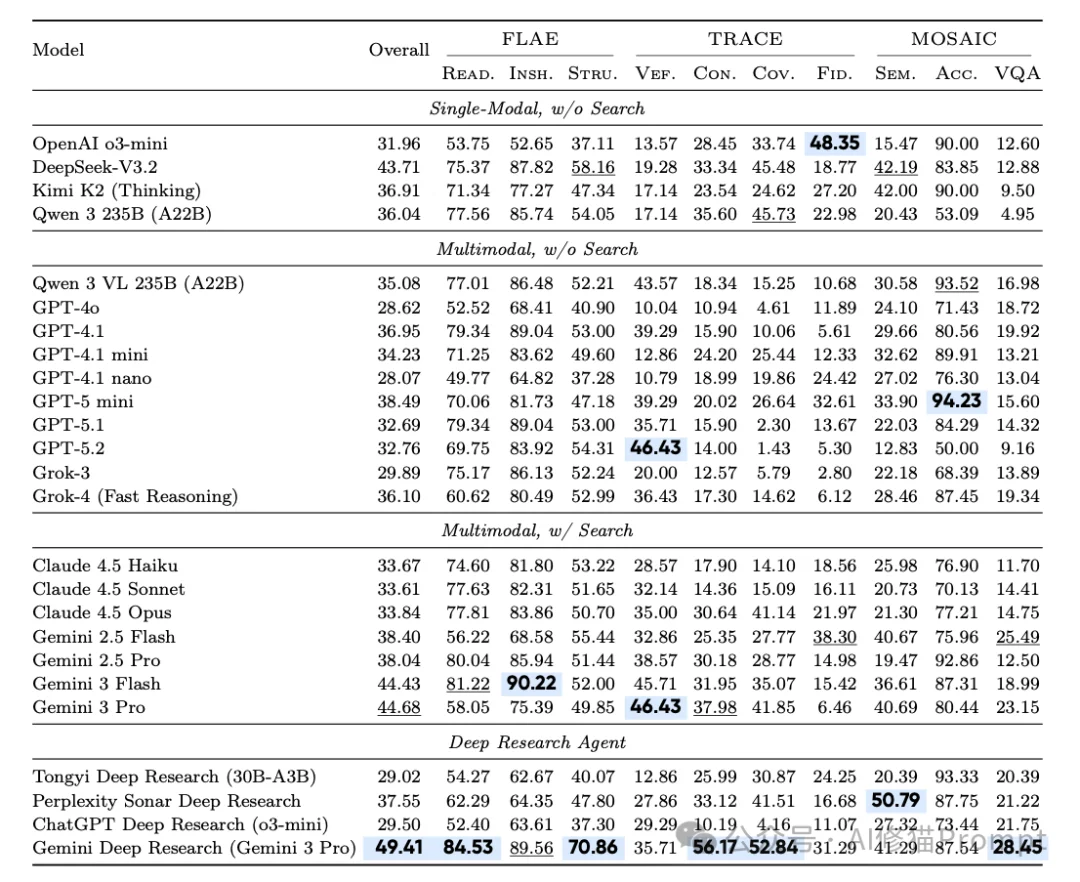
研究者在2024年底到2025年初的测试窗口期内,选取了25个代表性的系统进行评测,涵盖了三个梯队:
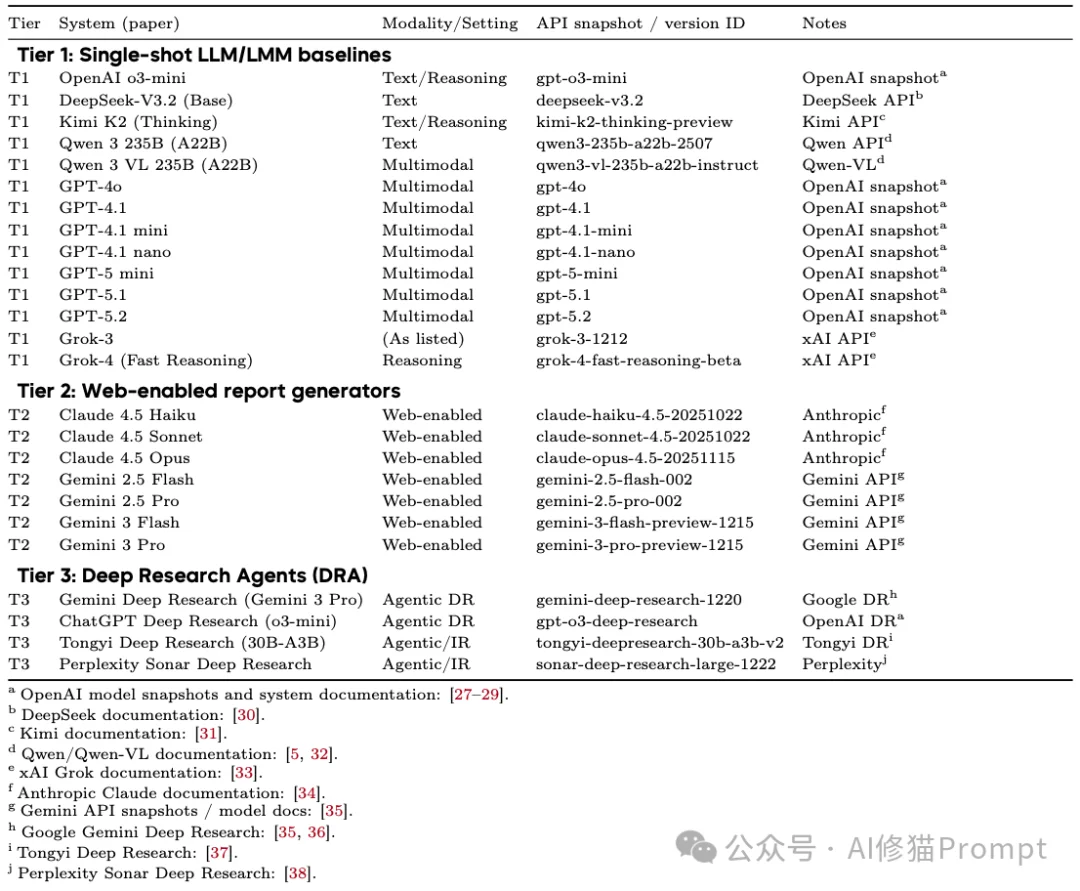
1.单模态基准(Tier 1):
2.联网多模态模型(Tier 2):
3.深度研究代理(Tier 3):
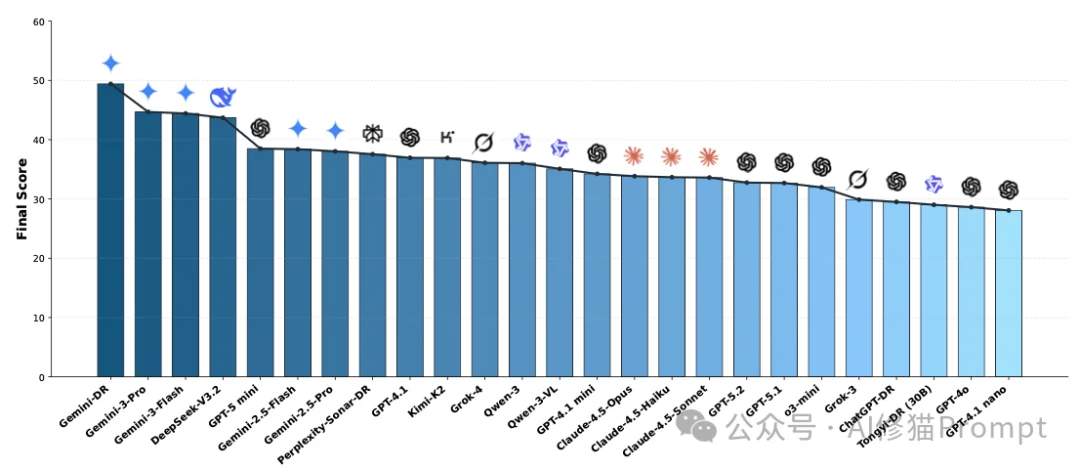
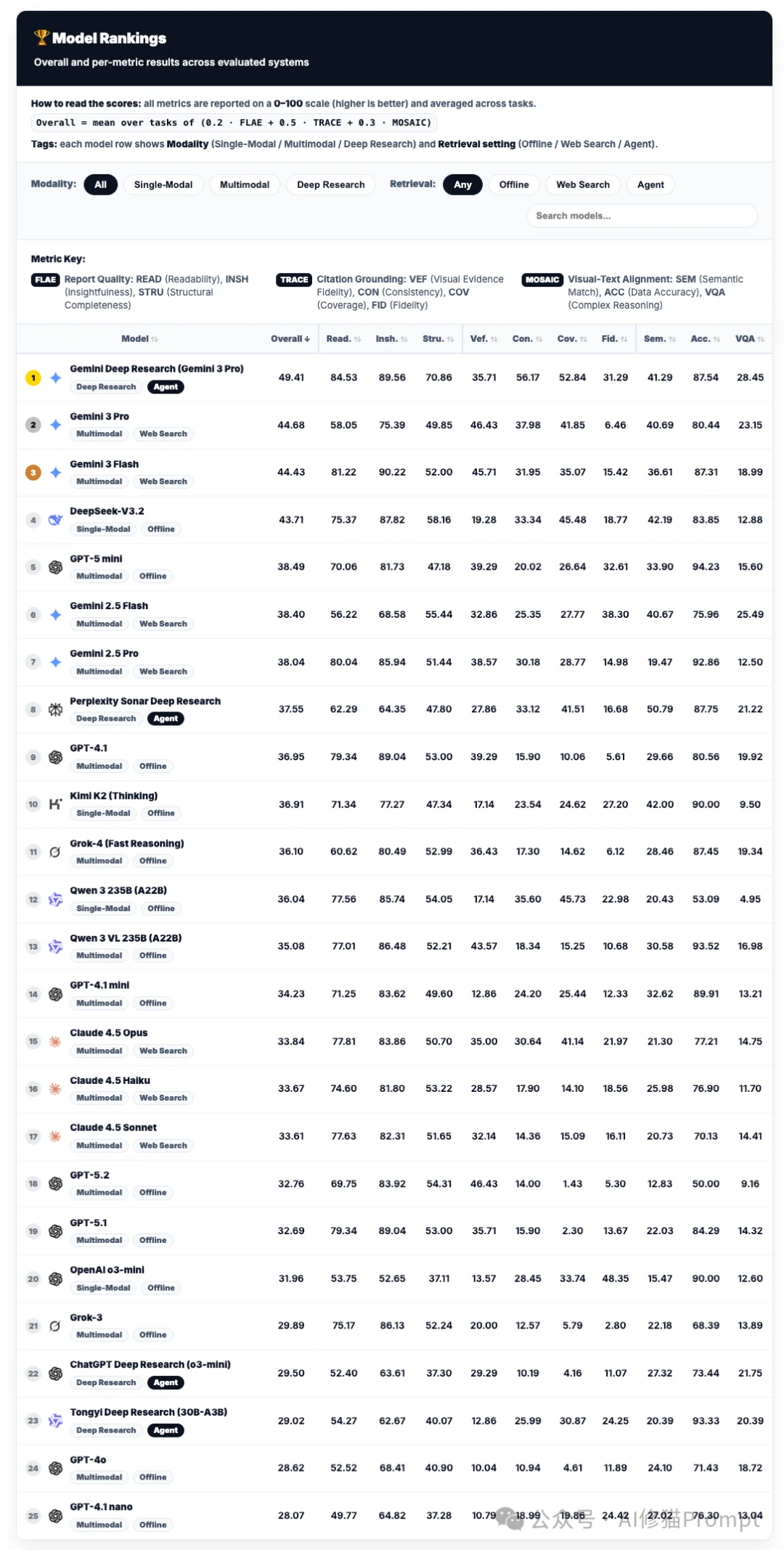
实验结果不仅是一个简单的排名,更揭示了当前AI模型能力的断层与特化。让我们对照上方的大型榜单(Model Rankings),通过三个维度来拆解这张复杂的“体检报告”。
在看排名之前,您需要理解决定分数的三个核心权重,这直接决定了模型的胜负手:
榜单前三名被Google包揽,展现了其在长窗口与多模态整合上的深厚积累。
请注意榜单的第4名。DeepSeek-V3.2(43.71分)。这是一个极具冲击力的结果。请注意它的标签:Single-Modal (单模态) 和 Offline (离线)。
您可能会惊讶地发现,GPT-5.2竟然掉到了第18名(32.76分),GPT-4o甚至在第24名。
对比Rank 1 (Gemini Agent) 和Rank 2 (Gemini LLM),我们可以看到Agent架构的真实价值:
除了排名,研究者通过深入的数据分析,挖掘出了三条发人深省的规律。这些发现打破了我们对“模型越大越好”或“多模态一定更强”的刻板印象。
您可能认为,给模型加上眼睛(视觉能力),它的表现一定比盲人(纯文本模型)好。但实验数据告诉我们:未必。
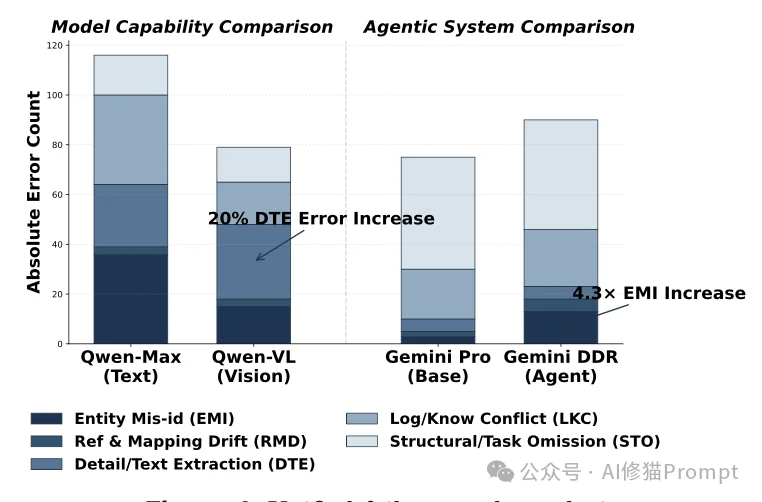
"Strong prose alone does not guarantee faithful evidence use." 许多模型(如GPT-5.2)能写出流畅优美的文章,甚至在视觉识别(VEF)上拿高分,但在引用规范性(TRACE)上却表现平平。这说明,写作能力与严谨的循证能力是两回事。模型往往为了追求文章的通顺,牺牲了证据的准确性。
深度研究代理(Agent)通常被认为比单一模型更强,因为它们可以反复搜索、自我修正。但实验发现了一个反直觉的现象:
在不同的任务领域,各家模型的表现也大相径庭。

为了更直观地理解MMDR-Bench的评分标准,我们深入剖析论文附录中两个具体的计算机科学与数学工程领域的高分案例。这两个案例清晰地展示了,在解决博士级难度的图表推理任务时,模型是如何得分,又是因何失分的。



这篇论文告诉我们,评价一个AI是否“聪明”,不能只看它聊得是否开心,更要看它做研究时是否严谨。
在AI能够完美通过MMDR-Bench的考验之前,当您阅读一份由AI生成的包含复杂图表分析的深度报告时,请务必保持一份审慎,去点开那些引用链接,看一看它是不是真的读懂了那张图。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
