

一文速通「机器人3D场景表示」发展史
一文速通「机器人3D场景表示」发展史上海交通大学、波恩大学等院校的研究团队全面总结了当前机器人技术中常用的场景表示方法。这些方法包括传统的点云、体素栅格、符号距离函数以及场景图等传统几何表示方式,同时也涵盖了最新的神经网络表示技术,如神经辐射场、3D 高斯散布模型以及新兴的 3D 基础模型。
来自主题: AI技术研报
8301 点击 2026-01-24 10:31
上海交通大学、波恩大学等院校的研究团队全面总结了当前机器人技术中常用的场景表示方法。这些方法包括传统的点云、体素栅格、符号距离函数以及场景图等传统几何表示方式,同时也涵盖了最新的神经网络表示技术,如神经辐射场、3D 高斯散布模型以及新兴的 3D 基础模型。
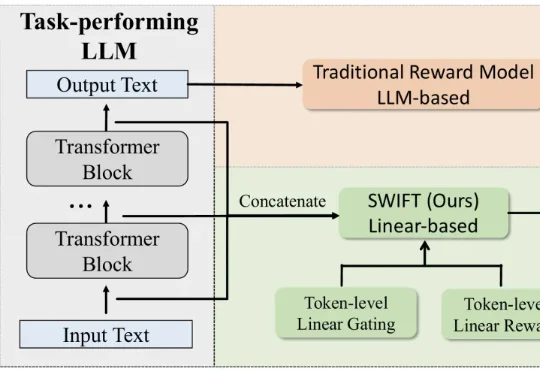
最新奖励模型SWIFT直接利用模型生成过程中的隐藏状态,参数规模极小,仅占传统模型的不到0.005%。SWIFT在多个基准测试中表现优异,推理速度提升1.7×–6.7×,且在对齐评估中稳定可靠,展现出高效、通用的奖励建模新范式。
大模型竞赛中,算力不再只是堆显卡,更是抢效率。

GEM框架利用认知科学原理,从少量人类偏好中提取多维认知评估,让AI在极少标注下精准理解人类思维,提高了数据效率,在医疗等专业领域表现优异,为AI与人类偏好对齐提供新思路。
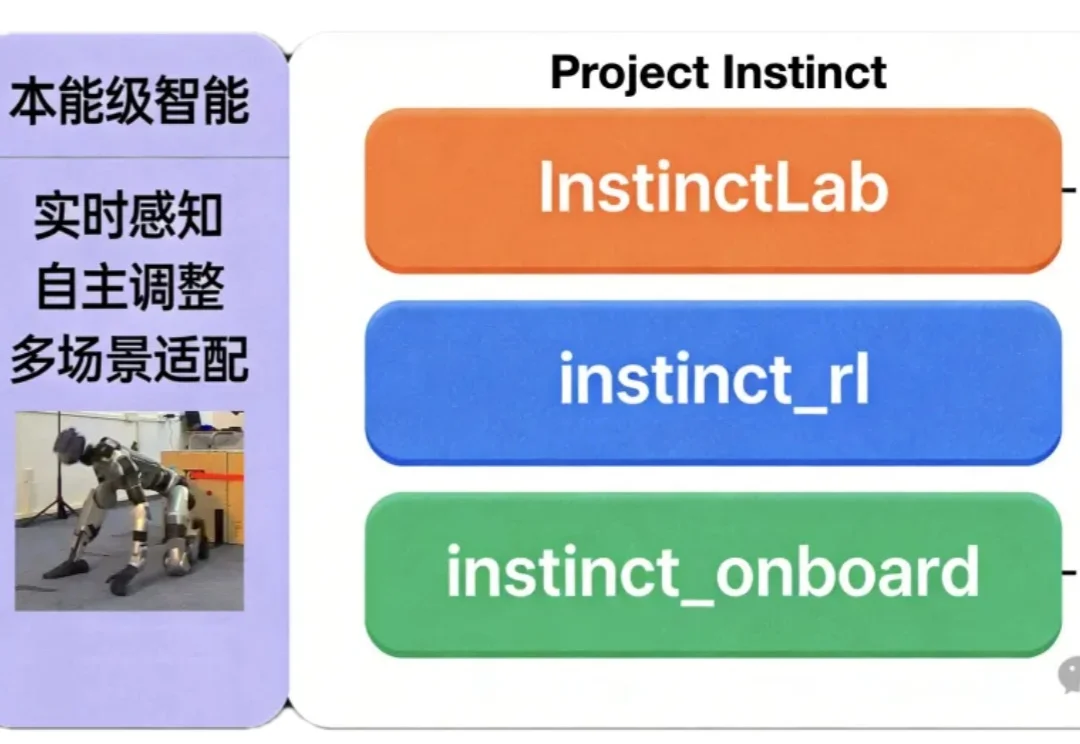
如何让机器人同时具备“本能反应”与复杂运动能力?
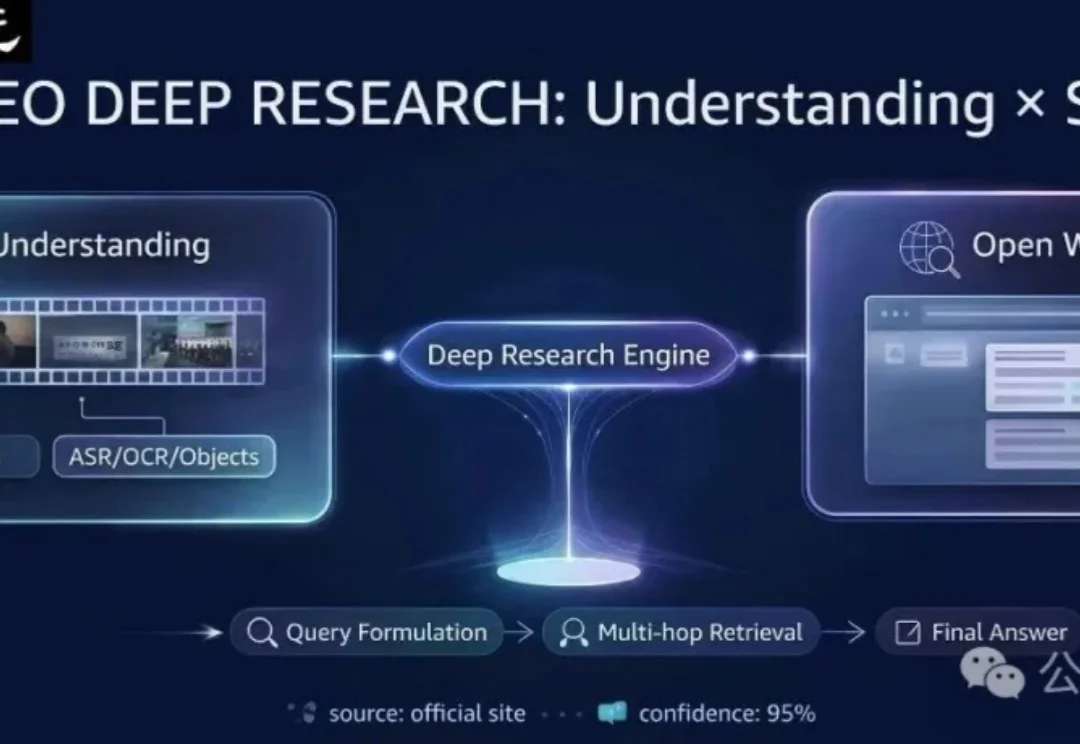
现有的多模态模型往往被困在「视频」的孤岛里——它们只能回答视频内的问题。但在真实世界中,人类解决问题往往是「看视频找线索 -> 上网搜证 -> 综合推理」。
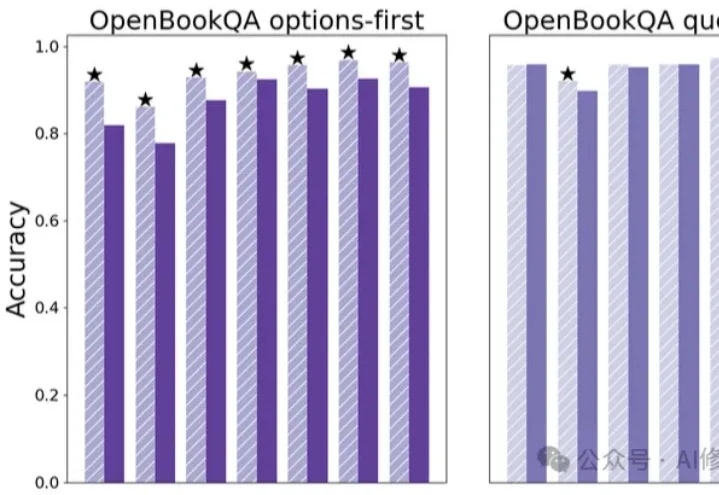
竟然只需要一次Ctrl+V?这可能是深度学习领域为数不多的“免费午餐”。
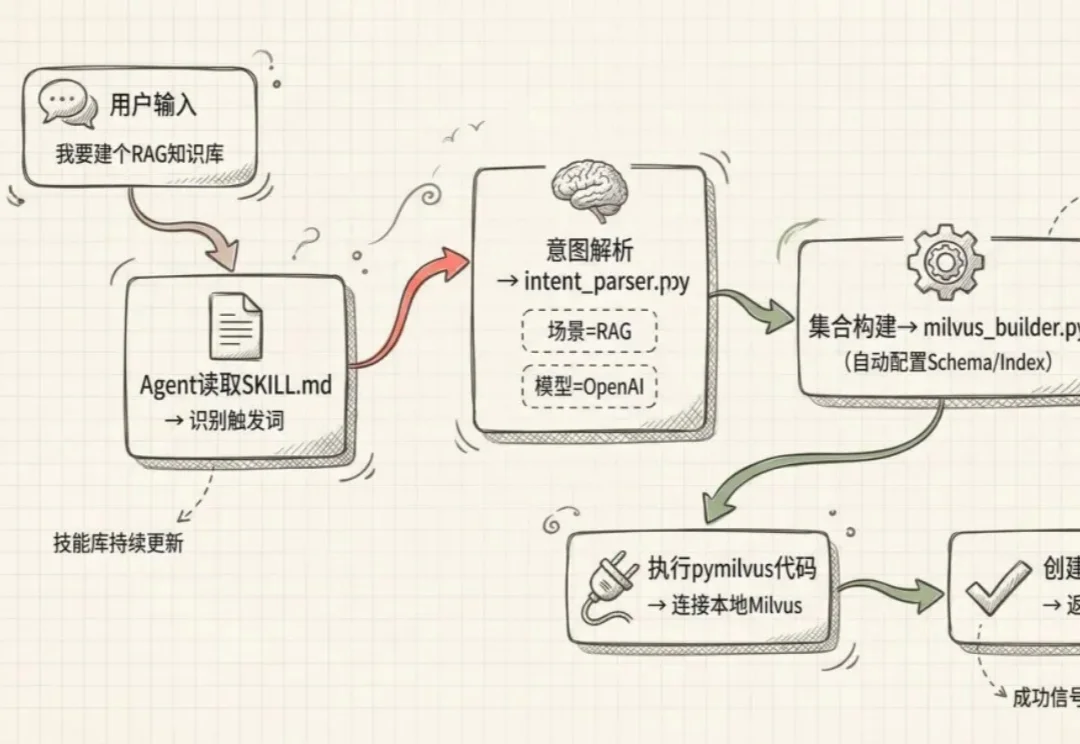
Agent很好,但要做好工具调用能才能跑得通。
近日,中国科学技术大学(USTC)联合新疆师范大学、中关村人工智能研究院、香港理工大学,在数据驱动的多功能双连通多尺度结构逆向设计领域取得重要突破。

现有AI记忆评测存在局限,如数据源单一、忽视变化本质、注入成本高等。CloneMem通过层次化生成框架构建合成人生,设计贴近真实场景的评测任务,涵盖多种问题类型。