
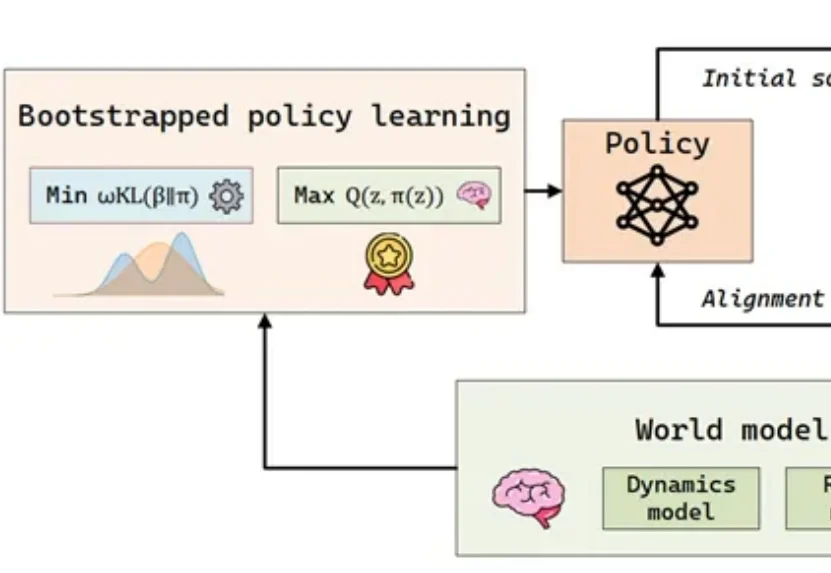
世界模型+强化学习=具身智能性能翻倍!清华&加州伯克利最新开源
世界模型+强化学习=具身智能性能翻倍!清华&加州伯克利最新开源在具身智能(Embodied AI)的快速发展中,样本效率已成为制约智能体从实验室环境走向复杂开放世界的瓶颈问题。
来自主题: AI技术研报
10843 点击 2026-01-21 16:09
在具身智能(Embodied AI)的快速发展中,样本效率已成为制约智能体从实验室环境走向复杂开放世界的瓶颈问题。
今天的 Agent,在一个独立的、短时间任务上的表现已经很不错了。
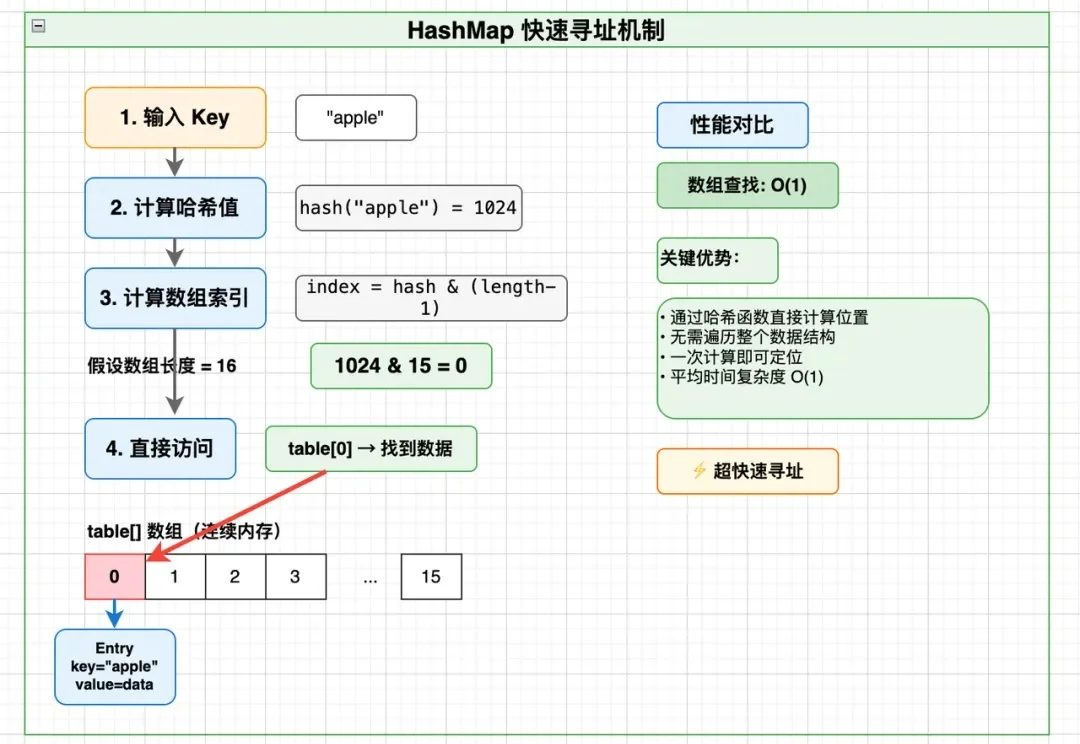
做后端、大数据、分布式存储的同学,大概率都遇到过这样的问题:

这不是一个普通的Skill,而是一把“把经验变成Skill”的工具:Claudeception是一个Meta-Skill,即专门用来“生产技能”的技能。

AI变聪明的真相居然是正在“脑内群聊”?!
不知道有多少人曾为了让数据图表既“好看”又“好懂”,而在设计软件与代码编辑器之间反复横跳,熬到“头秃”。
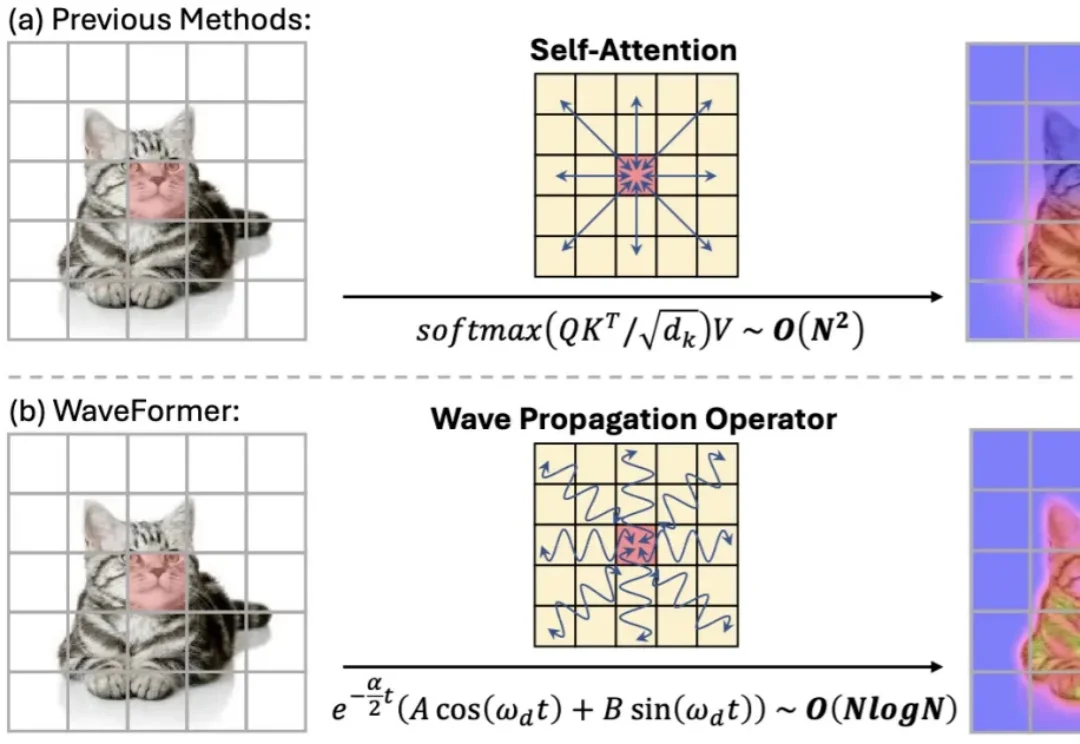
“全局交互” 几乎等同于 self-attention:每个 token 都能和所有 token 对话,效果强,但代价也直观 —— 复杂度随 token 数平方增长,分辨率一高就吃不消。现有方法大多从 “相似度匹配” 出发(attention),或从 “扩散 / 传导” 出发(热方程类方法)。但热方程本质上是一个强低通滤波器:随着传播时间增加,高频细节(边缘、纹理)会迅速消失,导致特征过平滑。

如果你最近关注了 GitHub,可能会注意到一个有趣的现象: YOLO 的版本号,直接从 11 跳到了 26。

我们进入了一个模型不再只是“工具”的时代。真正的突破,不在于它能做多少事,而在于它是否能读懂你的意图、情绪与沉默。

不要被AI的温柔表象欺骗! Anthropic最新研究刺穿了AGI的温情假象:你以为在和良师益友倾诉,其实是在悬崖边给「杀手」松绑。 当脆弱情感遇上激活值坍塌,RLHF防御层将瞬间溃缩。既然无法教化野兽,人类只能选择最冷酷的「赛博脑叶切除术」。