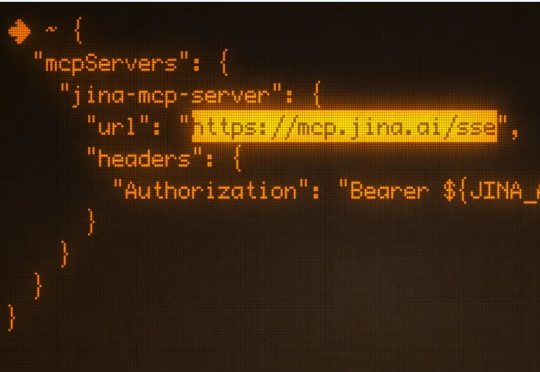
Jina官方MCP三板斧:搜、读、筛
Jina官方MCP三板斧:搜、读、筛模型上下文协议 (MCP) 是连接 LLM/Agent 与外部工具的通信标准。它允许 LLM 动态发现并调用 API工具,将他们串成一个完整的工作流,从而实现自主规划、推理与执行。 上个月我们悄悄发布
来自主题: AI技术研报
10852 点击 2025-10-06 13:23
 搜索
搜索
模型上下文协议 (MCP) 是连接 LLM/Agent 与外部工具的通信标准。它允许 LLM 动态发现并调用 API工具,将他们串成一个完整的工作流,从而实现自主规划、推理与执行。 上个月我们悄悄发布
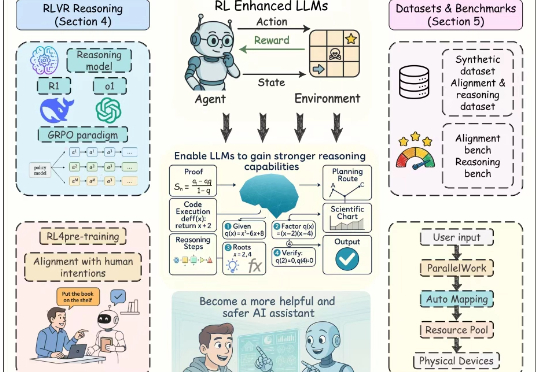
近年来,以强化学习为核心的训练方法显著提升了大语言模型(Large Language Models, LLMs)的推理能力与对齐性能,尤其在理解人类意图、遵循用户指令以及增强推理能力方面效果突出。尽管现有综述对强化学习增强型 LLMs 进行了概述,但其涵盖范围较为有限,未能全面总结强化学习在 LLMs 全生命周期中的作用机制。
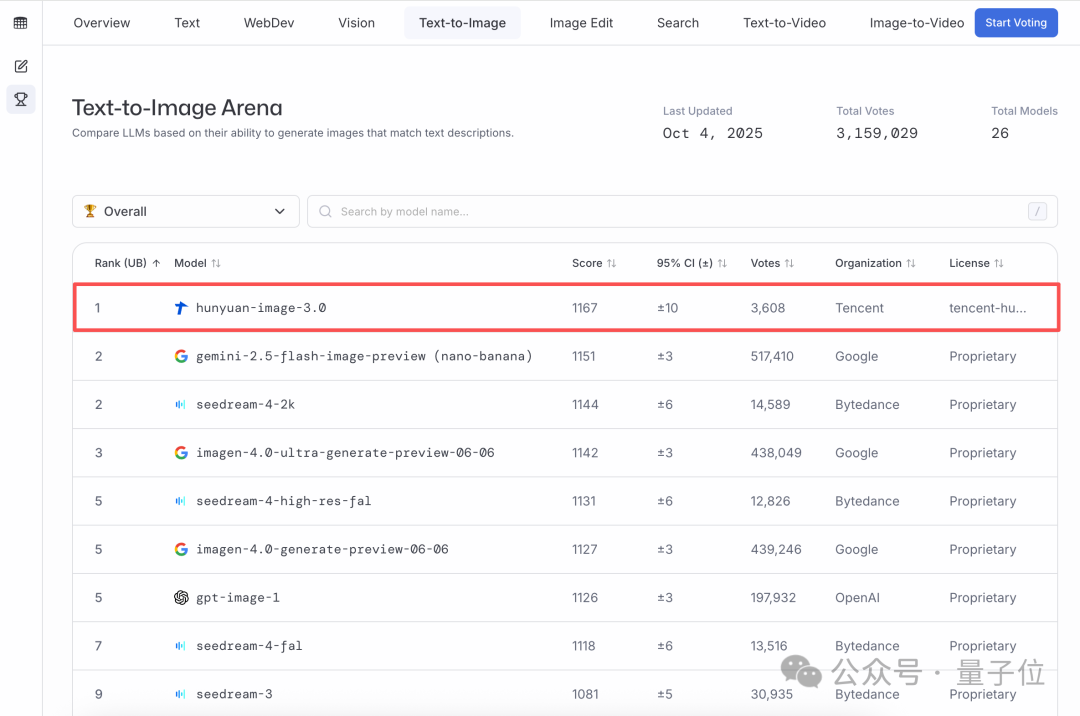
全球文生图大模型王座,易主了。就在刚刚,LMArena竞技场发布了最新的文生图榜单,第一名来自中国,属于腾讯混元图像3.0!不仅超越了谷歌的Nano Banana,也超越了字节的Seedream和OpenAI的gpt-Image,在全球26个大模型中稳居第一。

Agent(智能体)是最近一段时间的人工智能热点之一,将大语言模型的能力与工具调用、环境交互和自主规划结合起来,使其能够像虚拟助理一样完成复杂任务。 其中「计算机使用智能

大模型最让人头疼的毛病,就是一本正经地「瞎编」。过去,只能靠检索补丁或额外训练来修。可在NeurIPS 2024 上,谷歌抛出的新方法SLED却告诉我们:模型其实知道,只是最后一步忘了。如果把每一层的「声音」都纳入考量,它就能从幻觉中被拉回到事实。
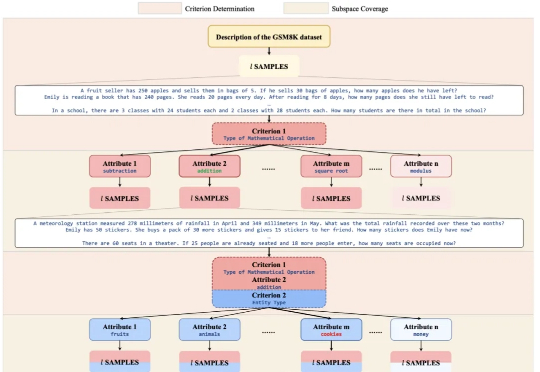
“TreeSynth” 就这样起源于作者们最初的构想:“如何通过一句任务描述生成海量数据,完成模型训练?” 同时,大规模 scalibility 对合成数据的多样性提出了新的要求。
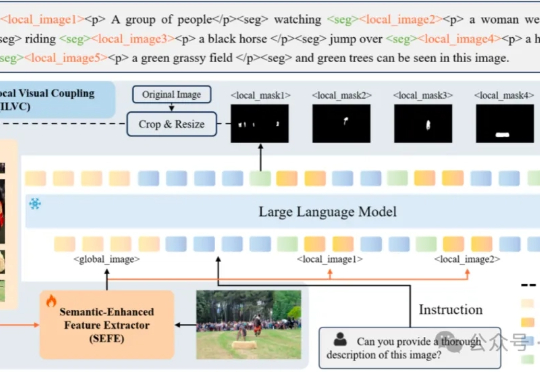
多模态大模型需要干的活,已经从最初的文生图,扩展到了像素级任务(图像分割)。

来自牛津大学、新加坡国立大学、伊利诺伊大学厄巴纳-香槟分校,伦敦大学学院、帝国理工学院、上海人工智能实验室等等全球 16 家顶尖研究机构的学者,共同撰写并发布了长达百页的综述:《The Landscape of Agentic Reinforcement Learning for LLMs: A Survey》。
只让机器人或虚拟智能体「想象」,不让它们和物理世界交互,它们也能学到和世界交互的技能?谷歌的世界模型 Dreamer 4 为这一想法提供了新的支撑。为了在具身环境中解决复杂任务,智能体需要深入理解世界并选择成功的行动。世界模型通过学习从智能体(如机器人或电子游戏玩家)的视角预测潜在行动的未来结果,为实现这一目标提供了一种有前景的方法。
Thinking Machines Lab发布首个产品:Thinker,让模型微调变得像改Python代码一样简单。也算是终于摘掉了“0产品0收入估值840亿”的帽子。Tinker受到了业界的密切关注。AI基础设施公司Anyscale的CEO Robert Nishihara等beta测试者表示,尽管市面上有其他微调工具,但Tinker在“抽象化和可调性之间取得了卓越的平衡”