# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
模型上下文协议 (MCP) 是连接 LLM/Agent 与外部工具的通信标准。它允许 LLM 动态发现并调用 API工具,将他们串成一个完整的工作流,从而实现自主规划、推理与执行。
上个月我们悄悄发布了官方 MCP 服务器 (GitHub:https://github.com/jina-ai/MCP) 将 Jina AI 的核心能力,包括 Jina Reader、Embeddings 和 Reranker API 封装成了一套覆盖网页内容读取、网页学术图片搜索和语义去重的LLM工具集,并支持Cursor, Claude Code, OpenAI Codex多种使用方式。
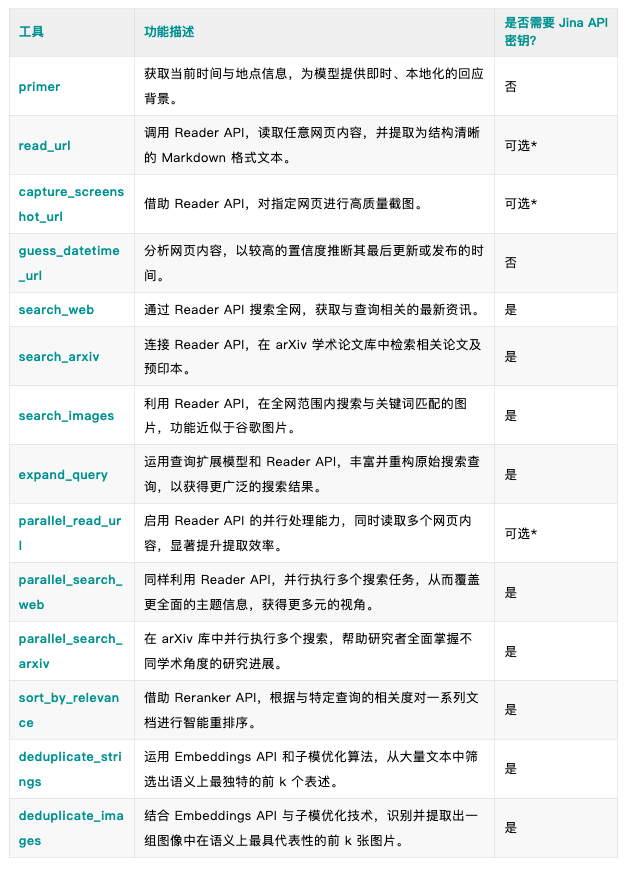
注:标记为“可选”的工具没有 API 密钥也可以运行,但会受限于速率。如果您需要更高的请求速率和更优的性能,请前往 https://jina.ai 免费申请 Jina API Key,并配置使用。
作为一个通用插件系统,我们的 MCP 也可以接入 VS Code、Claude Code、Google Gemini CLI 以及 Claude 和 ChatGPT 的桌面客户端等各种应用。
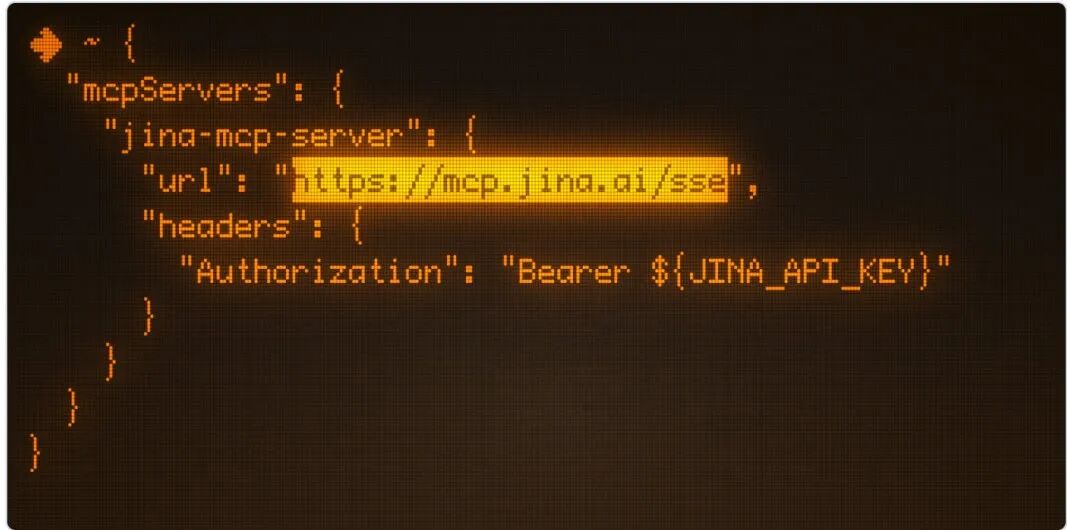
1.对于支持远程 MCP 的客户端:
{ "mcpServers": { "jina-mcp-server": { "url": "https://mcp.jina.ai/sse", "headers": { "Authorization": "Bearer ${JINA_API_KEY}" // 可选,前往 https://jina.ai 免费获取 } } }}
2.对于尚不支持远程 MCP 的客户端: 您需要通过本地代理 mcp-remote 来连接远程服务器。
{ "mcpServers": { "jina-mcp-server": { "command": "npx", "args": [ "mcp-remote", "https://mcp.jina.ai/sse", // 可选,Key 可前往 https://jina.ai 免费获取 "--header", "Authorization: Bearer ${JINA_API_KEY}" ] } }}
3.在 Claude Code 中配置:
claude mcp add --transport sse jina https://mcp.jina.ai/sse \ --header "Authorization : Bearer ${JINA_API_KEY}"
4.在 OpenAI Codex 中配置: 编辑 ~/.codex/config.toml 文件,添加以下配置:
[mcp_servers.jina-mcp-server]command = "npx"args = [ "-y", "mcp-remote", "https://mcp.jina.ai/sse", "--header", "Authorization: Bearer ${JINA_API_KEY}"]
在 LMStudio 中,如果选用 gpt-oss-120b 或 qwen3-4b-thinking 这类具备思考能力的模型,且默认上下文窗口仅为 4096,就容易触发此问题。
因为随着思考与工具调用链的不断延长,一旦超出上下文窗口限制,模型就会忘记任务的初始指令,从而陷入无限循环。
要解决这个问题,只需在加载模型时,设置一个足以容纳完整调用链与思考过程的上下文长度。
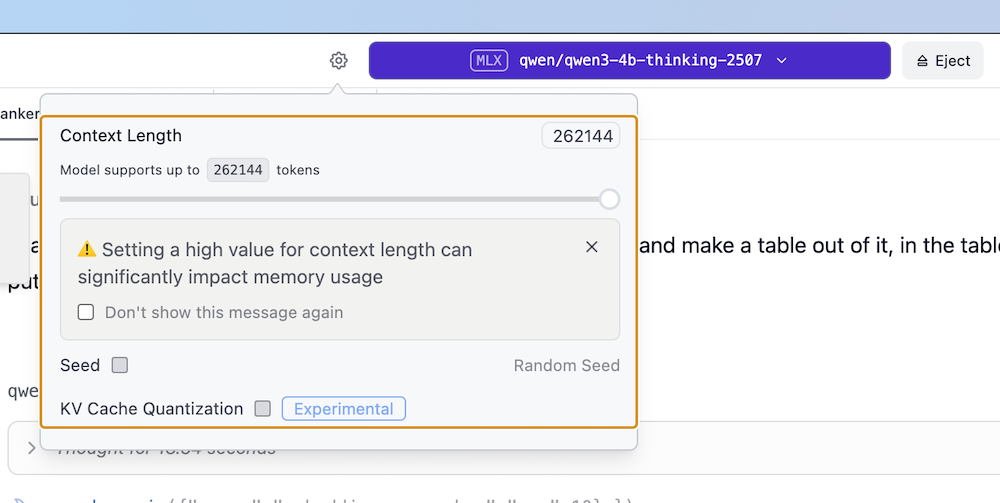
设置足够长的上下文窗口
有些 MCP 客户端会缓存工具定义,而且不会主动刷新。如果您发现工具列表不完整或版本陈旧,就需要手动刷新缓存。
具体操作是,在客户端配置中移除 jina-mcp-server 再重新添加,强制客户端拉取最新的工具定义。在 LMStudio 中,您也可以直接点击刷新按钮来更新。
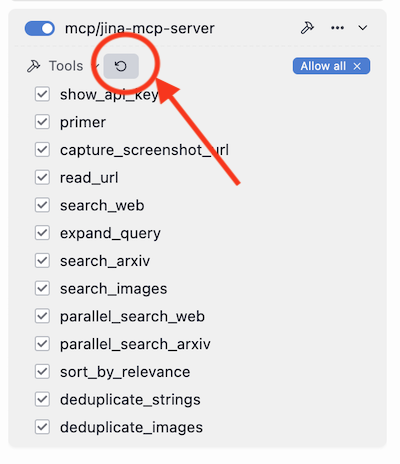
更新本地 MCP 客户端
这是因为 Cursor 和 Claude Desktop 的 Windows 版本存在一个 Bug:调用 npx 时,不会转义 args 参数中的空格,导致命令解析出错。
要绕开此问题,您可以将包含空格的鉴权信息移至环境变量中,从而避免直接在 args 里解析。
{ // ... 其他配置"args": [ "mcp-remote", "https://mcp.jina.ai/sse", "--header", "Authorization:${AUTH_HEADER}"// 注意 ':' 两侧不要有空格 ],"env": { "AUTH_HEADER": "Bearer <JINA_API_KEY>"// 在环境变量中则可以安全地使用空格 }}
这很可能是 Cursor 的一个界面显示 Bug,通常 MCP 服务本身仍在正常运行。如果您觉得红点提示很干扰,可以尝试关闭再重新开启 MCP 服务来“重启”。
需要说明的是,由于您连接的是远程 MCP,此操作只会重启本地代理,而非远程服务器。

Cursor 显示红点
即便在客户端中启用了所有工具,有时也会发现模型倾向于使用某些工具,而忽略了另一些。这是个普遍现象,因为大部分 LLM 在训练时接触的工具集有限。
比如除非明确指令,模型很少自发调用 parallel_* 版本的工具。有研究也指出,模型必须经过专门的训练才能有效利用并行调用。像 Qwen3-Next 这类模型,则倾向于调用单一工具接口,但在一次调用中传入一个包含多个查询的数组,以此实现并行(我们的 MCP 也支持这种模式)。
想要引导模型更充分地使用所有工具,您可以在 Cursor 的 .mdc 文件中添加以下规则:
---alwaysApply: true---当你不确定相关知识,或者用户质疑你的回答时,必须使用 Jina MCP 工具搜索和阅读最新信息与最佳实践。如果问题涉及深度学习理论或算法细节,应组合使用 search_arxiv 和 read_url。search_web 与 search_arxiv 不能单独使用,必须搭配 read_url 或 parallel_read_url 从多个信源获取信息。记住:每次搜索都必须跟上 read_url 操作来读取源网页内容。为追求最高效率,可在必要时调用 parallel_* 版本的搜索和读取工具。
配置都顺利完成后,我们接下来通过三个实际案例,体验用 Jina AI MCP 搭建工作流的实际效果。
工程师每天需要跟进大量学术论文,但筛选和提炼信息耗时耗力。我们尝试让 Agent 自动化这个流程,生成每日论文摘要。我们设计的提示词如下:
* Searches for relevant [arxiv.org](http://arxiv.org/) papers (using the `parallel_search_arxiv` tool) with the query strings `large language models LLM`, `reranking information retrieval`, `embeddings vector representations`, `transformer neural networks` and `natural language processing NLP`* Removes duplicates (using the `deduplicate_strings` tool)* Reranks the results (using `sort_by_relevance` tool), outputting only the ten most relevant results.* Retrieves the URLs to the PDFs for the reranked results (using `parallel_read_url`), split into two batches of five.* Reads each URL (using the `read_url` tool, called ten times)* Generates a detailed [report](https://gist.github.com/alexcg1/9bec8b86849d48d45a56add8a55061d0), including abstracts, summaries, trends, and insights, implications for future research, research gaps, and conclusions.
💡 因为 VS Code 内置了搜索功能,我们在提示词中明确“仅使用 Jina 工具”,以确保 Agent 只调用我们的工具集。
收到指令后,Agent 随即启动了工作流:
parallel_search_arxiv,围绕 reranking information retrieval、embeddings vector representations 等多个主题词,在 arXiv 上并发搜索。deduplicate_strings 清除重复的论文条目,再通过 sort_by_relevance 按相关性排序,筛选出最重要的前十篇。parallel_read_url 获取论文的 PDF 链接,再用 read_url 逐一解析全文。在测试中,我们发现 Agent 有时会忽略“过去 24 小时”的时间限制。只需再次强调该指令,它就能修正行为并生成准确的报告。
准确把握竞品动态是制定市场策略的关键。我们来挑战一个商业场景:让 Agent 自动完成一份竞品情报报告。我们要求它为一家游戏公司写一份竞品分析报告:
Create a comprehensive competitive intelligence report for$GAME_COMPANY focusing on their recent activities in retroindie games.Use Jina tools to search for the latest news,- press releases, and announcements, then extract clean content- from their official communications. Rank all findings bybusiness relevance and remove any duplicate information.- Present insights on their strategic direction, productlaunches, and market positioning changes over the pastquarter
Agent 接到指令后,自动化地执行了以下流程:
search_web 和 read_url,在全网广泛搜索并深入读取原始网页。sort_by_relevance,对信息进行商业价值评估和排序,筛选出最重要的十条情报。MCP 的开放性允许我们串联多个独立的 MCP 服务器,构建更强大的工作流。在这个示例中,我们组合了 Jina MCP 服务器和一个 PDF 阅读器的 MCP:https://github.com/sylphxltd/pdf-reader-mcp,目标是生成一份关于欧美 AI 法律合规的研究报告。
指令如下:
Develop a knowledge base section focused on AI legalcompliance news and common pitfalls in the EU and USA as ofthis moment. Report should be aimed at AI startups in EU.Apply Jina MCP tools extensively: perform parallel websearches and URL reads to efficiently extract detailedcontent, deduplicate semantic overlaps, and rerank to surfacethe most authoritative information. Cite all sources withURLs and publication or update dates. Organize contentclearly and produce a formatted PDF document ready forimmediate use.
Agent 随即启动了一个多阶段的深度研究任务:
parallel_search_web,围绕 EU AI Act 2024 等多个长尾关键词,同时发起五路并行搜索,每个查询取回 25 个结果,来实现广度覆盖。deduplicate_strings 对数百个 URL 进行去重,再调用 parallel_read_url 深入读取最相关的网页。parallel_search,使用更具针对性的查询(如 AI bias discrimination testing)挖掘细节。parallel_read_url,读取与新主题高度相关的另外四篇网页。在初次生成后,我们通过追加提示词对 PDF 的元数据和排版进行了微调。这些优化提示词也可以直接整合进初始提示词中,实现一步到位。
在最终选定 Claude Sonnet 4 之前,我们评估了一系列支持工具调用的本地模型方案,包括通过 Ollama 运行的 Qwen3:30b、Qwen2.5:7b 和 Llama3.3:70b,并短暂使用过 ollmcp 客户端,后面才切换到 VS Code。
但所有被测的本地模型均暴露出一个统一的、无法通过提示工程解决的失败模式。即便是处理“获取 Jina AI 最新博客”这种简单任务,它们也经常暴露以下错误:
read_url 抓取新闻列表页 (https://jina.ai/news)。read_url 读取了目标文章的全文,但实际上并未发起该 API 请求。相比之下,Claude、GPT 和 Gemini 系列的闭源模型则能够可靠地完成任务。我们最终选定 Claude Sonnet 4,主要基于其卓越的工具调度能力:它倾向于并行执行工具(而 GPT-4.1 等模型更偏好串行),这使得其任务处理效率更高,生成的输出结构也更为完整和清晰。
根据我们的实践,当前 Agent 的能力瓶颈主要在于 LLM 本身,实际应用中还是需要通过精巧的提示工程 (prompt engineering) 和反复的人工调试来校准其行为。
然而,一旦为 Agent 配置了最优的“提示词 + LLM + MCP 服务器”组合,它就能稳定地自主执行多步骤的复杂任务,而无需编写任何胶水代码 (glue code)。这就与过去依赖手动工程、集成方案脆弱的开发模式形成了鲜明对比。
MCP 的核心价值在于其开放的生态系统。它允许开发者像搭积木一样,将 Jina AI API 这类工具模块化地组合起来,并在未来轻松替换更强大的 LLM。随着模型能力与工具生态的共同成熟,从实验原型到生产级的 Agent 工作流,这条路径正变得更加清晰和可行。
文章来自于微信公众号 “Jina AI”,作者 “Jina AI”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
