# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多模态大模型需要干的活,已经从最初的文生图,扩展到了像素级任务(图像分割)。
不过,无论是OMG-LLaVA,还是提出了embedding-as-mask范式的LISA(CVPR 2024),都还存在分割结果不够精确,以及理解过程中出现幻觉两大痛点。
这主要源于现有模型在物体属性理解上的不足,以及细粒度感知能力的局限。
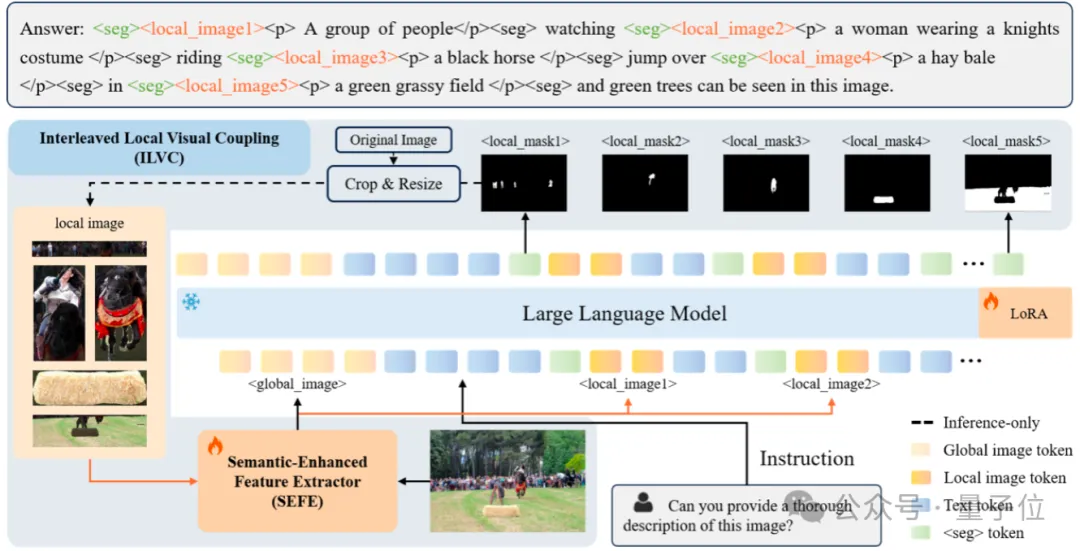
为缓解上述问题,华中科技大学团队和金山办公团队联合提出了两个核心模块:
语义增强特征提取器(SEFE)和交错局部视觉耦合(ILVC)。
前者融合语义特征与像素级特征,提升物体属性推理能力,从而获得更精确的分割结果。
后者基于分割掩码提取局部特征后,自回归生成局部描述,为模型提供细粒度监督,从而有效减少理解幻觉。
最终,研究团队构建了在分割和理解两项任务上均取得SOTA的多模态大模型LIRA。

与InternVL2相比,LIRA在保持理解性能的同时,额外支持图像分割任务;与OMG-LLaVA相比,LIRA在图像分割任务上平均提升8.5%,在MMBench上提升33.2%。
目前,LIRA项目已被ICCV 2025录用。
通过将分割模块和多模态大模型结合,多模态大模型的能力已从视觉理解拓展至像素级分割。
LISA(CVPR 2024)首次提出“embedding-as-mask”范式,通过引入 token解锁了分割能力。
OMG-LLaVA 则采用通用分割模型作为视觉编码器,并将图像特征与感知先验融合,从而在分割与理解任务上实现更优的协同表现。
尽管现有方法已取得显著进展,但在复杂场景下仍常常无法准确分割目标。
下图Figure 2中,OMG-LLaVA就未能正确分割出“最靠近白色汽车的红色公交车”。

为探究分割错误的原因,研究团队提取了多模态大模型在第一列图像上生成的token embedding,并直接用于第二列和第三列图像的分割。
有趣的是,在 (1) 行的所有图像中,左侧公交车始终被分割出来,这表明 token可能包含了与原图像无关的语义信息。
进一步分析token的logits发现,与“left”相关的值显著偏高,从而导致左侧公交车被分割出来。
研究团队推测,产生分割错误的原因是多模态大模型在token中未能有效编码准确的位置信息,反映其视觉理解能力存在局限。
此外,现有方法通常依赖位置查询来指示目标位置,但并不能在局部描述与对应图像区域特征之间建立明确联系,从而可能引发幻觉。
这引出了一个重要问题:
是否应直接将局部图像特征输入文本大模型,让模型基于该区域生成描述,从而在视觉特征与语义之间建立更明确的映射?
依循这个思路,研究团队提出了同时支持理解和分割任务的多模态大模型LIRA。
如下面Figure 2所示,研究团队进一步分析了token的logits。
结果表明,当“right”对应的logits更高时右边的bus被分割出,“left”对应的logits更高时,左边的bus被分割出,这可能表明 token实际上包含了被分割物体丰富的语义信息。
LIRA能够准确地将诸如“离白色汽车最近的红色巴士”等查询解释为指向“右边的巴士”,从而实现精确分割。
这个过程涉及根据用户query和图像信息来理解物体属性,以实现准确的分割,研究团队称之为“Inferring Segmentation”。
这一定义可能与LISA Reasoning Segmentation中所使用的定义有所不同,后者依赖于外部世界知识或常识来对隐式查询(例如,“请分割图中富含维生素C的食物”)进行推理。
此外,研究者还提出了语义增强特征提取器(SEFE)和交错局部视觉耦合机制(ILVC),旨在提升多模态大模型分割精度和缓解理解幻觉。
SEFE通过融合高层语义信息与细粒度像素特征,增强模型的属性理解能力从而提高分割性能。
ILVC通过显式绑定局部图像区域与对应文本描述,为多模态大模型提供更细粒度的监督,从而缓解幻觉现象。
该模块融合了来自预训练多模态大模型的语义编码器和分割模型的像素编码器。
给定全局图像,语义编码器和像素编码器分别提取特征,经过多层感知机(MLP)转换为相同维度的特征:
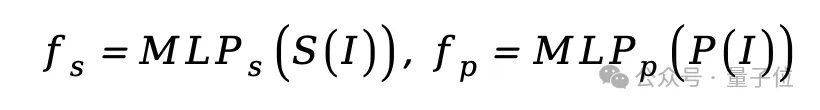
随后,利用多头交叉注意力融合语义特征和像素特征:

最终将融合后的特征拼接为全局特征后送入LLM中:
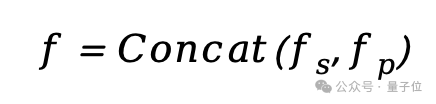
在多模态大模型中,将局部特征与对应的局部描述对齐对于精确理解目标至关重要。
然而现有的方法(Figure 4(a))通常仅提取 token处的embedding,将其输入解码器生成分割掩码。
这种方法并未明确地将局部图像区域与其对应的文本描述直接关联。
受到人类的感知通常是先关注感兴趣的区域,再进行描述的启发,本文提出了交错局部视觉耦合模块帮助将局部图像区域与对应的文本描述进行耦合(Figure 4(b))。
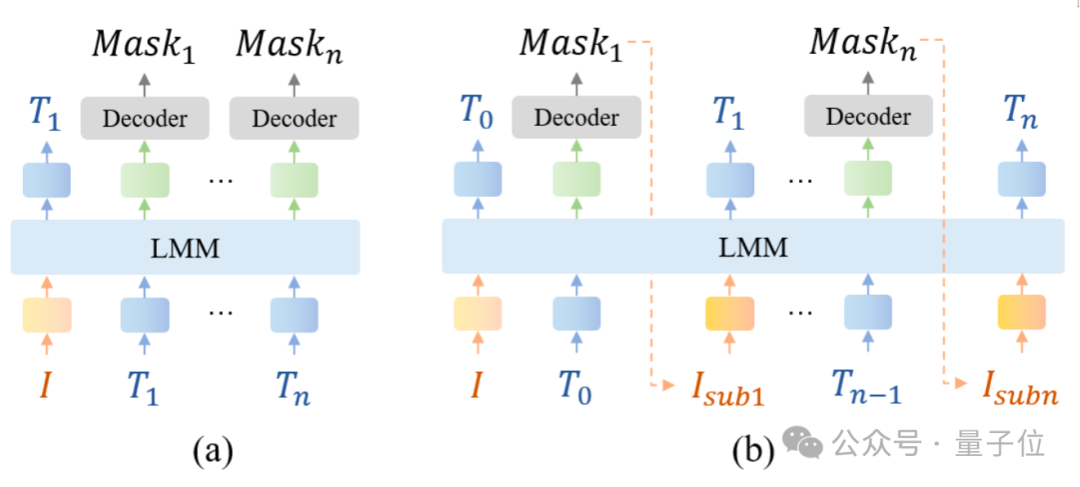
具体而言,LIRA使用token生成分割掩码,基于该掩码从原始图像中裁剪出对应区域,并将裁剪区域调整为448 x 448大小后输入SEFE提取局部特征。
随后,将编码后的局部特征重新输入文本大模型,以生成该图像区域的描述并预测后续内容。
通过这种交错的训练范式,ILVC模块成功建立了局部图像区域与文本描述的显式联系,为局部图像特征引入了细粒度监督,从而缓解了幻觉。
实验结果表明,LIRA能够同时支持理解和分割任务,并且在多个理解和分割数据集上取得了不错的性能。

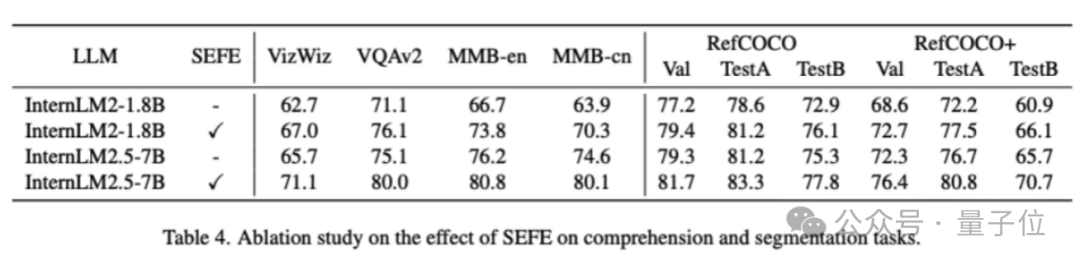
为验证SEFE的有效性本文基于InternLM2-1.8B和InternLM2.5-7B骨干网络进行了消融实验。
结果显示,采用InternLM2-1.8B时,整合SEFE在理解任务上平均提升5.7%,分割任务提升3.8%。
采用InternLM2.5-7B时,理解任务和分割任务的平均提升分别为5.1%和3.4%。
在SEFE的基础上,本文进一步验证整合ILVC的效果。
结果表明,采用ILVC后,在数据集ChairS上,1.8B和7B规模的模型幻觉率分别降低了3.0%和4.8%。

将LIRA同时用理解数据和分割数据进行联合训练,性能仅较单独用理解数据训练略微下降0.2%,优于先前最佳方法OMG-LLaVA在五个理解数据集上近15%的性能下降。
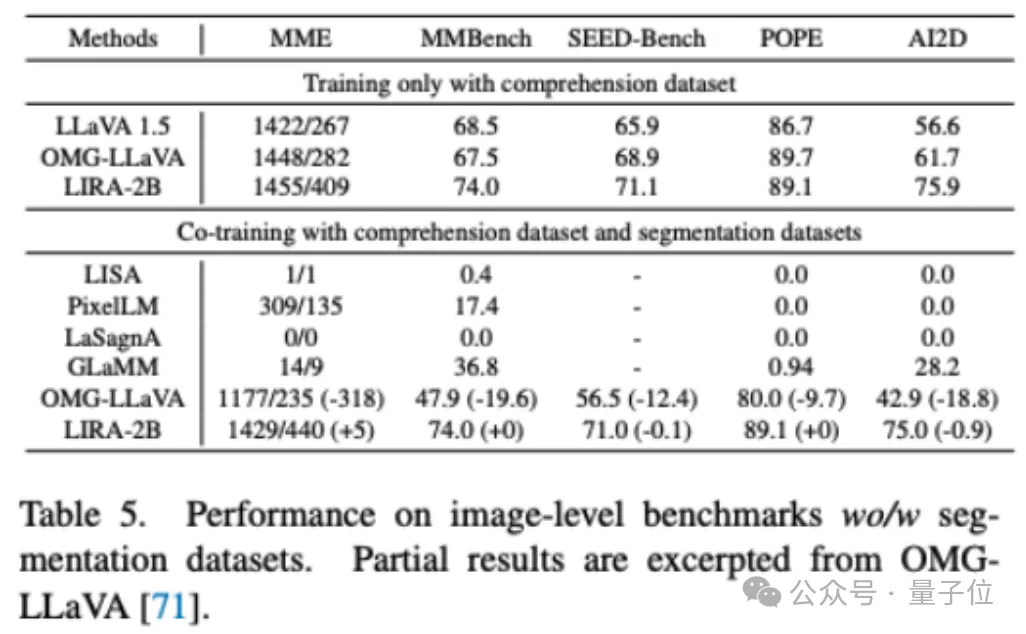
综上,丰富的实验结果验证了LIRA在多个理解与分割基准上的优异表现。
此外,研究团队还在论文中探讨了token在分割任务中的作用,发现其logits能够准确反映被分割物体的属性,推测其可能蕴含更丰富的物体语义信息。
未来研究中,深入探索文本与视觉token之间的关联,可能为提升多模态大模型的理解和分割能力带来新的启发。
总体而言,LIRA实现了理解与分割任务性能的协同提升,提出了在细粒度多模态大模型中缓解幻觉的新视角,并将分割多模态大模型中token的语义内涵纳入研究视野,可能为后续相关探索提供了启示。
arXiv:
https://arxiv.org/abs/2507.06272
GitHub:
https://github.com/echo840/LIRA
文章来自于微信公众号“量子位”。


