# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型最让人头疼的毛病,就是一本正经地「瞎编」。过去,只能靠检索补丁或额外训练来修。可在NeurIPS 2024 上,谷歌抛出的新方法SLED却告诉我们:模型其实知道,只是最后一步忘了。如果把每一层的「声音」都纳入考量,它就能从幻觉中被拉回到事实。
十几年来,我们见证了大模型一次次刷新能力上限——写文章、写代码、写诗通通不在话下。
可问题是,它们往往一本正经地胡说八道:温哥华成了不列颠哥伦比亚的首府,走进壁炉还能瞬间传送……
这种「幻觉」几乎成了AI的原罪。
很多人以为,这是模型根本不知道。但Google Research在NeurIPS 2024上提出的SLED(Self Logits Evolution Decoding)却揭示了一个颠覆性事实:
大模型其实知道答案,只是最后一步给忘了。

论文地址:https://arxiv.org/html/2411.02433v3?utm_source
项目主页:https://github.com/JayZhang42/SLED
原来,在模型内部,早期层早就提示了正确答案,只是在最后一层被带偏。
而SLED的妙处,就是让所有层次的声音都被听到,一起决定结果。
这意味着,大模型或许并不需要外部检索、额外训练,就能把自己的幻觉率降下来。
在我们日常用AI的时候,有一个老梗常被提起:问它「不列颠哥伦比亚的首府是哪座城市?」,它往往答「温哥华」。可真正的答案是「维多利亚」。
这种自信却错误的输出,就是所谓的「AI幻觉」。
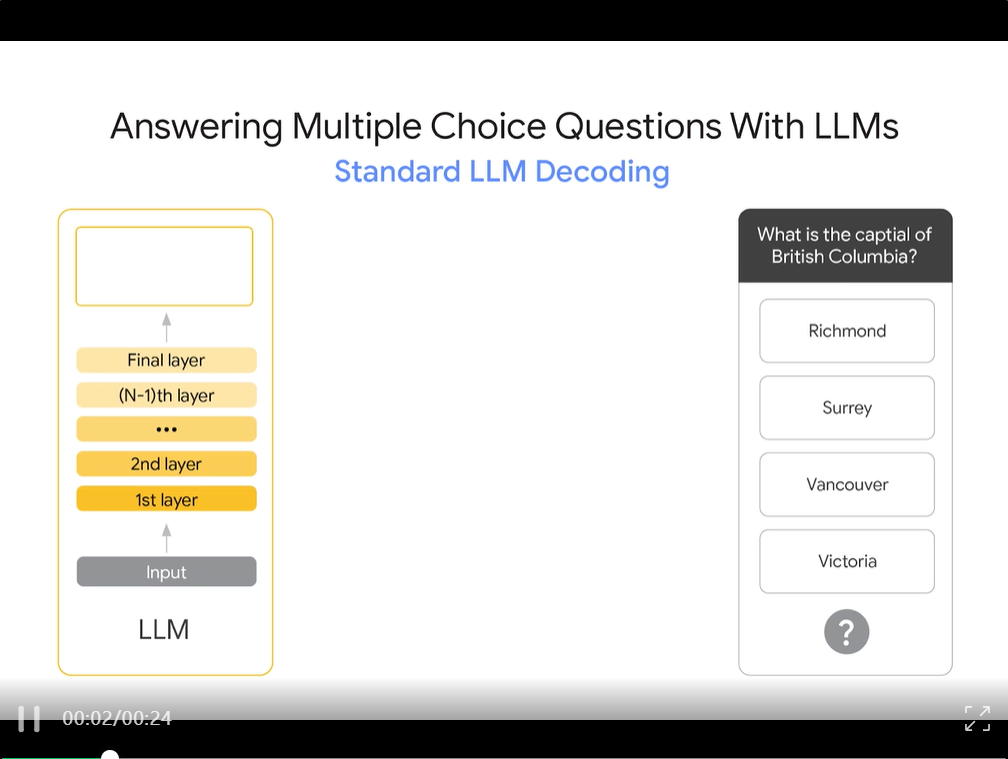
演示SLED在回答多项选择题时如何改进标准LLM 解码。通过使用来自所有层的信息,SLED+LLM会得出正确答案(维多利亚州),而不是不列颠哥伦比亚省更知名的城市(温哥华)
这类「AI幻觉」案例并不少见,也让人对大模型的可靠性打不少问号。
这意味着,它在医疗、法律、教育这些关键场景里可能造成严重后果——错误的判断、误导性的结论、甚至损害信任。
研究者早已指出,幻觉是大模型应用的系统性挑战,并开发了像TruthfulQA这样的基准来专门测试事实性。
传统的修复路径,通常是依赖外部检索(RAG)、或者让模型去查数据、用知识库、再结合微调。
这些方法虽然有效,但代价高,系统复杂: 检索有时慢、检索结果可能不准确,知识库也要维护,微调则需要标注/资源。
最近,谷歌的研究团队在NeurIPS 2024发布了一个新方法叫SLED(Self Logits Evolution Decoding),目标是:不依赖外部知识,不再额外微调,而是让模型自己用好内部的知识,减少幻觉。

原因在于模型生成答案时,每一层都会产生对下一个词的预测(logits)。
但传统方法只看最后一层,容易被训练语料里最常见的模式牵着走,从而忽视掉中间层里更接近事实的信号。
而SLED的关键点,则是把所有层的预测都纳入考量,再通过权重融合得出结果。
这样,当最后一层倾向于「套路答案」时,其他层提供的补充信息能把模型拉回到更符合事实的方向。
传统大模型在解码时,往往只依赖最后一层的预测结果。
但研究团队发现,这一步可能过于「武断」:最后一层倾向于给出训练语料里最常见的答案,而忽略了中间层已经蕴含的更准确信息。
研究团队这样定义SLED:
SLED的框架通过对比早期层与最终层的logits,挖掘模型中潜藏的知识,并利用一种近似梯度的方法,让这些潜在知识引导输出的自我修正,从而提升事实准确性。
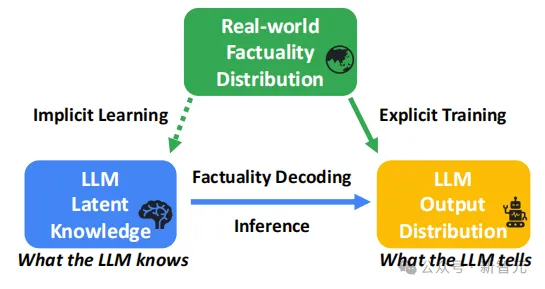
幻觉产生的根源在于模型「知道的」和「说出来的」之间存在差距。
模型在训练中可能已经隐式学到事实性知识,但推理时输出的分布仍可能出现偏差,这就是幻觉的来源。
SLED的目标,就是在解码阶段弥合这两者的差距。
它的做法,是把中间层的预测结果也统一到同一词表上,再与最后一层加权融合。
这样就能利用「层与层之间的差异」,让模型不再只听一个声音。
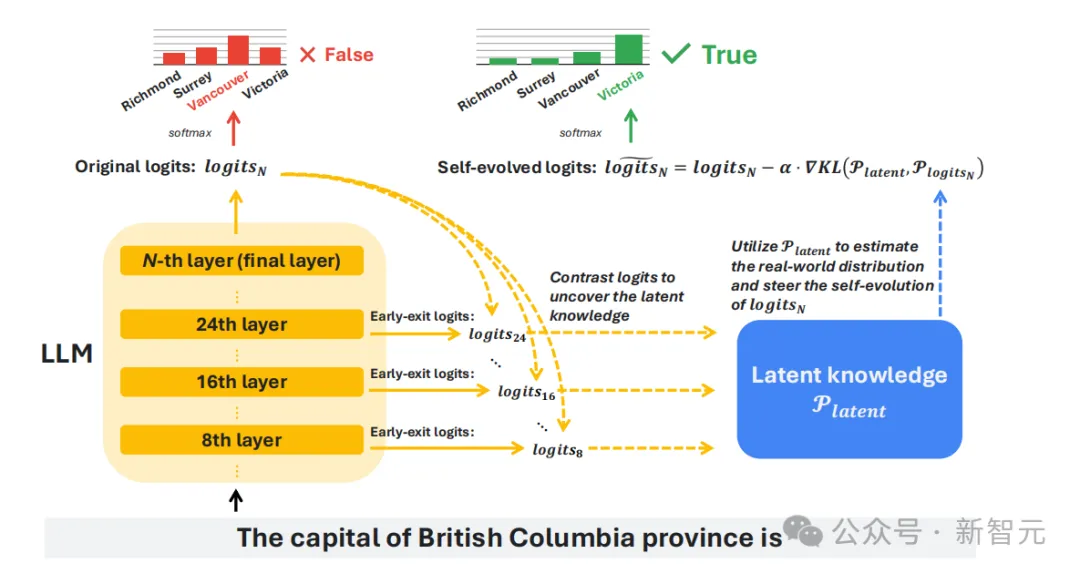
SLED工作流程。对比早期层与最终层的logits,得到潜在分布,再修正最终层的输出,使结果更接近真实。
以一个简单的算术题为例:
Ash买了6个玩具,每个10个币,买4个以上能打九折,一共要付多少钱?
普通模型常常输出「6×10=60」。
但SLED在中间层发现有不少预测倾向于加上「×0.9」,于是修正出正确答案54。

SLED利用中间层线索修正输出,让模型避开常见错误,得到更准确的答案。
再看看更复杂的算术问题:
Eliza每小时10美元,每周前40小时正常工资,超过部分按1.2倍计算。她工作45 小时,一周收入是多少?
普通模型常常答 450 美元,而忘了1.2倍的加班费,而SLED借助中间层提示,把结果修正为正确的460美元。
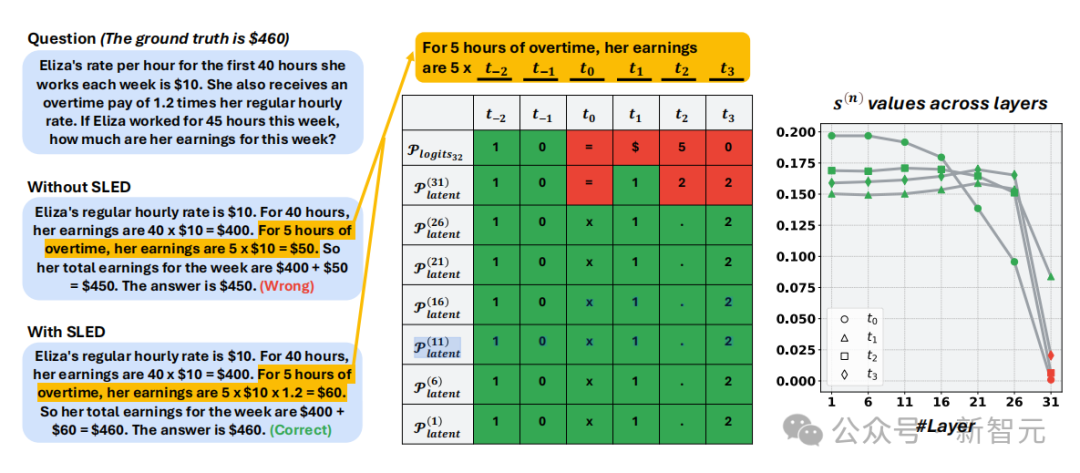
GSM8K工资计算案例。普通模型输出错误的$450,而SLED利用中间层信号修正为正确的$460。
通过这种方法,SLED不需要改变模型结构,也不需要额外训练,就能在解码阶段把这些「差点被忘掉的知识」利用起来。
这项研究来自Google Research团队。
第一作者是Jianyi Zhang,还在读书,就已经在顶会上挂名核心作者。

团队里也不乏老牌大牛:研究科学家Cyrus Rashtchian、研究主管Da-Cheng Juan以及在机器学习和系统优化方向深耕多年的Chun-Sung Ferng、Heinrich Jiang、Yiran Chen。
他们把这项成果带到了NeurIPS 2024,并顺手把代码开源在GitHub上,希望能让更多人用得上。
而为了证明这套方法不是纸上谈兵,团队还在一系列模型上做了全面测试。
如果说SLED的原理听起来还略显抽象,那么实验结果就足够直观了。
研究团队把它放在多个开源模型上做了系统实验,包括Gemma-3、Qwen-3、Mixtral和GPT-OSS。
既覆盖了最小的1B模型,也覆盖了20B、27B这种更大规模的模型。
结果显示:无论模型大小、家族类型,SLED都能显著减少幻觉。
在Gemma-3系列上,表现尤其亮眼。
1B-PT模型在FACTOR数据集上的准确率只有47.83%,而引入SLED后直接飙升到 63.29%;
Gemma-3 27B-IT在TruthfulQA MC1上也从41.14%提升到47.47%,比当时的最佳方法 DoLa高出整整10个百分点。
从最小的1B到最大的27B,SLED都带来了稳定的提升。
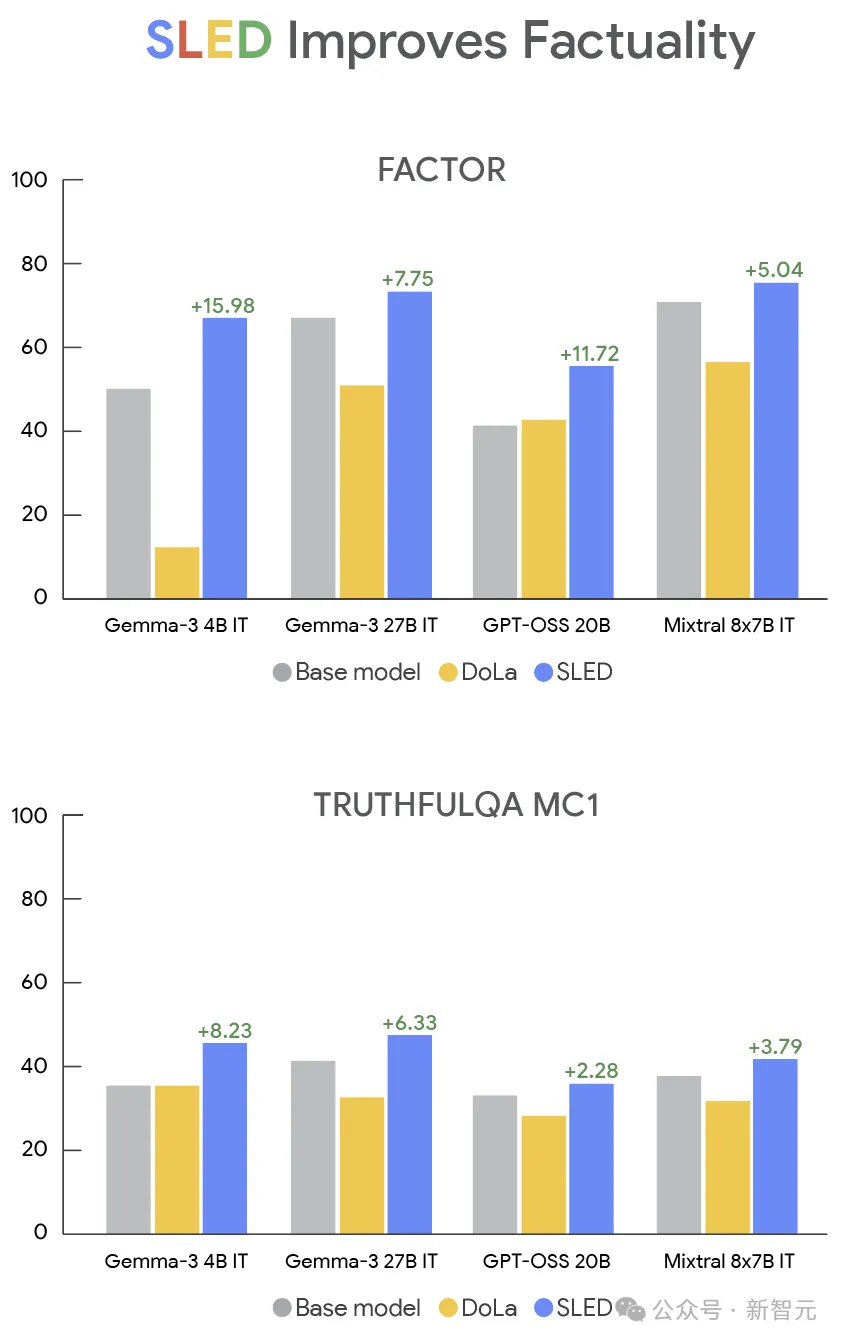
Gemma-3系列不同规模模型在FACTOR和TruthfulQA上的表现。SLED在所有规模和训练类型下均优于基线和DoLa
不仅如此,跨家族测试同样说明了SLED的稳健性。
在GPT-OSS 20B上,FACTOR分数从41.12%提升到55.31%;在Mixtral-8×7B-IT 上,从70.51%提升到75.55%;就连Qwen-3-14B这样的模型,在TruthfulQA MC1上也能从38.10% 稳定升到40.00%。
相比之下,DoLa在这些模型上的表现并不稳定,有时甚至比基线更差,而SLED几乎在所有场景下都能保持领先。
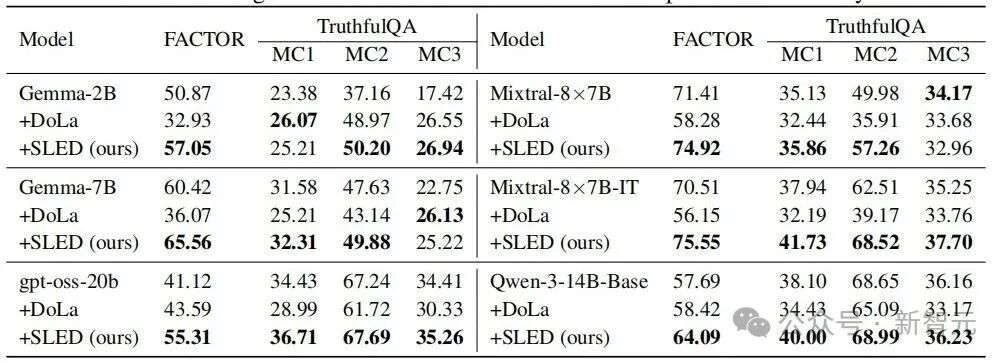
SLED在GPT-OSS、Mixtral、Qwen等不同模型家族上的表现,全面优于基线和DoLa。
推理速度确实会慢一点。但实验数据显示,延时开销只有大约4%,几乎感知不到,却换来了最高16%的准确率提升。
这让它不仅是一个性能优化技巧,更是一种能立刻落地、真正改变用户体验的解码策略。
SLED带来的价值远不止修正几个答案,它让我们重新理解了大模型:
知识并不是只集中在最后一层,而是分散在整个网络里。

过去我们只依赖最终的输出,就像只听一个人的意见,而忽略了其他层级中更接近真实的信号。
SLED的特别之处在于,它不改变模型结构,也不需要外部知识,就能把这些潜藏的信息调动起来,让答案更可信。
这在当下显得尤为重要。搜索和推荐场景已经在被AI改写——Google的AI Overview功能,会直接在搜索结果页展示由模型生成的摘要。
研究发现,当用户看到AI的总结时,他们更少点击下方的传统搜索链接,这让新闻网站的流量大幅下降。
与此同时,Google Discover流里也被曝光推荐了不少AI生成、未经验证的内容,甚至是假新闻站点。

当人们越来越依赖AI来直接告诉答案,内容的可靠性就变得至关重要。
如果输出的内容频繁出错,信任的代价将成倍增加。
在这种语境下,SLED的意义就不只是提升几个百分点的准确率,而是为生成式AI守住底线。
更值得期待的是,它还能走得更远。
SLED可以和监督微调结合,进一步适配特定领域;
也可以与检索增强(RAG)协同,把内部潜在知识和外部知识库结合成更强的「组合拳」;
甚至在未来在视觉问答、代码生成、长文本写作等任务中,都可能发挥作用。
与其盲目追求更大的参数和更多的数据,不如学会更聪明地使用已有的潜在知识。
SLED展示了一条新的路:把零散的记忆重新拼合,才能让模型更可靠,也更值得托付。
毕竟,AI不是不知道,而是忘了;而SLED,正在帮它记起来。
参考资料:
https://research.google/blog/making-llms-more-accurate-by-using-all-of-their-layers/
https://arxiv.org/html/2411.02433v3?utm_source
https://github.com/JayZhang42/SLED
文章来自于微信公众号“新智元”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
