
Z Potentials| 梁芊荟,从MIT计算审美到华为计算摄影:一个研究美的建筑师用AI 重写种草逻辑
Z Potentials| 梁芊荟,从MIT计算审美到华为计算摄影:一个研究美的建筑师用AI 重写种草逻辑AI shopping 的热度正在升温。
来自主题: AI资讯
8102 点击 2026-05-19 14:59
 搜索
搜索
AI shopping 的热度正在升温。
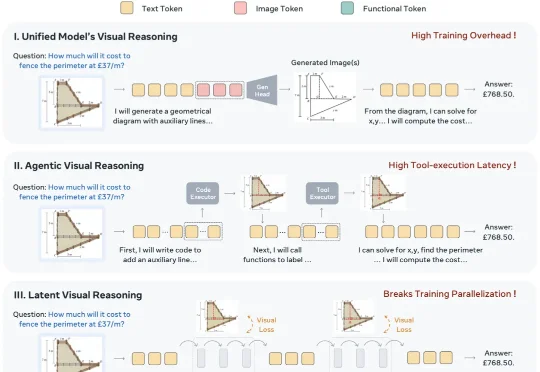
近日,Meta AI 与香港中文大学颠覆性提出了一种全新的视觉推理范式 ATLAS,不用外部工具,不显式生成中间图像,没有视觉监督信号,只用一个离散 word,首次颠覆性地代替 Agentic 和 Latent Visual Reasoning。
TencentDB Agent Memory 全球正式开源

Z Potentials独家获悉,清华系具身智能公司灵御智能宣布完成天使+轮近亿元人民币融资。本轮融资距离上次融资仅有两个月,由福田资本领投,力合创投、金沙江联合资本、复利多、楹辉创投、华仓资本跟投,老股东英诺基金、天鹰资本持续加注。Maple Pledge枫承资本长期出任公司私募股权融资顾问。

今日,据《华尔街日报》援引知情人士报道,OpenAI近期在一轮员工股份“要约收购”(Tender Offer)中,允许符合条件的员工每人出售最高价值3000万美元(约合人民币2亿元)的公司股票,这批员工也成为AI浪潮下最早实现大规模财富兑现的群体之一。
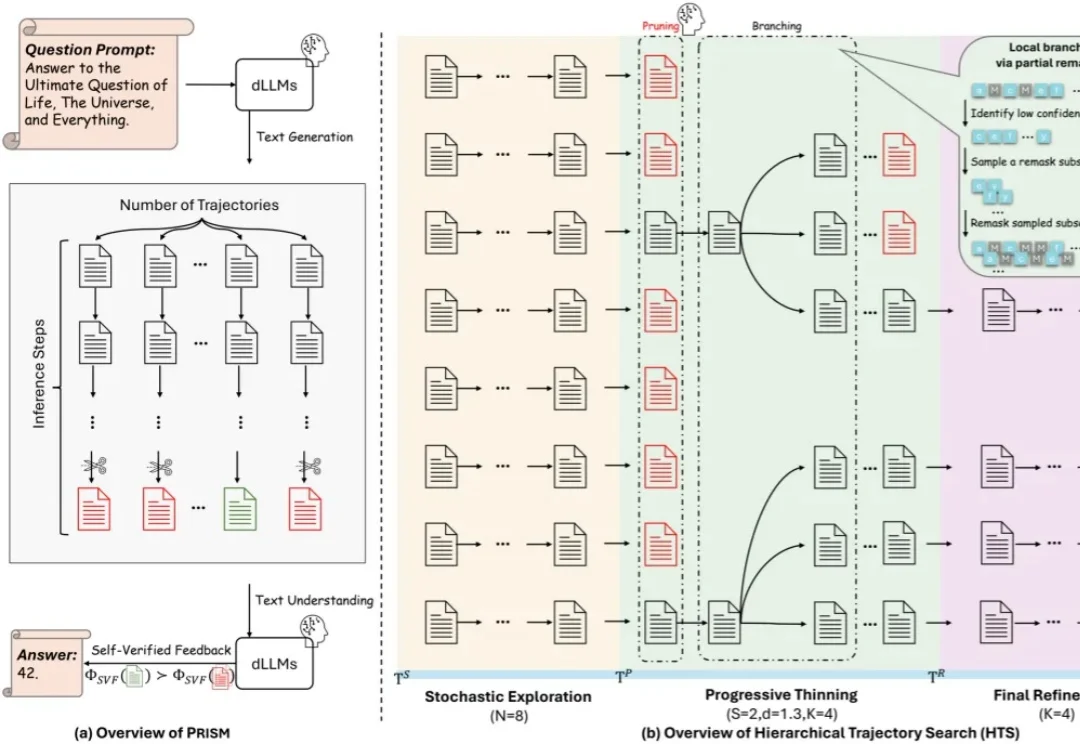
近年来,大模型能力提升的焦点正在从「训练时扩展」转向「推理时扩展」。从 Best-of-N、Self-Consistency 到更复杂的搜索与验证框架,Test-Time Scaling 已经成为提升大模型复杂推理能力的重要范式。

旅游是个矛盾的行业。据 WTTC 数据,2024 年全球旅游业贡献 10.9 万亿美元,接近全球 GDP 的 10%,每 10 个工作岗位就有 1 个与之相关。可就是这样一个体量的行业,二十年却没长出过一家真正的旅游公司。
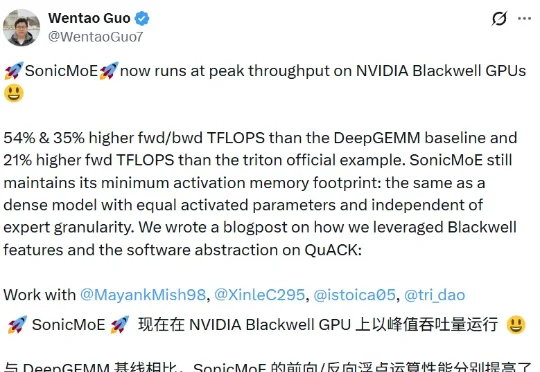
近日,由普林斯顿大学 Tri Dao(FlashAttention 的一作)和加州大学伯克利分校 Ion Stoica 领导的一个联合研究团队也做出了一个超快的索尼克:SonicMoE。据介绍,SonicMoE 能在英伟达 Blackwell GPU 上以峰值吞吐量运行!并且运算性能超过了 DeepSeek 之前开源并引发巨大轰动的 DeepGEMM。

来自华为泰勒实验室、北京大学和上海财经大学的研究团队提出了 SHAPE(Stage-aware Hierarchical Advantage via Potential Estimation),给推理链装上了一套「里程碑 + 推理税」机制——不仅告诉模型每一步推得对不对,还让它为啰嗦付出代价。结果是:准确率平均提升 3%,token 消耗直降 30%。
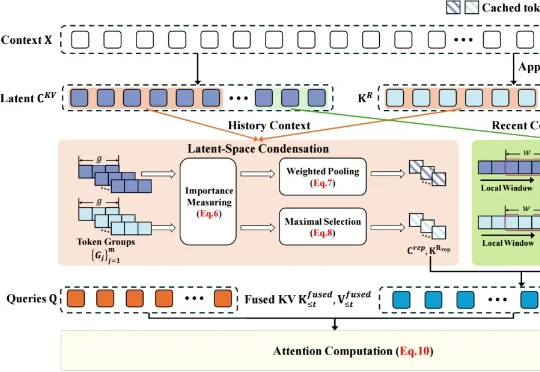
近日,琶洲实验室、华南理工大学、蔻町(AIGCode)等单位科研团队联合提出潜在空间压缩注意力(Latent-Condensed Attention,LCA),研究成果入选 ACL 2026。