# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

无需额外训练即可适配预训练生成模型的编辑方法,凭借灵活、高效的特性,已成为视觉生成领域的研究热点。这类方法通过操控 Attention 机制(如 Prompt-to-Prompt、MasaCtrl)实现文本引导编辑,但当前技术存在两大核心痛点,严重限制其在复杂场景的应用:
1. 编辑强度与源图一致性难以兼顾:现有方法若想保持与源图的一致性,往往需调低编辑强度,最终导致编辑目标无法实现;若提升编辑强度以完成修改,又容易破坏源图的特征结构(如改衣服颜色时丢失褶皱细节),且非编辑区域还会出现本应保持不变的意外变化。在多轮编辑或视频编辑场景中,这类问题会进一步累积放大,最终导致结果失真,无法满足实际需求。
2. 编辑强度缺乏细粒度控制能力:多数方法对编辑强度的控制局限于全局一致性(如同时约束结构与纹理),无法实现 “保结构改纹理” 或 “保纹理改结构” 的精准调节。这不仅限制了编辑的灵活性,还会导致通过调节强度生成的系列结果缺乏平滑过渡,难以满足用户对编辑精度的多样化需求。

图 1:现有编辑方法的痛点与 ConsistEdit 的优势对比
与此同时,生成模型架构正从 U-Net 向 Multi-Modal Diffusion Transformer (MM-DiT) 升级。MM-DiT 打破了 U-Net “文本 Cross-Attention + 视觉 Self-Attention” 的模态分离设计,通过统一的 Self-Attention 同时处理文本与视觉信息,为解决上述困境提供了新可能。但此前仅有 DiTCtrl 探索 MM-DiT 的 Attention 控制,且聚焦长视频生成,未针对编辑任务优化,导致无训练编辑技术未能充分挖掘 MM-DiT 的架构优势。
为研究清楚 MM-DiT 架构中 Attention 计算的特点,团队通过实验分析,提炼出三个核心发现:
1. 仅编辑 “视觉 Token” 是关键:仅编辑 Attention 中的 “视觉 Token” 即可保证编辑效果稳定,若修改 “文本 Token”,会导致结果失真,如下图所示:

2. MM-DiT 所有层均含结构信息:U-Net 的结构与纹理信息主要集中在深层 Decoder 阶段,而 MM-DiT 每一层的 Q/K/V Token 都保留完整的结构与纹理信息,如下图所示。这意味着编辑可以覆盖所有 Attention 层,而非仅作用于最后几层,此前 DiTCtrl 仅改后半层的策略,会导致无法完整保持结构一致性。

3. Q/K Token 主导结构一致性:单独对 Q/K 的视觉 Token 进行控制,可精准保留源图像结构;而 V 的视觉 Token 则主要影响内容纹理。这一发现为 “结构与纹理的解耦控制” 提供了技术依据。
基于上述洞察,团队提出 ConsistEdit—— 专为 MM-DiT 设计的无训练注意力控制方法,实现 “高精度编辑 + 强一致性保留”:
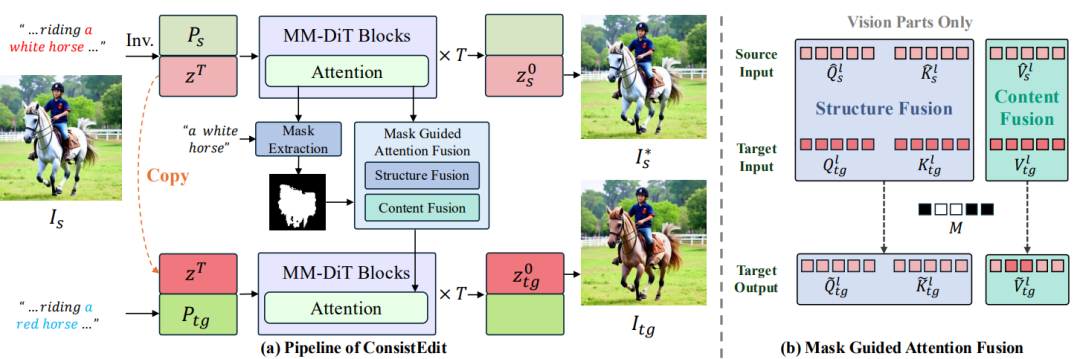
仅对所有 Attetion 层的视觉 Token 进行编辑,文本 Token 保持不变。这一设计可以实现强一致性的稳定生成,同时不偏离文字指令的控制。
在 Attention 计算前,通过文字和视觉 Token 的 Attention Map 值生成编辑掩码 M,精确分离编辑区与非编辑区。
根据 “结构 - 内容” 解耦特性,对 Q/K/V 采用不同操控策略:

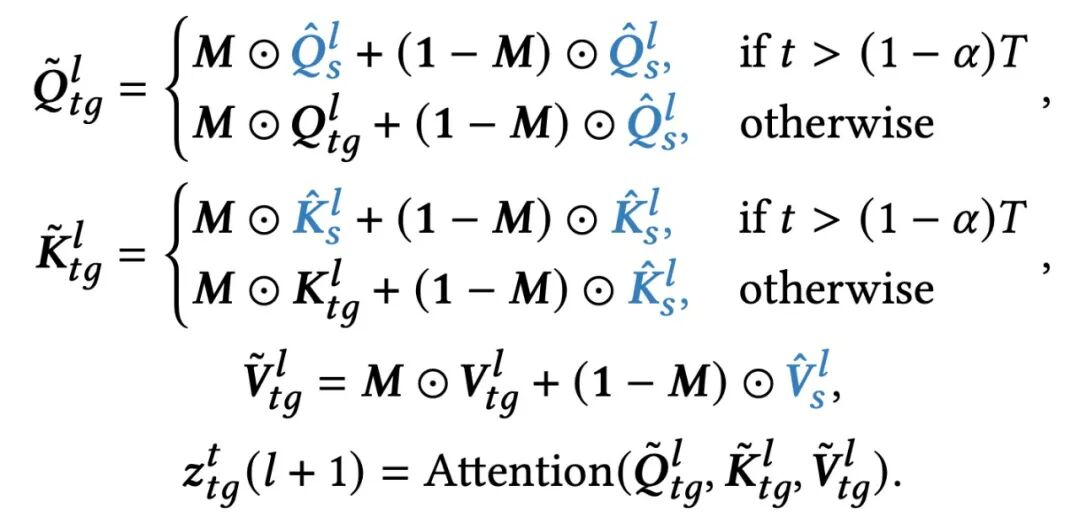
团队在 PIE-Bench 数据集上,从图像和视频两个维度,与 UniEdit-Flow、DiTCtrl, FireFlow 等 5 种主流方法对比,从定量、定性两方面验证 ConsistEdit 的优势。以下是一些效果展示:

图 2. 结构一致编辑任务(改材质、颜色,需要强一致性控制)

图 3. 结构不一致编辑任务(改风格、物体等,需弱一致性控制)
真实场景以及多轮编辑
针对真实图片,结合 inversion 技术后,ConsistEdit 可保持同等编辑性能,下方为多轮编辑效果展示。

多区域编辑
得益于精确的 Attention 控制与强大的预训练模型支撑,ConsistEdit 可在单次操作中完成多区域的精准编辑。

平滑的一致性强度
下方展示了结构一致性强度的调节结果,可以一致性强度仅影响结构(如物体轮廓),不改变内容细节(如颜色、纹理),证明结构与内容的控制信号已实现有效解耦。

泛化性:适配所有 MM-DiT 变体
ConsistEdit 不仅支持 Stable Diffusion 3,还可无缝适配 FLUX.1-dev、CogVideoX-2B 等 MM-DiT 类模型:
FLUX.1-dev

CogVideoX-2B


红色汽车编辑为蓝色汽车


黑色外套编辑为蓝色外套
ConsistEdit 的高一致性、细粒度控制特性,可广泛应用于各类视觉创作场景,既覆盖静态图片到动态视频的全场景编辑,又通过平滑的一致性调节为交互式创作提供了更多可能性。
文章来自于“机器之心”,作者 “殷子欣”。


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
