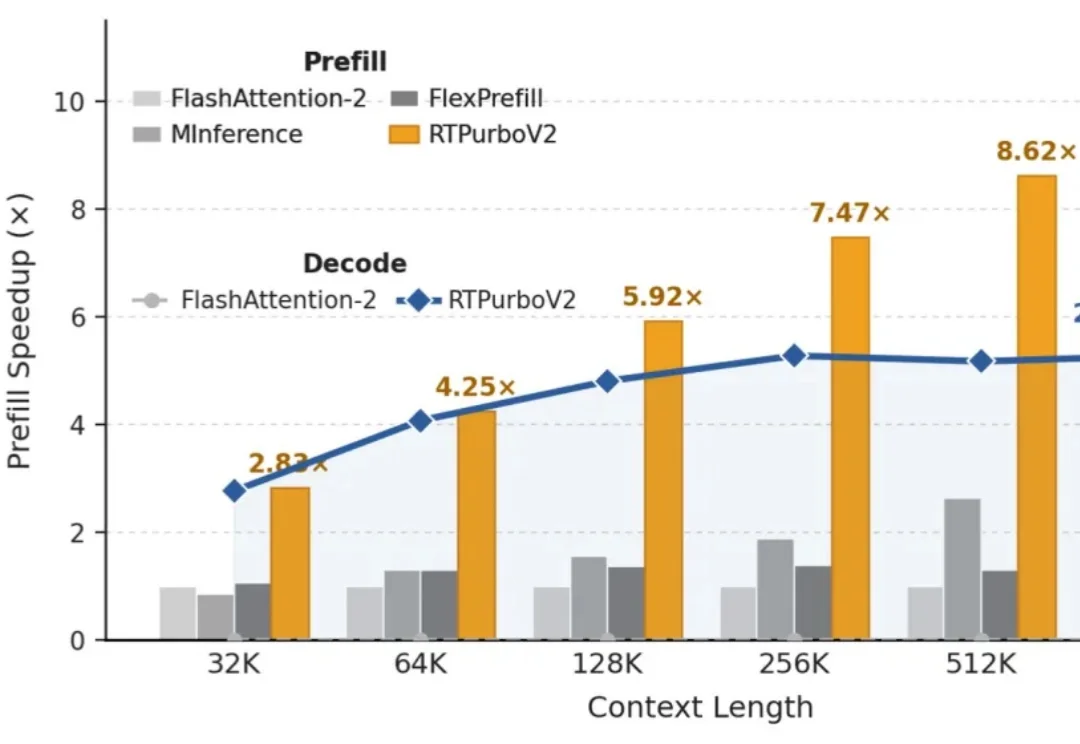
阿里RTPurboV2:原生Transformer再次崛起,百步训练实现10倍稀疏注意
阿里RTPurboV2:原生Transformer再次崛起,百步训练实现10倍稀疏注意“Full Attention 正在被遗忘”
来自主题: AI技术研报
8139 点击 2026-06-08 15:08
 搜索
搜索
“Full Attention 正在被遗忘”

2026 年 6 月的科罗拉多州丹佛市,全球计算机视觉与模式识别领域的顶级学术盛会 CVPR 正在召开,最前沿的视觉模型、机器人技术、下一代智能系统全都在同一个舞台上被反复讨论和辩证。

我们今天以 PDF 写论文的方式,已经持续了三百多年。然而论文其实是把一段混乱反复、充满试错的真实研究,讲成一个干净利落、足以服人的完美故事。

我在 2025 年年度总结的文章《Attention is all you need》里,提到在关注 AI 时代的投资机会,看了很多硅谷的播客和视频,一直想来硅谷看看,但自己认识的这边的人不多,恰好看到Linkloud 组织“创业加速营”,安排了不少硅谷当地的华人创业者、大厂从业人员的交流,就报名了,同去的其他人,还有想要 AI 转型或者就在 AI 领域创业的创始人或者中高管等。

Z Potentials独家获悉,侵入式脑机接口创业公司SiClink(曦涟科技)近日连续完成数千万元种子轮和天使轮融资,蓝驰创投、高瓴创投、中科神光联合押注。

连续创业的 York 开启了又一段新征程。过去十几年里,他几乎一直在做软硬一体系统:从计算机视觉、嵌入式,到后来的机器人。他的上一个创业项目——智能购物车 Caper AI,在 2021 年被 Instacart 以 3.5 亿美元收购。

MiniMax M3 今日正式发布。MiniMax M3 在编程和智能体等专业任务上达到了前沿的能力。它使用了我们提出的全新注意力架构 MSA (MiniMax Sparse Attention),最高支持 1M 超长上下文。如外界所期待的那样,它也是一个原生多模态模型,支持图片和视频的输入,并能操作电脑桌面。

腾讯设计领域的WorkBuddy来了。

图片来源:Baseten AI 初创公司 Baseten 近期正与投资者洽谈,计划以 110 亿美元估值(含融资额)募集 10 亿美元资金,据知情人士透露。这将使该公司估值较三个月前公布的上一轮 50

“我语言的局限,即意味着我世界的局限。”( Die Grenzen meiner Sprache bedeuten die Grenzen meiner Welt. )