
EMNLP2025 | SFT与RL的结合,vivo AI Lab提出新的后训练方法
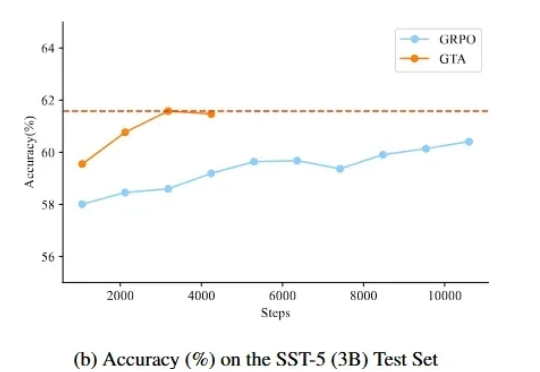
EMNLP2025 | SFT与RL的结合,vivo AI Lab提出新的后训练方法监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。
来自主题: AI技术研报
8172 点击 2025-09-23 14:59
监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。
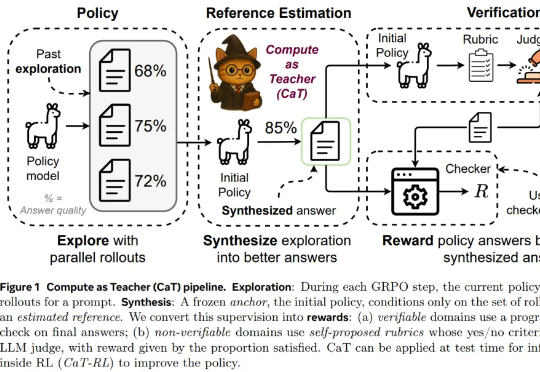
为了回答这一问题,来自牛津大学、Meta 超级智能实验室等机构的研究者提出设想:推理计算是否可以替代缺失的监督?本文认为答案是肯定的,他们提出了一种名为 CaT(Compute as Teacher)的方法,核心思想是把推理时的额外计算当作教师信号,在缺乏人工标注或可验证答案时,也能为大模型提供监督信号。

构建一个工业级高仿真 3D 虚拟世界,需要投入多少时间与人力?如果仅需一段描述、一张草图,AI 便可快速自动生成 —— 你相信吗?
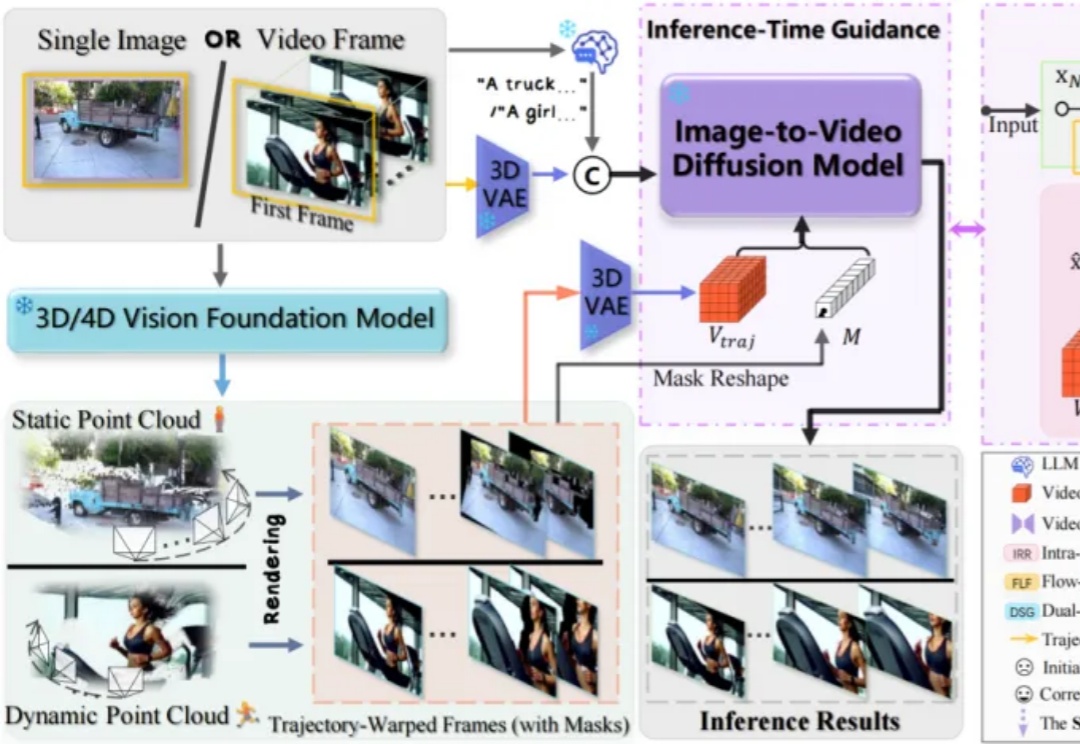
近来,由AI生成的视频片段以前所未有的视觉冲击力席卷了整个互联网,视频生成模型创造出了许多令人惊叹的、几乎与现实无异的动态画面。
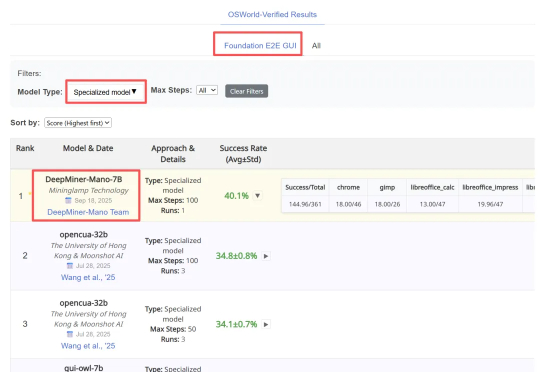
近日,明略科技推出的基于多模态基础模型的网页 GUI 智能体 Mano,凭借其强大的性能,在行业内公认的两大挑战基准 ——Mind2Web 和 OSWorld 上同时刷新纪录,取得当前最佳成绩(SOTA)。
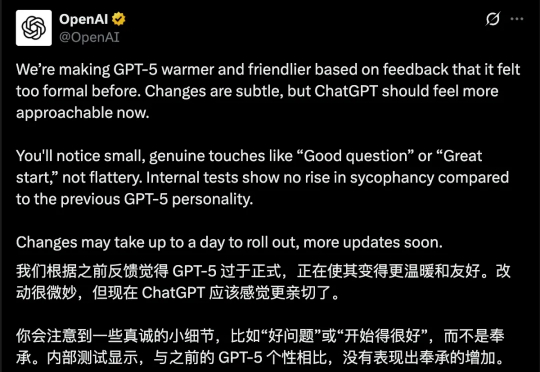
GPT-5上线引发全网吐槽。8月14日,ChatGPT负责人Nick Turley深度复盘了GPT-5发布「风波」,并详细总结了此次产品发布中的失误:比如过快下线GPT-4o、低估用户会对模型的情感依恋、没有让用户建立起「可预期性」等。Nick也分享了OpenAI的产品设计哲学,要坚持「真正对用户有帮助」的原则。
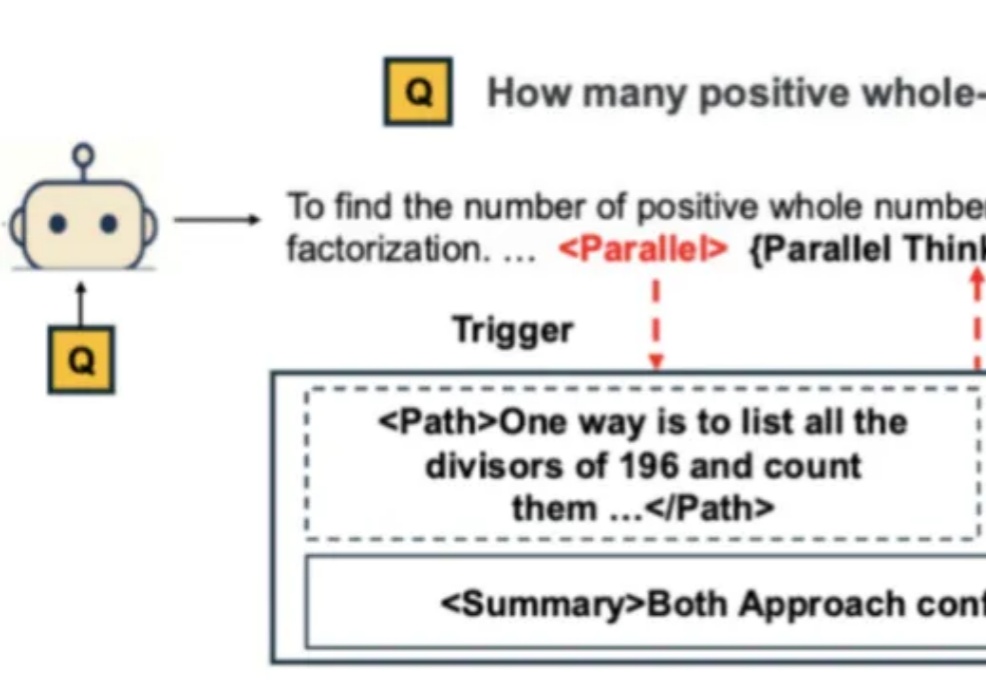
自从 Google Gemini 将数学奥赛的成功部分归功于「并行思维」后,如何让大模型掌握这种并行探索多种推理路径的能力,成为了学界关注的焦点。
来自MIT Improbable AI Lab的研究者们最近发表了一篇题为《RL's Razor: Why Online Reinforcement Learning Forgets Less》的论文,系统性地回答了这个问题,他们不仅通过大量实验证实了这一现象,更进一步提出了一个简洁而深刻的解释,并将其命名为 “RL's Razor”(RL的剃刀)。

DeepSeek荣登Nature封面,实至名归!今年1月,梁文锋带队R1新作,开创了AI推理新范式——纯粹RL就能激发LLM无限推理能力。Nature还特发一篇评论文章,对其大加赞赏。
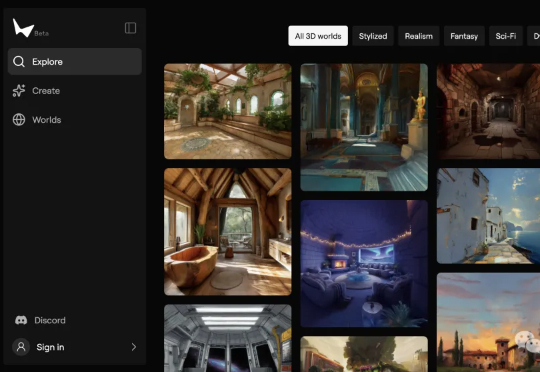
李飞飞创业公司世界模型新成果来了!只需要一个图像或者提示,就能构建出一个可以无限探索的3D世界——世界更大、风格更多样、3D几何结构更清晰,并且保持一致性、没有时间限制、没有奇怪的变形。