

斯坦福洗碗机器人新作!灵巧手跟人学采茶做早餐,CoRL 2025提名最佳论文
斯坦福洗碗机器人新作!灵巧手跟人学采茶做早餐,CoRL 2025提名最佳论文来自斯坦福大学、哥伦比亚大学、摩根大通AI研究院、卡耐基梅隆大学、英伟达提出了一种数据采集与策略学习框架DexUMI——利用人手作为自然接口将灵巧操作技能迁移至多种灵巧手。该框架通过硬件与软件的双重适配,最大限度缩小人手与各类灵巧手之间的具身差异。
来自主题: AI资讯
10330 点击 2025-10-03 11:46
来自斯坦福大学、哥伦比亚大学、摩根大通AI研究院、卡耐基梅隆大学、英伟达提出了一种数据采集与策略学习框架DexUMI——利用人手作为自然接口将灵巧操作技能迁移至多种灵巧手。该框架通过硬件与软件的双重适配,最大限度缩小人手与各类灵巧手之间的具身差异。

最近,X 博主 anandmaj 在一个月内复刻 Genie 3 的核心思想,开发出了 TinyWorlds,一个仅 300 万参数的世界模型,能够实时生成可玩的像素风格环境,包括 Pong、Sonic、Zelda 和 Doom。

结合RLHF+RLVR,8B小模型就能超越GPT-4o、媲美Claude-3.7-Sonnet。陈丹琦新作来了。他们提出了一个结合RLHF和RLVR优点的方法,RLMT(Reinforcement Learning with Model-rewarded Thinking,基于模型奖励思维的强化学习)。

Anthropic、OpenAI等大厂,正计划每年投入10亿美元,教会AI像人类一样工作。他们不仅为AI提供强化学习环境(RL environment,简称gym),还让AI「偷师」各领域专家。OpenAI高管预言,未来「整个经济」,将在某种程度上变成一台「RL机器」。

一个月前,我们曾报道过清华姚班校友、普林斯顿教授陈丹琦似乎加入 Thinking Machines Lab 的消息。有些爆料认为她在休假一年后,会离开普林斯顿,全职加入 Thinking Machines Lab。

近日,为了加速多元素催化剂的发现与优化,美国麻省理工学院团队开发了一个多模态机器人平台——CRESt(Copilot for Real-world Experimental Scientists)。该平台能够结合自动化设备、大规模模型和实验室监测,在实验设计中融入人类经验、文献知识和显微结构信息,从而加速多元素催化剂的发现和优化加速发展。
视觉-语言-动作模型是实现机器人在复杂环境中灵活操作的关键因素。然而,现有训练范式存在一些核心瓶颈,比如数据采集成本高、泛化能力不足等。
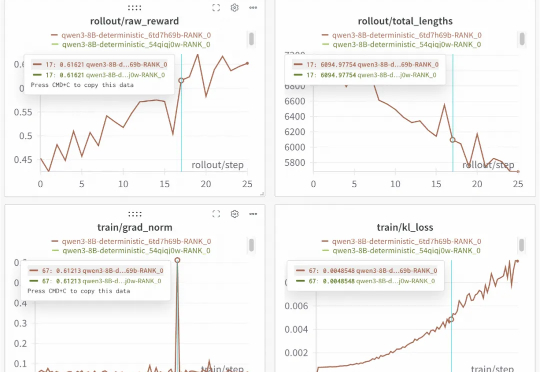
开源框架实现100%可复现的稳定RL训练!下图是基于Qwen3-8B进行的重复实验。两次运行,一条曲线,实现了结果的完美重合,为需要高精度复现的实验场景提供了可靠保障。这就是SGLang团队联合slime团队的最新开源成果。
刚刚,Meta FAIR推出了代码世界模型!CWM(Code World Model),一个参数量为32B、上下文大小达131k token的密集语言模型,专为代码生成和推理打造的研究模型。这是全球首个将世界模型系统性引入代码生成的语言模型。

自 Sora 亮相以来,AI 视频的真实感突飞猛进,但可控性仍是瓶颈:模型像才华横溢却随性的摄影师,难以精准执行 “导演指令”。我们能否让 AI 做到: 仅凭一张静态照片,就能 “脑补” 出整个 3D