
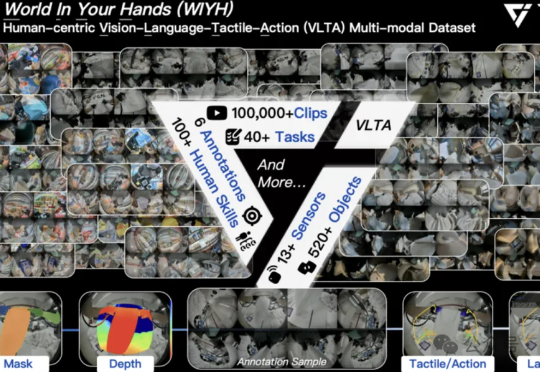
全球首个真实世界具身多模态数据集,它石智航交卷,比特斯拉还早6个月
全球首个真实世界具身多模态数据集,它石智航交卷,比特斯拉还早6个月全球首个真实世界具身多模态数据集,它来了! 刚刚,它石智航发布全球首个大规模真实世界具身VLTA(Vision-Language-Tactile-Action)多模态数据集World In Your Hands(WIYH)。
来自主题: AI技术研报
10566 点击 2025-10-11 12:06
全球首个真实世界具身多模态数据集,它来了! 刚刚,它石智航发布全球首个大规模真实世界具身VLTA(Vision-Language-Tactile-Action)多模态数据集World In Your Hands(WIYH)。
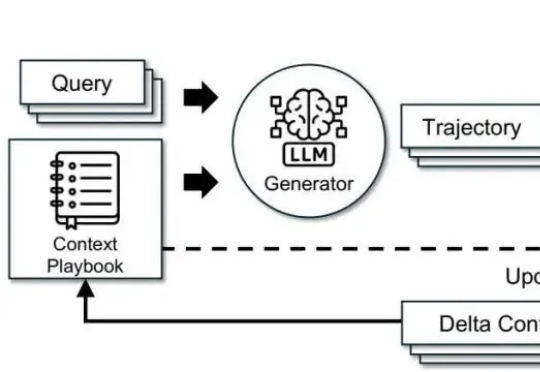
调模型不如“管上下文”。这篇文章基于 ACE(Agentic Context Engineering),把系统提示、运行记忆和证据做成可演化的 playbook,用“生成—反思—策展”三角色加差分更新,规避简化偏置与上下文塌缩。在 AppWorld 与金融基准上,ACE 相较强基线平均提升约 +10.6% 与 +8.6%,适配时延降至约 1/6(-86.9%),且在无标注监督场景依然有效。
屡遭 AI 伤害的泰勒·斯威夫特,最近却因 AI 被粉丝「围攻」了。 起因是一场全球营销活动。 为了宣传她的第十二张专辑《The Life of a Showgirl》,泰勒·斯威夫特(Taylor Swift,昵称霉霉)
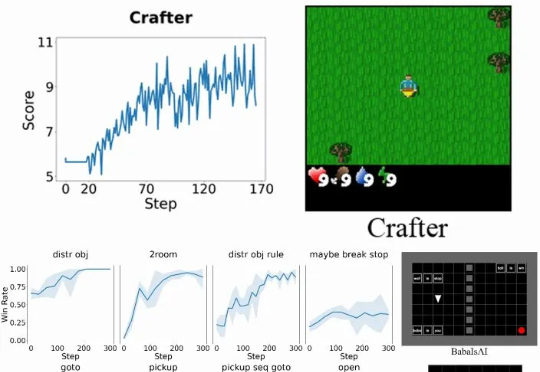
具体而言,Verlog 是一个多轮强化学习框架,专为具有高度可变回合(episode)长度的长时程(long-horizon) LLM-Agent 任务而设计。它在继承 VeRL 和 BALROG 的基础上,并遵循 pytorch-a2c-ppo-acktr-gail 的成熟设计原则,引入了一系列专门优化手段,从而在任务跨度从短暂交互到数百回合时,依然能够实现稳定而高效的训练。
来自 UIUC 与 Salesforce 的研究团队提出了一套系统化方案:UserBench —— 首次将 “用户特性” 制度化,构建交互评测环境,用于专门检验大模型是否真正 “懂人”;UserRL —— 在 UserBench 及其他标准化 Gym 环境之上,搭建统一的用户交互强化学习框架,并系统探索以用户为驱动的奖励建模。
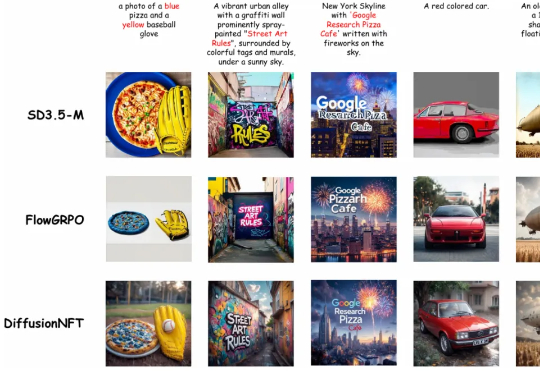
清华大学朱军教授团队,NVIDIA Deep Imagination 研究组与斯坦福 Stefano Ermon 团队联合提出了一种全新的扩散模型强化学习(RL)范式 ——Diffusion Negative-aware FineTuning (DiffusionNFT)。该方法首次突破现有 RL 对扩散模型的基本假设,直接在前向加噪过程(forward process)上进行优化
论文提出的方法名为 RL4HS,它使用了片段级奖励(span-level rewards)和类别感知的 GRPO(Class-Aware Group Relative Policy Optimization),从而避免模型偷懒、只输出无错误预测。
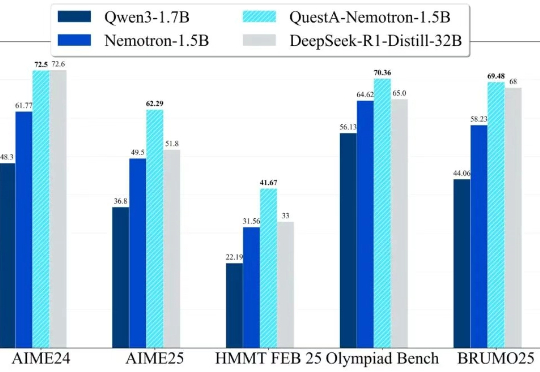
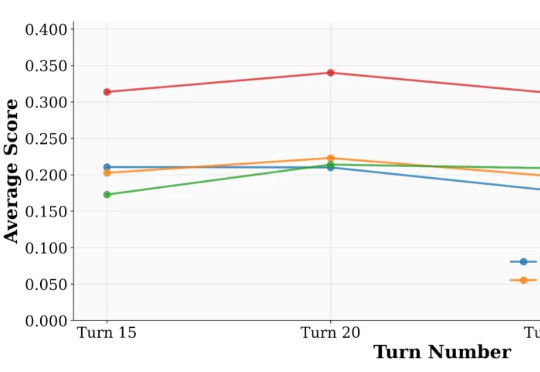
QuestA(问题增强)引入了一种方法,用于提升强化学习中的推理能力。通过在训练过程中注入部分解题提示,QuestA 实现两项重大成果

来自牛津大学、新加坡国立大学、伊利诺伊大学厄巴纳-香槟分校,伦敦大学学院、帝国理工学院、上海人工智能实验室等等全球 16 家顶尖研究机构的学者,共同撰写并发布了长达百页的综述:《The Landscape of Agentic Reinforcement Learning for LLMs: A Survey》。

来自斯坦福大学、哥伦比亚大学、摩根大通AI研究院、卡耐基梅隆大学、英伟达提出了一种数据采集与策略学习框架DexUMI——利用人手作为自然接口将灵巧操作技能迁移至多种灵巧手。该框架通过硬件与软件的双重适配,最大限度缩小人手与各类灵巧手之间的具身差异。