ICLR 2026惊现SAM 3,分割一切的下一步:让模型理解「概念」
ICLR 2026惊现SAM 3,分割一切的下一步:让模型理解「概念」说出概念,SAM 3 就明白你在说什么,并在所有出现的位置精确描绘出边界。 Meta 的「分割一切」再上新? 9 月 12 日,一篇匿名论文「SAM 3: SEGMENT ANYTHING WITH CONCEPTS」登陆 ICLR 2026,引发网友广泛关注。
来自主题: AI技术研报
7759 点击 2025-10-13 16:03
 搜索
搜索
说出概念,SAM 3 就明白你在说什么,并在所有出现的位置精确描绘出边界。 Meta 的「分割一切」再上新? 9 月 12 日,一篇匿名论文「SAM 3: SEGMENT ANYTHING WITH CONCEPTS」登陆 ICLR 2026,引发网友广泛关注。
这不是科幻,这是 Anything 正在发生的真实故事。这家刚刚完成 1100 万美元融资、估值达到 1 亿美元的创业公司,在上线两周内就实现了 200 万美元的年度经常性收入。更让人震惊的是,他们的用户已经开始用这个平台做出真正赚钱的生意。我深入研究了这家公司后,发现他们不只是又一个 AI 编程工具,而是在彻底改变软件开发的游戏规则。
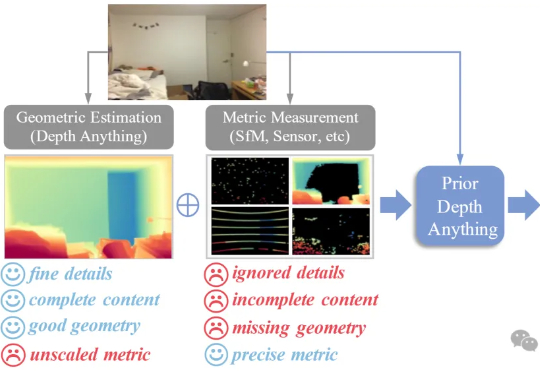
浙江大学与港大团队推出「Prior Depth Anything」,把稀疏的深度传感器数据与AI完整深度图融合,一键补洞、降噪、提分辨率,让手机、车载、AR眼镜都能实时获得精确三维视觉。无需额外训练,就能直接提升VGGT等3D模型的深度质量,零样本刷新多项深度补全、超分、修复纪录。

n8n成立于2019年,已集成400多个第三方应用,支持自托管,拥有23万活跃用户(含3000家企业),代码库位列GitHub全球Top 50。区别于Zapier等传统SaaS平台,n8n采用“按工作流计费”+“支持自定义与本地部署”的模式,以“connect anything to everything”为理念,是高性价比和数据控制的开源自动化平台。

最近,由香港大学黄超教授团队发布的开源项目「一体化的多模态RAG框架」RAG-Anything,有效解决了传统RAG的技术局限,实现了「万物皆可RAG」的处理能力。
总是“死记硬背”“知其然不知其所以然”?

突破传统检索增强生成(RAG)技术的单一文本局限,实现对文档中文字、图表、表格、公式等复杂内容的统一智能理解。

在复杂、未知的现实环境中,传统导航方法往往依赖闭集语义或事先构建的地图,难以实现真正的“按需探索”。为打破这一瓶颈,本文提出了 FindAnything ——一套融合视觉语言模型的对象为中心、开放词汇三维建图与探索系统。

视觉AI终极突破来了!英伟达等机构推出超强多模态模型DAM,仅3B参数,就能精准描述图像和视频中的任何细节。刚刚,英伟达联手UC伯克利、UCSF团队祭出首个神级多模态模型——Describe Anything Model(DAM),仅3B参数。
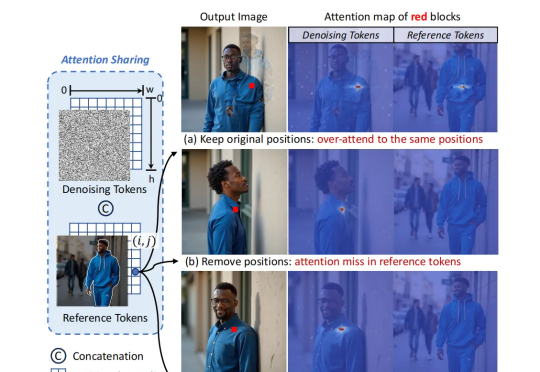
,清华大学、北京航空航天大学团队推出了全新的架构设计 ——Personalize Anything,它能够在无需训练的情况下,完成概念主体的高度细节还原,支持用户对物体进行细粒度的位置操控,并能够扩展至多个应用中,为个性化图像生成引入了一个新范式。