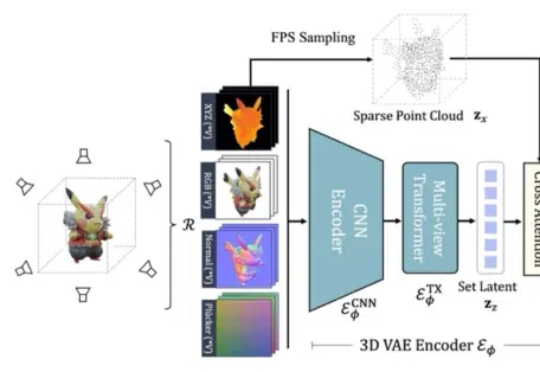
挖掘DiT的位置解耦特性,Personalize Anything免训练实现个性化图像生成
挖掘DiT的位置解耦特性,Personalize Anything免训练实现个性化图像生成个性化图像生成是图像生成领域的一项重要技术,正以前所未有的速度吸引着广泛关注。它能够根据用户提供的独特概念,精准合成定制化的视觉内容,满足日益增长的个性化需求,并同时支持对生成结果进行细粒度的语义控制与编辑,使其能够精确实现心中的创意愿景。
来自主题: AI技术研报
10822 点击 2025-03-25 14:50