# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
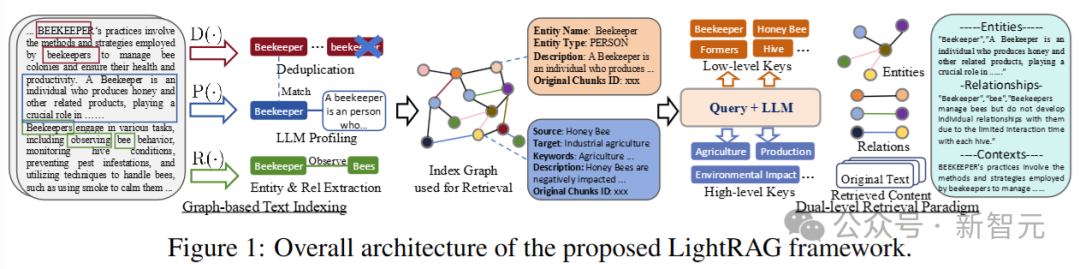
最近,由香港大学黄超教授团队发布的开源项目「一体化的多模态RAG框架」RAG-Anything,有效解决了传统RAG的技术局限,实现了「万物皆可RAG」的处理能力。
RAG-Anything的核心技术创新在于构建了统一的多模态知识图谱架构,能够同时处理并关联文档中的文字内容、图表信息、表格数据、数学公式等多种类型的异构内容,解决了传统RAG系统仅支持文本处理的技术限制,为多模态文档的智能理解提供了新的技术方案。

项目地址:https://github.com/HKUDS/RAG-Anything
实验室主页: https://sites.google.com/view/chaoh
RAG-Anything作为一个专为多模态文档设计的检索增强生成(RAG)系统,专注解决复杂场景下的智能问答与信息检索难题。
该系统提供完整的端到端多模态文档处理解决方案,能够统一处理文本、图像、表格、数学公式等多种异构内容,实现从文档解析、知识图谱构建到智能问答的全流程自动化,为下一代AI应用提供了可靠的技术基础。
该项目在开源框架LightRAG的基础上进行了深度扩展与优化,其多模态处理能力现已独立演进为RAG-Anything,并将基于此平台持续迭代更新。
多模态理解的时代需求
随着人工智能技术的快速发展和大型语言模型能力的显著提升,用户对AI系统的期望已经从单纯的文本处理扩展到对真实世界复杂信息的全面理解。
现代知识工作者每天面对的文档不再是简单的纯文本,而是包含丰富视觉元素、结构化数据和多媒体内容的复合型信息载体。
这些文档中往往蕴含着文字描述、图表分析、数据统计、公式推导等多种信息形态,彼此相互补充、共同构成完整的知识体系。
在专业领域的实际应用中,多模态内容已成为知识传递的主要载体。科研论文中的实验图表和数学公式承载着核心发现,教育材料通过图解和示意图增强理解效果,金融报告依赖统计图表展示数据趋势,医疗文档则包含大量影像资料和检验数据。
这些丰富的视觉化内容与文字描述相互补充,共同构成了完整的专业知识体系。
面对如此复杂的信息形态,传统的单一文本处理方式已无法满足现代应用需求。各行业都迫切需要AI系统具备跨模态的综合理解能力,能够同时解析文字叙述、图像信息、表格数据和数学表达式,并建立它们之间的语义关联,从而为用户提供准确、全面的智能分析和问答服务。
传统RAG系统的技术瓶颈
尽管检索增强生成(RAG)技术在文本问答领域取得了显著成功,但现有的RAG系统普遍存在明显的模态局限性。
传统RAG架构主要针对纯文本内容设计,其核心组件包括文本分块、向量化编码、相似性检索等,这些技术栈在处理非文本内容时面临严重挑战:
RAG-Anything的实用价值
RAG-Anything项目针对上述技术挑战而设计开发。项目目标是构建一个完整的多模态RAG系统,解决传统RAG在处理复杂文档时的局限性问题。
系统采用统一的技术架构,将多模态文档处理从概念验证阶段推进到实际可部署的工程化解决方案。
此外,系统还采用了端到端的技术栈设计,覆盖文档解析、内容理解、知识构建和智能问答等核心功能模块。
在文件格式支持方面,系统兼容PDF、Office文档、图像等常见格式。技术架构上,系统实现了跨模态的统一知识表示和检索算法,同时提供标准化的API接口和灵活的配置参数。
RAG-Anything的技术定位是作为多模态AI应用的基础组件,为RAG系统提供可直接集成的多模态文档处理能力。
RAG-Anything 通过创新的技术架构和工程实践,在多模态文档处理领域实现了显著突破:
· 端到端多模态处理架构
构建完整的自动化处理链路,从原始文档输入开始,系统能够智能识别并精确提取文本、图像、表格、数学公式等异构内容。
通过统一的结构化建模方法,建立从文档解析、语义理解、知识构建到智能问答的全流程自动化体系,彻底解决了传统多工具拼接带来的数据损失和效率问题。
· 广泛的文档格式兼容性
原生支持PDF、Microsoft Office套件(Word/Excel/PowerPoint)、常见图像格式(JPG/PNG/TIFF)以及Markdown、纯文本等多达10余种主流文档格式。
系统内置智能格式检测和标准化转换机制,确保不同来源的文档都能通过统一的处理管道获得一致的高质量解析结果。
· 深度内容理解技术栈
集成视觉、语言语义理解模块和结构化数据分析技术,实现对各类内容的深度理解。
图像分析模块支持复杂图表的语义提取,表格处理引擎能够准确识别层次结构和数据关系,LaTeX公式解析器确保数学表达式的精确转换,文本语义建模则提供丰富的上下文理解能力。
· 多模态知识图谱构建
采用基于实体关系的图结构表示方法,自动识别文档中的关键实体并建立跨模态的语义关联。
系统能够理解图片与说明文字的对应关系、表格数据与分析结论的逻辑联系,以及公式与理论阐述的内在关联,从而在问答过程中提供更加准确和连贯的回答。
· 灵活的模块化扩展
基于插件化的系统架构设计,支持开发者根据特定应用场景灵活配置和扩展功能组件。
无论是更换更先进的视觉理解模型、集成专业领域的文档解析器,还是调整检索策略和嵌入算法,都可以通过标准化接口快速实现,确保系统能够持续适应技术发展和业务需求的动态变化。
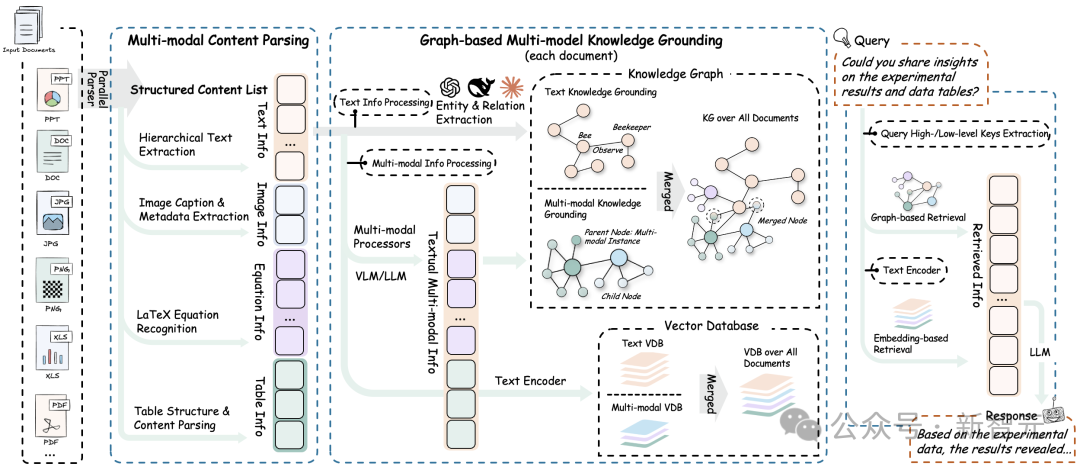
RAG-Anything基于创新的三阶段技术架构,突破传统RAG系统在多模态文档处理上的技术瓶颈,实现真正的端到端智能化处理。
高精度文档解析技术
采用基于MinerU 2.0的先进结构化提取引擎,实现对复杂文档的智能解析。系统能够准确识别文档的层次结构,自动分割文本块、定位图像区域、解析表格布局、识别数学公式。
通过标准化的中间格式转换,保证不同文档类型的统一处理流程,最大化保留原始信息的语义完整性。
深度多模态内容理解
统内置专业化的模态处理引擎,针对不同内容类型提供定制化的理解能力:
所有模态内容通过统一的知识表示框架进行整合,实现真正的跨模态语义理解和关联分析。
统一知识图谱构建
RAG-Anything将多模态内容统一建模为结构化知识图谱,突破传统文档处理的信息孤岛问题。
双层次检索问答
RAG-Anything采用双层次检索问答机制,以实现对复杂问题的精准理解与多维响应。
该机制同时兼顾 细粒度信息抽取 与 高层语义理解,显著提升了系统在多模态文档场景下的检索广度与生成深度。
智能关键词分层提取:
混合检索策略:
通过这种双层次的检索架构,系统能够处理从简单事实查询到复杂分析推理的各类问题,真正实现智能化的文档问答体验。
RAG-Anything提供两种便捷的安装部署方式,满足不同用户的技术需求。推荐使用PyPI安装方式,可实现一键快速部署,体验完整的多模态RAG功能。
安装方式
选项1:从PyPI安装
pip install raganything
选项2:从源码安装
git
clone
https://github.com/HKUDS/RAG-Anything.git
cd
RAG-Anything
pip install -e .
多场景应用模式
RAG-Anything基于模块化架构设计,为不同应用场景提供两种灵活的使用路径,满足从快速原型到生产级部署的各类需求:
方式一:一键式端到端处理
适用场景:处理完整的PDF、Word、PPT等原始文档,追求零配置、全自动的智能处理。
核心优势:
技术流程: 原始文档 → 智能解析 → 多模态理解 → 知识图谱构建 → 智能问答
示例代码:
import asyncio
from raganything import RAGAnything
from lightrag.llm.openai import openai_complete_if_cache, openai_embed
async def main():
rag = RAGAnything(
working_dir="./rag_storage",
llm_model_func=..., # LLM
vision_model_func=..., # VLM
embedding_func=..., # 嵌入模型
embedding_dim=3072,
max_token_size=8192
)
# 处理文档并构建图谱await rag.process_document_complete(
file_path="your_document.pdf",
output_dir="./output"
)
# 多模态问答查询
result = await rag.query_with_multimodal("Could you share insights on the experiment results and the associated data tables?", mode="hybrid")
print(result)
asyncio.run(main())
方式二:精细化手动构建
适用场景:已有结构化的多模态内容数据(图像、表格、公式等),需要精确控制处理流程和定制化功能扩展。
核心优势:
示例代码:
from lightrag import LightRAG
from raganything.modalprocessors import ImageModalProcessor, TableModalProcessor
# 初始化 LightRAG 系统
rag = LightRAG(working_dir="./rag_storage", ...)
# 处理图像内容
image_processor = ImageModalProcessor(lightrag=rag, modal_caption_func=your_vision_model_func)
image_content = {
"img_path": "fig1.jpg",
"img_caption": ["Figure1: RAG-Anything vs Baselines"],
"img_footnote": [""]
}
description, entity_info = await image_processor.process_multimodal_content(
modal_content=image_content,
content_type="image",
file_path="RAG-Anything.pdf",
entity_name="fig1-RAG-Anything vs Baselines"
)
# 处理表格内容
table_processor = TableModalProcessor(lightrag=rag, modal_caption_func=your_llm_model_func)
table_content = {
"table_body": """
| Methods | Accuracy | F1 |
|------|--------|--------|
| RAGAnything | 95.2% | 0.94 |
| Baseline | 87.3% | 0.85 |
""",
"table_caption": ["Table1: RAG-Anything vs Baselines"],
"table_footnote": ["Dataset-A"]
}
description, entity_info = await table_processor.process_multimodal_content(
modal_content=table_content,
content_type="table",
file_path="RAG-Anything.pdf",
entity_name="tab1-RAG-Anything vs Baselines"
)
RAG-Anything未来展望
深度推理能力升级
RAG-Anything将构建具备人类级别逻辑推理能力的多模态AI系统。通过多层次推理架构实现从浅层检索到深层推理的跃升,支持跨模态多跳深度推理和因果关系建模。考虑提供可视化推理路径追踪、证据溯源和置信度评估。
更加丰富的插件生态
RAG-Anything未来也会考虑从另一个维度实现扩展——探索构建开放的多模态处理生态系统。我们设想让不同行业都能拥有更贴合需求的智能助手。
比如帮助科研人员更好地解析学术图表,协助金融分析师处理复杂的财务数据,或者让工程师更容易理解技术图纸,医生更快速地查阅病历资料等。
参考资料:
https://github.com/HKUDS/RAG-Anything
文章来自于微信公众号“新智元”。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
