

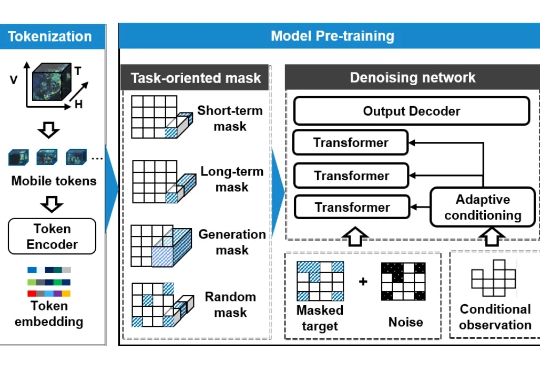
KDD 2025 | UoMo来了,首个无线网络流量预测模型,一个框架搞定三类任务
KDD 2025 | UoMo来了,首个无线网络流量预测模型,一个框架搞定三类任务在今年的 ACM KDD 2025 大会上,清华大学电子系团队联合中国移动发布了 UoMo,全球首个面向移动网络的通用流量预测模型。UoMo 能同时胜任短期预测、长期预测,甚至在没有历史数据的情况下生成全新区域的流量分布。
来自主题:
AI技术研报
7893 点击 2025-08-18 15:54
 搜索
搜索
在今年的 ACM KDD 2025 大会上,清华大学电子系团队联合中国移动发布了 UoMo,全球首个面向移动网络的通用流量预测模型。UoMo 能同时胜任短期预测、长期预测,甚至在没有历史数据的情况下生成全新区域的流量分布。

忘掉你学过的一切提示词技巧吧,你只需要这一个就够了。
作为老牌企业软件巨头 IgniteTech 公司 CEO,Eric Vaughan 在回顾自己数十年职业生涯中最激进的决策时,仍然意志坚定、毫不动摇。

鲨疯了!一周连发六款模型。火力全开的昆仑万维,正在把多模态AI卷到新高度。8月11日~15日,这家公司天天都有新模型掉落,覆盖的还都是视频生成、世界模型、统一多模态、智能体以及AI音乐创作这些大热门,几乎每一个都是多模态AI应用的核心场景。
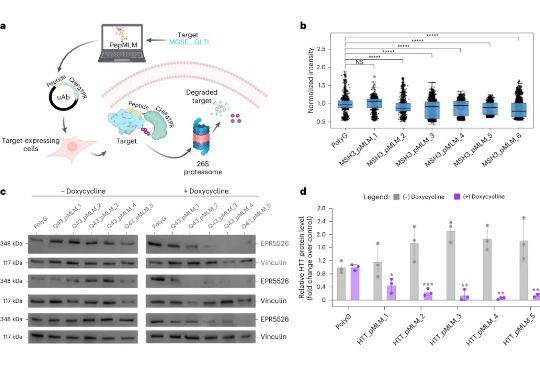
在药物研发领域,针对“难成药靶点”开发药物一直是难题。 由于失败风险极高,需要巨大的资金和时间投入,许多公司倾向于优先选择“低垂果实”,即更容易成药的靶点,导致许多疾病无药可医。
7月30日小规模上线测试后,soon很快在游戏圈掀起热议,它可以让你“一句话生成一个游戏”,而且是真正能玩的那种。

智东西8月17日报道,今天,世界人形机器人运动会医药场景药物分拣比赛决赛落下帷幕。从初赛到复赛,银河通用Galbot队全程零遥操作、完全自主运行,预赛、复赛及决赛均为第一,最终以10分22秒用时,336分的总赋分夺得本场赛事冠军。
真正的 AI 系统不是一个 Chat 窗口,而是一个智能的工作现场。 工具越多,效率反而越低?一项来自《哈佛商业评论》的调查显示,员工每天平均切换应用程序超过 1200 次,一年下来累计浪费的时间高达 5 个完整工作周,占全年总工作时间的 9%。

最近,这家由前 Meta 和世嘉老兵组建AI游戏公司Studio Atelico,宣布完成500 万美元种子轮融资,由专AI的风投 Air Street Capital 领投,Hugging Face 核心成员 Thomas Wolf 参投,高调宣布要重新定义游戏体验 ,他们的目标,是让每个玩家都能拥有独一无二的动态世界。
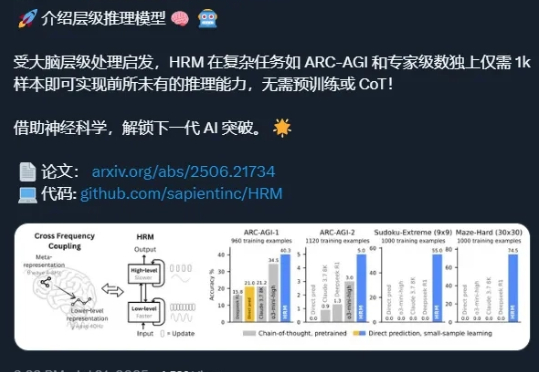
还记得分层推理模型(Hierarchical Reasoning Model,HRM)吗? 这项工作于 6 月份发布,当时引起了不小的轰动——X/Twitter 上的相关讨论获得了超过 400 万的浏览量和数万个点赞,剖析这项工作的 YouTube 视频观看量也超过了 47.5 万次。

感谢 Moose 老师非常细致地分享了: 他从WAIC 大会现场观察了国内 AI 的最新动向——从大厂展区的大模型生态,到独立团队的创意产品,涵盖办公、教育、设计、视频等多个场景。通过这些案例,可以更清晰地看到 AI 在 2025 年的三种趋势:套壳的传统产品、短期的效率工具,以及真正有潜力的垂直平台与智能体(Agent)

上周,一款由AI驱动的CRPG游戏《印格》(Engram)在ChinaJoy上亮相。

最近一段时间,经常能听到把“枯燥乏味”的工作交给AI的说法。

Vibe Coding(Claude code、Cursor、Lovable) 把原本8周的开发周期压缩成2天 现在,同样20倍的加速在营销圈上演—— Vibe Marketing: 一个人➕n 个AI Agent和自动化工作流,几小时就能把营销想法落地了,杠杆效应大到离谱。
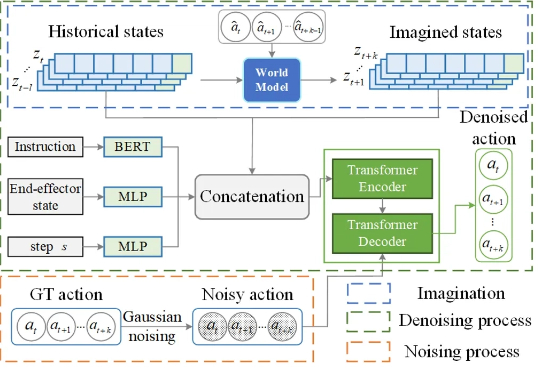
在机器人操作任务中,预测性策略近年来在具身人工智能领域引起了广泛关注,因为它能够利用预测状态来提升机器人的操作性能。然而,让世界模型预测机器人与物体交互的精确未来状态仍然是一个公认的挑战,尤其是生成高质量的像素级表示。

数据显示,无论是国内还是海外,AI行业的发展,在经历了爆发式增长后,都开始出现部分下滑,行业正进入一个全新的阶段。真实的用户偏好开始显现,旧的增长逻辑正在失效。
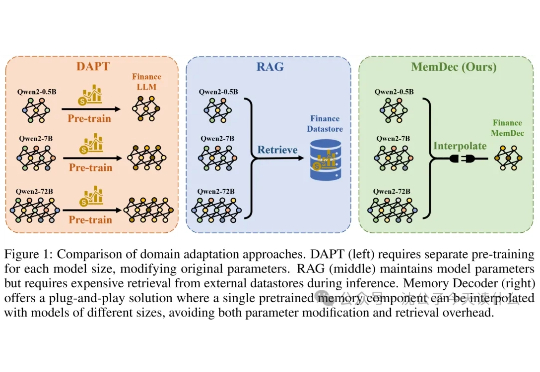
一句话概括,还在嫌弃RAG太慢?这帮研究员直接把检索数据库"蒸馏"成了一个小模型,实现了不检索的检索增强,堪称懒人福音。

GPT-5是一个分水岭,终于学会了「推理」。联创Greg Brockman最新访谈畅谈了OpenAI AGI之路,未来AI可以做到边用边学,在超临界模式下推导出N阶后果。
老朋友们,久违! 让我们来看看大厂们最近又有什么新的动作!
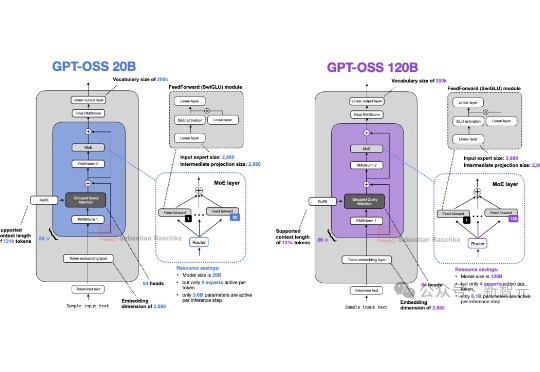
自GPT-2以来,大模型的整体架构虽然未有大的变化,但从未停止演化的脚步。借OpenAI开源gpt-oss(120B/20B),Sebastian Raschka博士将我们带回硬核拆机现场,回溯了从GPT-2到gpt-oss的大模型演进之路,并将gpt-oss与Qwen3进行了详细对比。
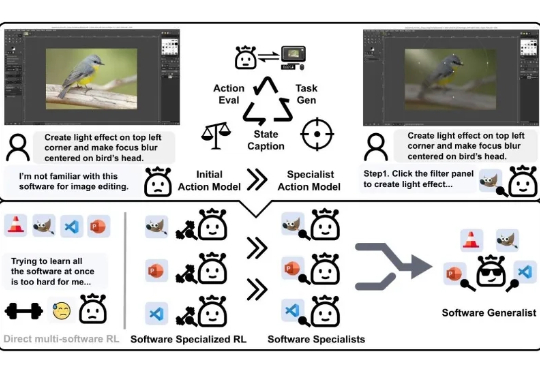
当前计算机使用智能体(CUA)的发展,主要依赖于大量昂贵的人工标注数据 。这极大地限制了它们在缺少现成数据的新颖或专业软件中的应用能力 。为了打破这一瓶颈,来自上海交通大学和香港中文大学的学者们提出了 SEAgent,一个全新的、无需任何人类干预,即可通过与环境交互来自主学习和进化的智能体框架。

Genie 3来了!这或许是最接近「模拟世界」的AI魔法。只需一句话,它就能生成一个动态、可互动的世界——角色能互动、下水会溅起水花,甚至还能记住一分钟前的细节。DeepMind研究者直言:Genie 3是通向AGI的关键一步。

目前三星正被各方压力拉扯,资源被摊得很薄,营收增长停滞,利润空间被压缩到不舒服。芯片业务的下滑尤其扎心——2024年第二季度半导体部门运营利润只有4000亿韩元,而分析师的预期是2.73万亿韩元,这差距不是一星半点。

作者测试了智谱GLM-4.5V(开启/关闭推理)、豆包、Kimi、元宝和ChatGPT-5在识别十张奇葩卫生间标识上的表现。评测模拟紧急如厕场景,按识别正确性评分。结果智谱普通模式得分最高(86分),ChatGPT-5和智谱推理模式次之(78分),豆包和元宝70分,Kimi垫底(38分),揭示了各AI视觉能力的差异及局限性。

AI用的多了,对于什么是AI味我自有分辨。措辞、句子长短、标点符号等等。 但是如果从父母那里收到疑似AI生成的消息,我还是会原地愣住——不是吧,这是咋回事?

这是一个非常不一样的AI陪伴类产品,跟我们看过的很多通用的偏情感类的AI陪伴类产品不一样的是,它只聚焦在一个领域。

程序员教练来了——AI不再替你全写完代码!Claude Code刚刚推出的「做中学」模式,会在关键步骤停下来,让你亲手完成任务。这种反偷懒的AI,可能才是真正让人越用越聪明的秘密武器。

根据金融时报报道,美国风投巨头Benchmark或将被迫从Manus撤资。多位知情人士透露,美国财政部已对这笔交易展开审查,最糟情况下,Benchmark可能被要求全面退出。

奥特曼在一次晚宴上勾勒出宏大愿景——从颠覆搜索与社交,到斥资数万亿打造数据中心和全新AI硬件,甚至探索脑机接口。他强调AI正处在类似互联网泡沫的关键时刻,但其潜力无可比拟。

今年,AI+医疗无疑成了全球市场的热门赛道,而Truemeds凭借其独特的商业模式,成为印度在这一领域的黑马。

