# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当前计算机使用智能体(CUA)的发展,主要依赖于大量昂贵的人工标注数据 。这极大地限制了它们在缺少现成数据的新颖或专业软件中的应用能力 。为了打破这一瓶颈,来自上海交通大学和香港中文大学的学者们提出了 SEAgent,一个全新的、无需任何人类干预,即可通过与环境交互来自主学习和进化的智能体框架。
SEAgent 的核心创新在于其闭环的自主进化框架、一个经过深度优化的评判模型,以及一套高效的 「专才 - 通才」 融合策略。

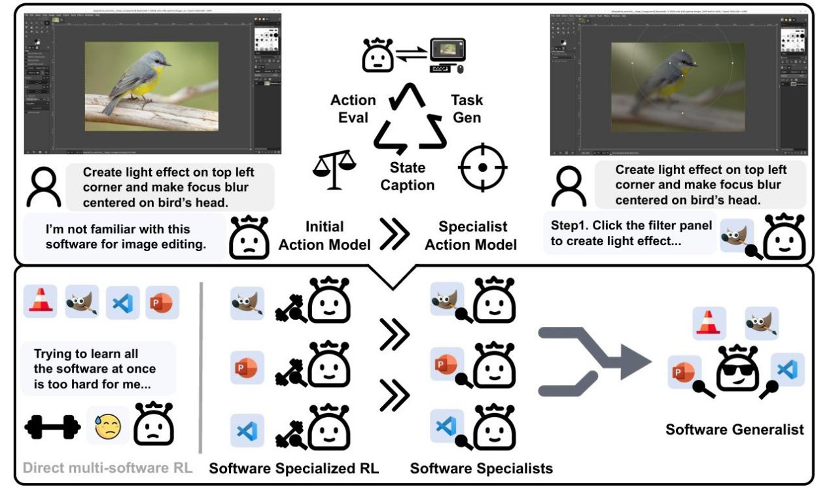
图 2. 总体算法概览
SEAgent 的自主进化能力,源于其内部三大核心组件的协同工作,形成了一个可持续的、自我驱动的学习闭环。
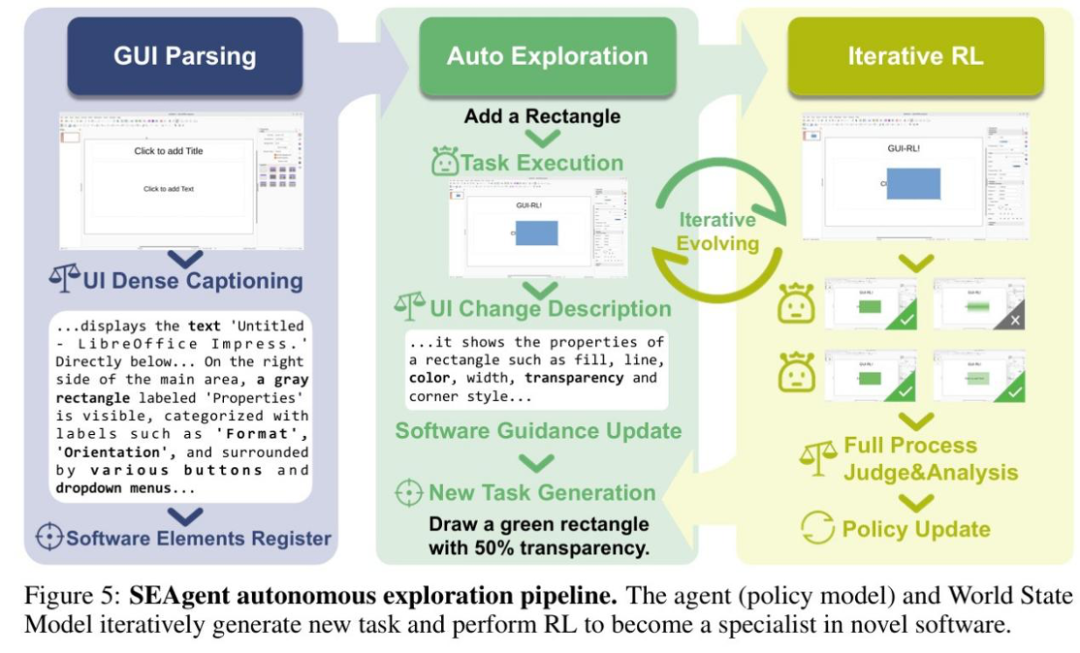
图 3:自动课程学习构建细节
一个精准的 「裁判」 是自主进化的基石。我们发现,现有的开源大视觉语言模型在评判智能体长序列操作时能力不足,当输入过多的历史截图时,其判断准确率甚至会下降 。为了解决这一核心问题,我们着手构建了一个更强大的评判模型 ——
世界状态模型 (World State Model)。
我们的优化策略主要有两点:
经过优化,我们的世界状态模型在性能上大幅缩小了与 GPT-4o 等商业模型的差距,为 SEAgent 框架提供了可靠、稳定的评判能力 。

图 4:算法流程伪代码
在单个智能体的进化之上,我们探索了如何构建一个能操作多种软件的 「通才」 模型。我们发现,直接在多软件环境中训练一个 「通才」,效果并不理想,其性能甚至不如在单一软件上训练的 「专才」 模型 。
为此,我们提出了一套高效的 「专才到通才」(Specialist-to-Generalist)融合策略。该策略分为三步:
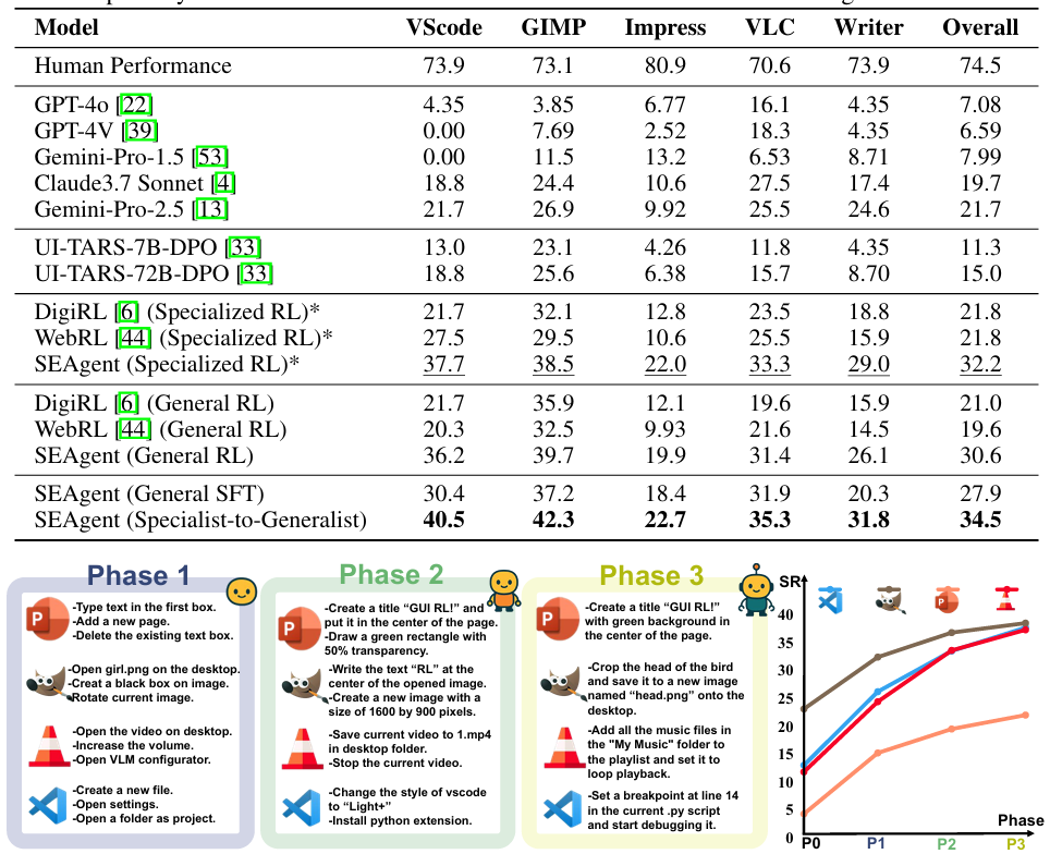
图 5:主要实验结果与多轮训练提升
实验结果证明,这一策略取得了巨大的成功。最终得到的 「通才」 智能体,其综合成功率达到了 34.5%,不仅远超直接训练的通才模型(30.6%),甚至超越了所有 「专才」 模型的性能总和(32.2%),展示了 「先专后通,融合进化」 的强大潜力。
严谨的消融实验证明了这套算法设计的必要性。结果显示,高质量的 世界状态模型 是有效学习的前提;基于探索的 强化学习(GRPO) 显著优于单纯模仿;而能够从错误中学习的 对抗性模仿 机制则带来了关键的性能提升。
这套核心算法被置于一个更大的系统框架中,由 课程生成器 提供循序渐进的任务,并通过 「从专家到通才」 的策略,将多个单一软件的 「专家」能力融合成一个更强大的 「通才」 模型。最终,SEAgent 在 OSWorld 基准测试中取得了显著的性能飞跃,将基线模型的成功率大幅提升,充分验证了其算法框架的先进性与有效性。
文章来自于微信公众号“机器之心”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
