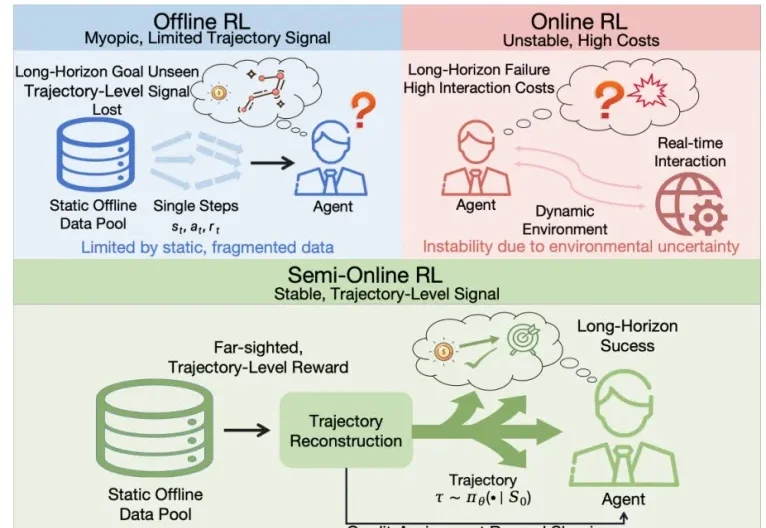
长链路手机AI训练总崩盘?vivo全新半在线RL,仅15k轨迹稳定收敛
长链路手机AI训练总崩盘?vivo全新半在线RL,仅15k轨迹稳定收敛想训练能自动操作手机的GUI(图形用户界面)智能体,总会遇到两难困境:
来自主题: AI技术研报
5441 点击 2026-06-29 09:18
 搜索
搜索
想训练能自动操作手机的GUI(图形用户界面)智能体,总会遇到两难困境:
Agent从来不是不会用浏览器,只是浪费太多时间在探索——BrowserBC把人类轨迹蒸馏成可复用Skill来完成Behavior Cloning,用户点一遍,Agent照着就能跑通。Einsia AI旗下Navers Lab发布的开源项目BrowserBC给出的答案,是一条三步范式:录制→转写成Skill→交付执行。

扩散模型又被玩出新花样了。
独家获悉,GUI Agent(图形用户界面智能体)执行平台 「Core-Mate」 近日宣布完成数千万人民币融资。核心团队主要来自字节跳动,成员在用户产品、业务增长和商业化落地中积累了系统经验。在团队看来,下一代 AI 产品的关键不只在模型能力,也在入口、场景和用户行为。
如何让 Agent 把浏览器用得更 6,一直是一个还没有完美解答的课题。周末躺床上刷 GitHub trending,看到一个项目名字叫 BrowserAct。简介写着:AI Agent 操作真实浏览器。
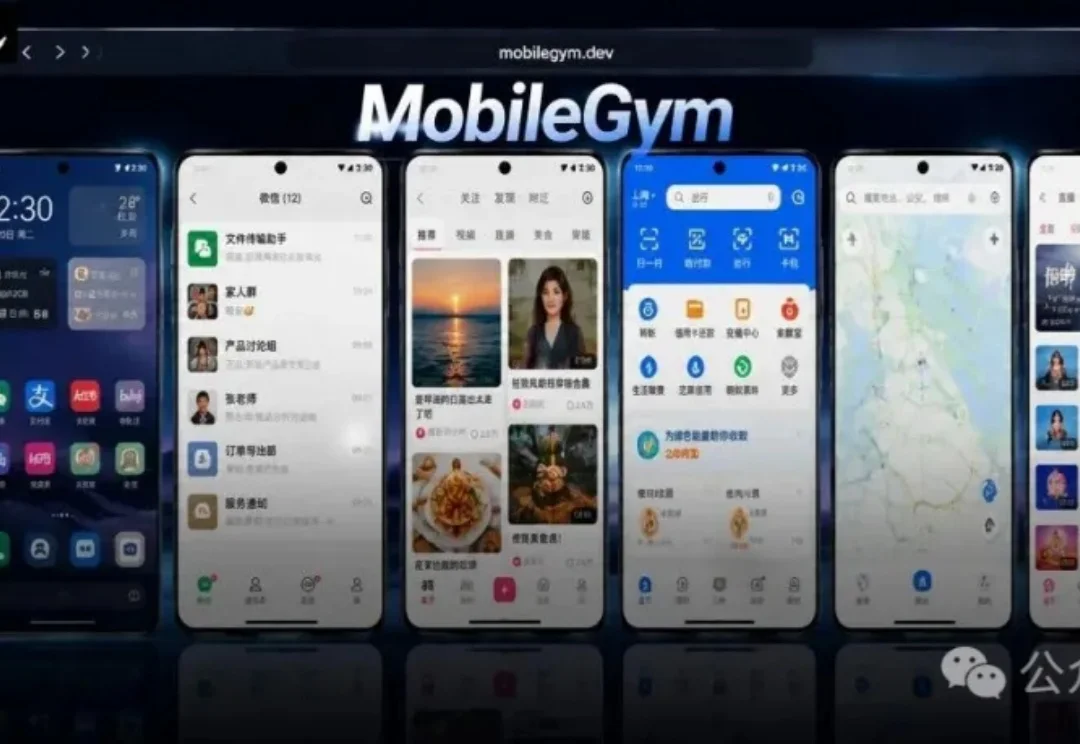
中科院自动化所模式识别实验室开源MobileGym,运行在浏览器里的高并发安卓仿真平台,完全自定义,告别模拟器风控与真机成本,一个平台搞定Mobile Agent训练与评测,甚至还能玩原神!
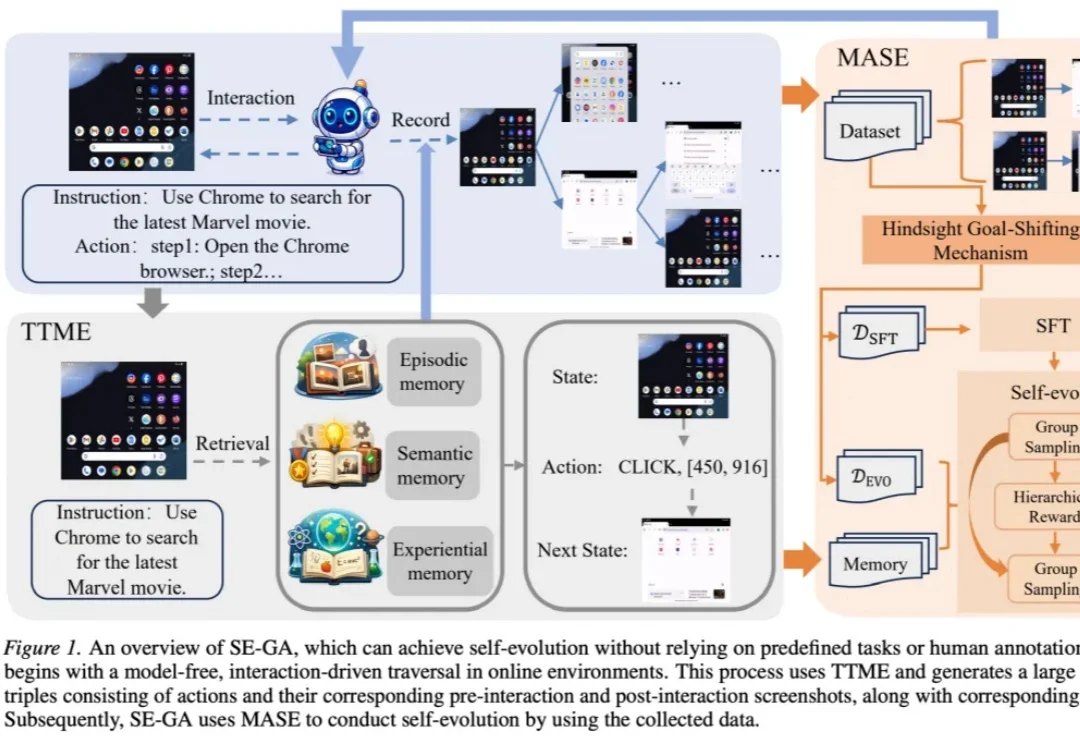
本文团队长期从事负责任的人工智能与人工智能赋能社会科学相关研究,围绕视觉生成大模型安全治理、智能体安全等方向开展系统性工作,相关成果发表于AAAI、ICML、TMM 等国际期刊与会议。
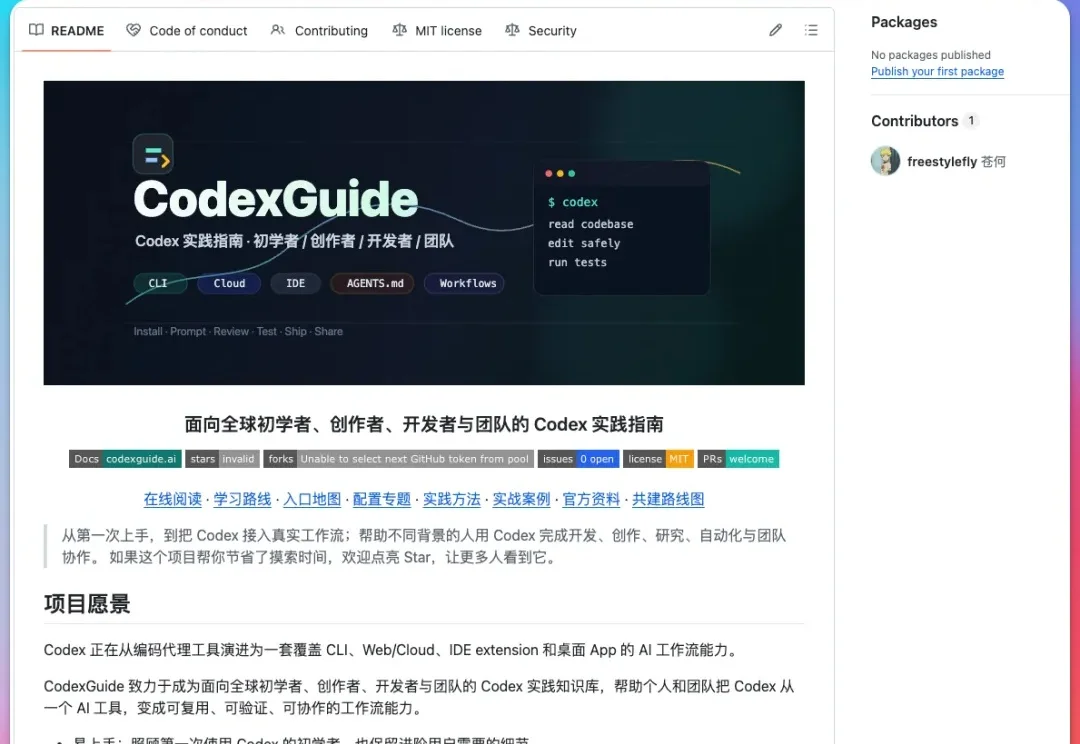
大家好,我是苍何。 今天,我们正式推出 CodexGuide。
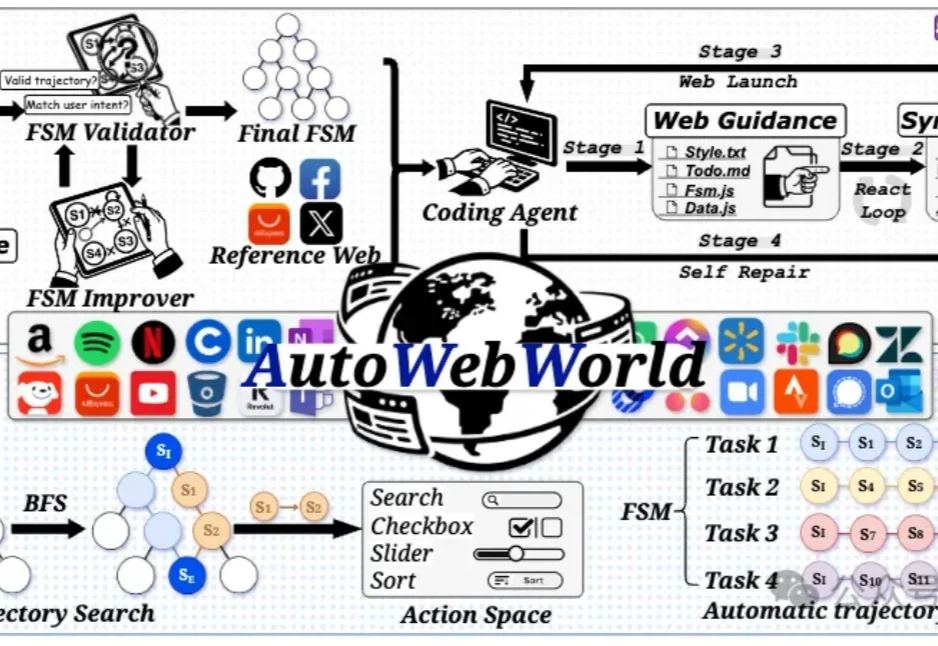
训练一个真正会用网页的GUI Agent,最自然的思路通常是: 去真实网站上操作,收集轨迹,再拿来训练。

前段时间开源了 guizang-ppt-skill,之后我自己用它做内容的时候发现一件事。