庞若鸣还有苹果论文?改善预训练高质量数据枯竭困境
庞若鸣还有苹果论文?改善预训练高质量数据枯竭困境数月前,苹果基础模型团队负责人、杰出工程师庞若鸣(Ruoming Pang)离职加入 Meta。扎克伯格豪掷两亿美元招揽庞若鸣加入超级智能团队。根据庞若鸣的领英信息,他已在 Meta 工作了大约三个月的时间。
来自主题: AI技术研报
9219 点击 2025-09-24 09:54
 搜索
搜索
数月前,苹果基础模型团队负责人、杰出工程师庞若鸣(Ruoming Pang)离职加入 Meta。扎克伯格豪掷两亿美元招揽庞若鸣加入超级智能团队。根据庞若鸣的领英信息,他已在 Meta 工作了大约三个月的时间。

LeCun 这次不是批评 LLM,而是亲自改造。当前 LLM 的训练(包括预训练、微调和评估)主要依赖于在「输入空间」进行重构与生成,例如预测下一个词。 而在 CV 领域,基于「嵌入空间」的训练目标,如联合嵌入预测架构(JEPA),已被证明远优于在输入空间操作的同类方法。
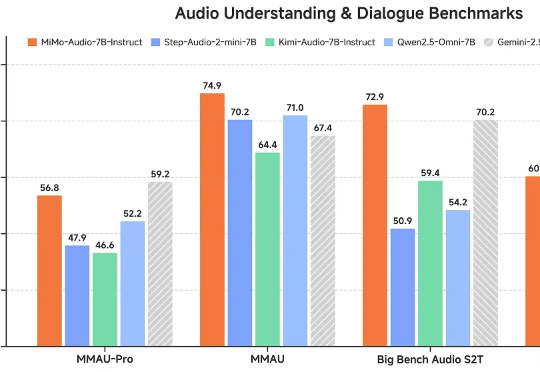
这一瓶颈如今被打破。小米正式开源首个原生端到端语音模型——Xiaomi-MiMo-Audio,它基于创新预训练架构和上亿小时训练数据,首次在语音领域实现基于 ICL 的少样本泛化,并在预训练观察到明显的“涌现”行为。
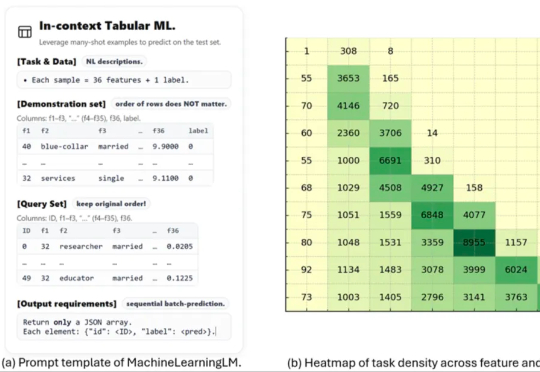
这项名为 MachineLearningLM 的新研究突破了这一瓶颈。该研究提出了一种轻量且可移植的「继续预训练」框架,无需下游微调即可直接通过上下文学习上千条示例,在金融、健康、生物信息、物理等等多个领域的二分类 / 多分类任务中的准确率显著超越基准模型(Qwen-2.5-7B-Instruct)以及最新发布的 GPT-5-mini。
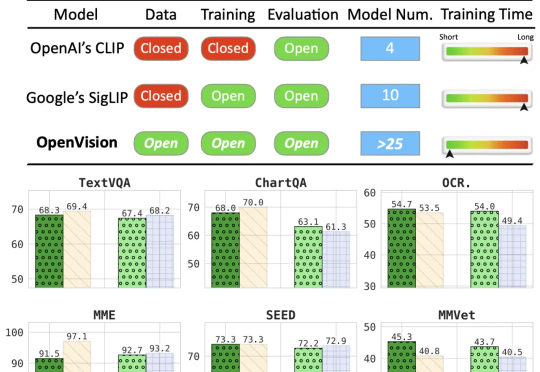
本文来自加州大学圣克鲁兹分校(UCSC)、苹果公司(Apple)与加州大学伯克利分校(UCB)的合作研究。第一作者刘彦青,本科毕业于浙江大学,现为UCSC博士生,研究方向包括多模态理解、视觉-语言预训
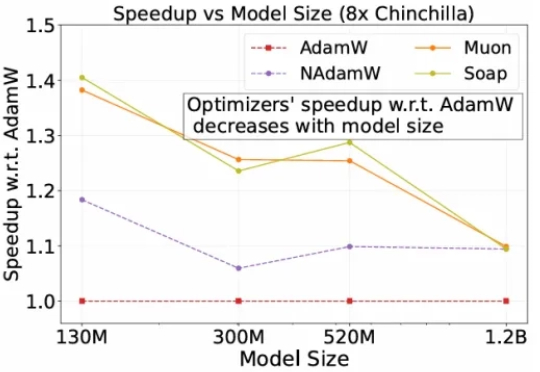
自2014 年提出以来,Adam 及其改进版 AdamW 长期占据开放权重语言模型预训练的主导地位,帮助模型在海量数据下保持稳定并实现较快收敛。
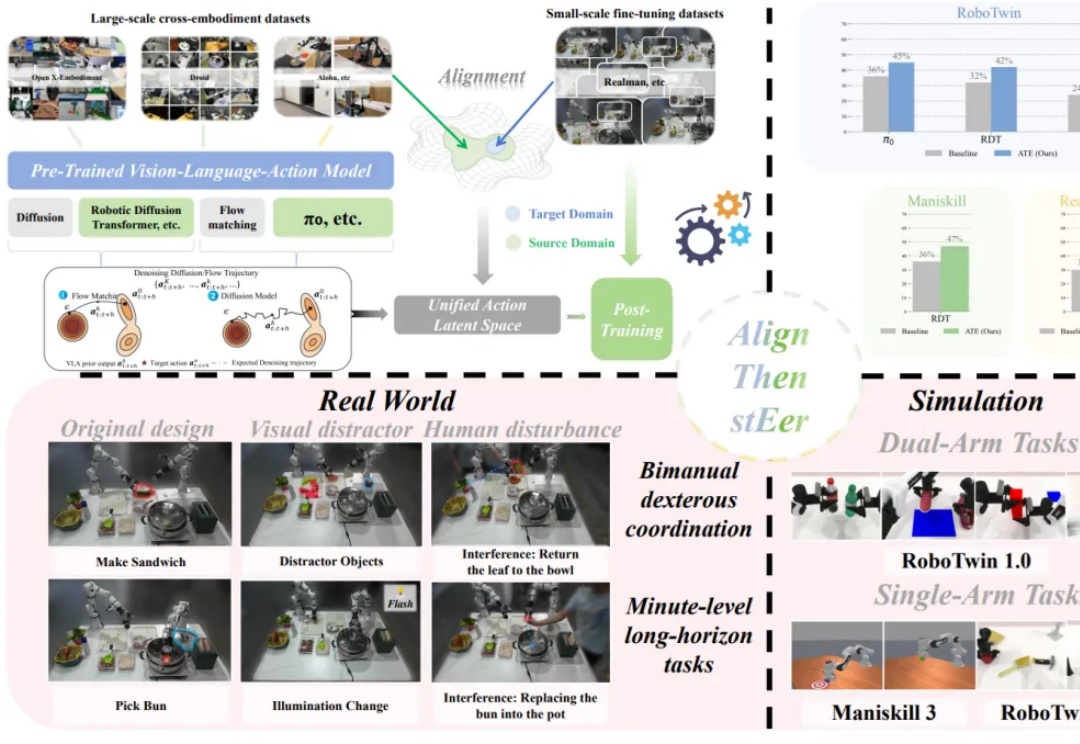
在多模态大模型的基座上,视觉 - 语言 - 动作(Visual-Language-Action, VLA)模型使用大量机器人操作数据进行预训练,有望实现通用的具身操作能力。
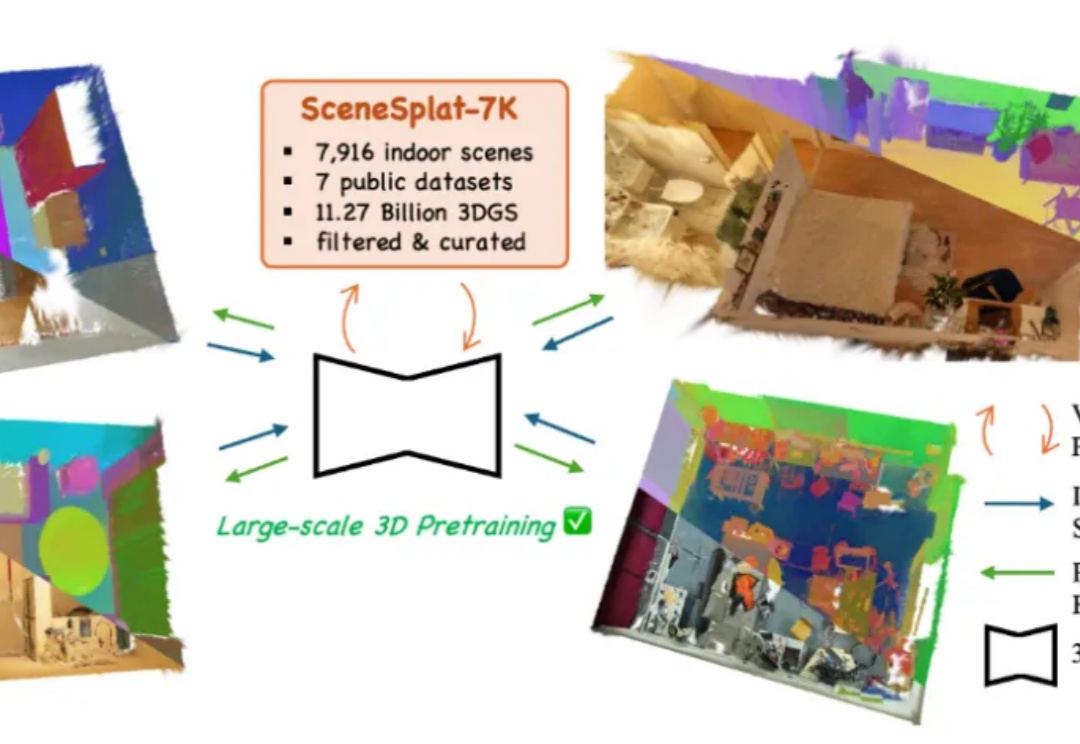
开放词汇识别与分类对于全面理解现实世界的 3D 场景至关重要。目前,所有现有方法在训练或推理过程中都依赖于 2D 或文本模态。这凸显出缺乏能够单独处理 3D 数据以进行端到端语义学习的模型,以及训练此类模型所需的数据。与此同时,3DGS 已成为各种视觉任务中 3D 场景表达的重要标准之一。

为了降低大模型预训练成本,最近两年,出现了很多新的优化器,声称能相比较AdamW,将预训练加速1.4×到2×。但斯坦福的一项研究,指出不仅新优化器的加速低于宣称值,而且会随模型规模的增大而减弱,该研究证实了严格基准评测的必要性。
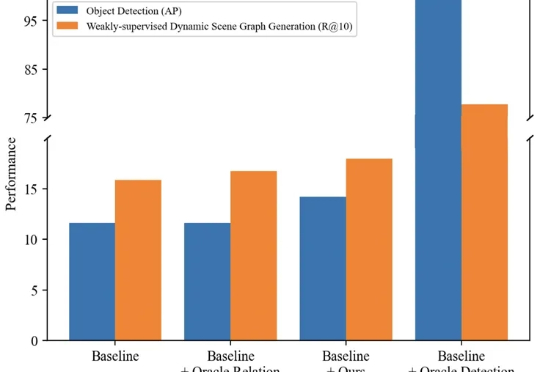
本文主要介绍来自该团队的最新论文:TRKT,该任务针对弱监督动态场景图任务展开研究,发现目前的性能瓶颈在场景中目标检测的质量,因为外部预训练的目标检测器在需要考虑关系信息和时序上下文的场景图视频数据上检测结果欠佳。