
前阿里、字节大模型带头人杨红霞创业:大模型预训练,不是少数顶尖玩家的算力竞赛
前阿里、字节大模型带头人杨红霞创业:大模型预训练,不是少数顶尖玩家的算力竞赛杨红霞要走一条和阿里、字节截然不同的模型训练之路。
来自主题: AI资讯
9739 点击 2025-10-30 12:14
 搜索
搜索
杨红霞要走一条和阿里、字节截然不同的模型训练之路。
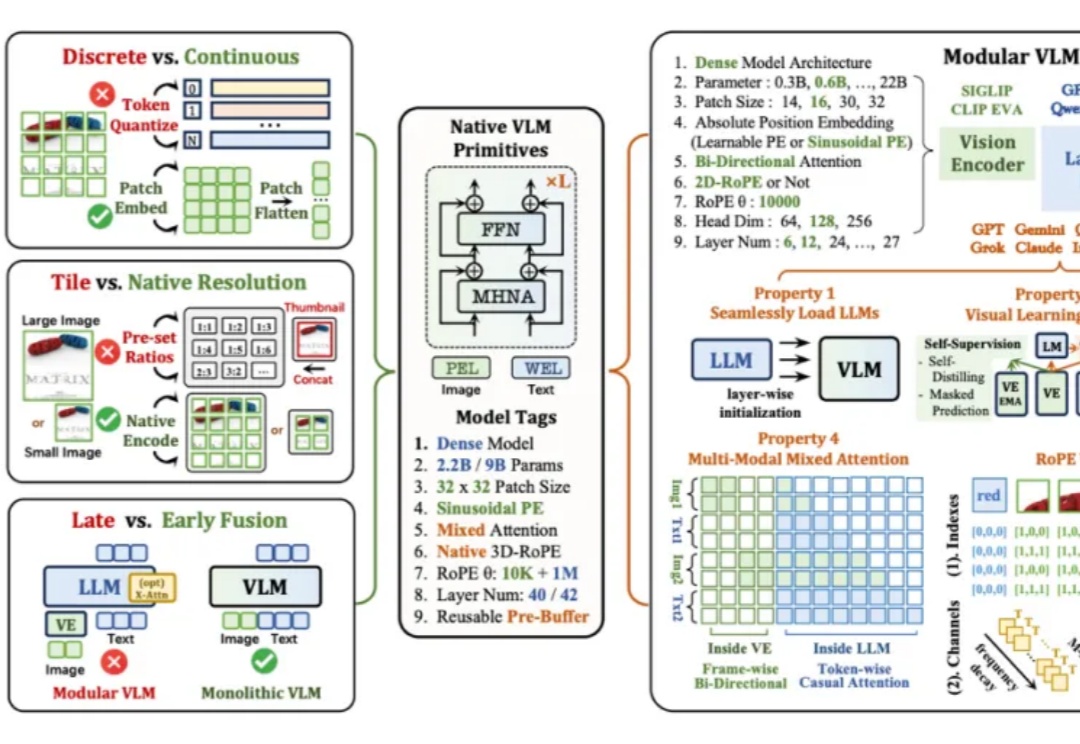
当下主流的视觉语言模型(Vision-Language Models, VLM),通常都采用这样一种设计思路:将预训练的视觉编码器与大语言模型通过投影层拼接起来。这种模块化架构成就了当前 VLM 的辉煌,但也带来了一系列新的问题——多阶段训练复杂、组件间语义对齐成本高,不同模块的扩展规律难以协调。
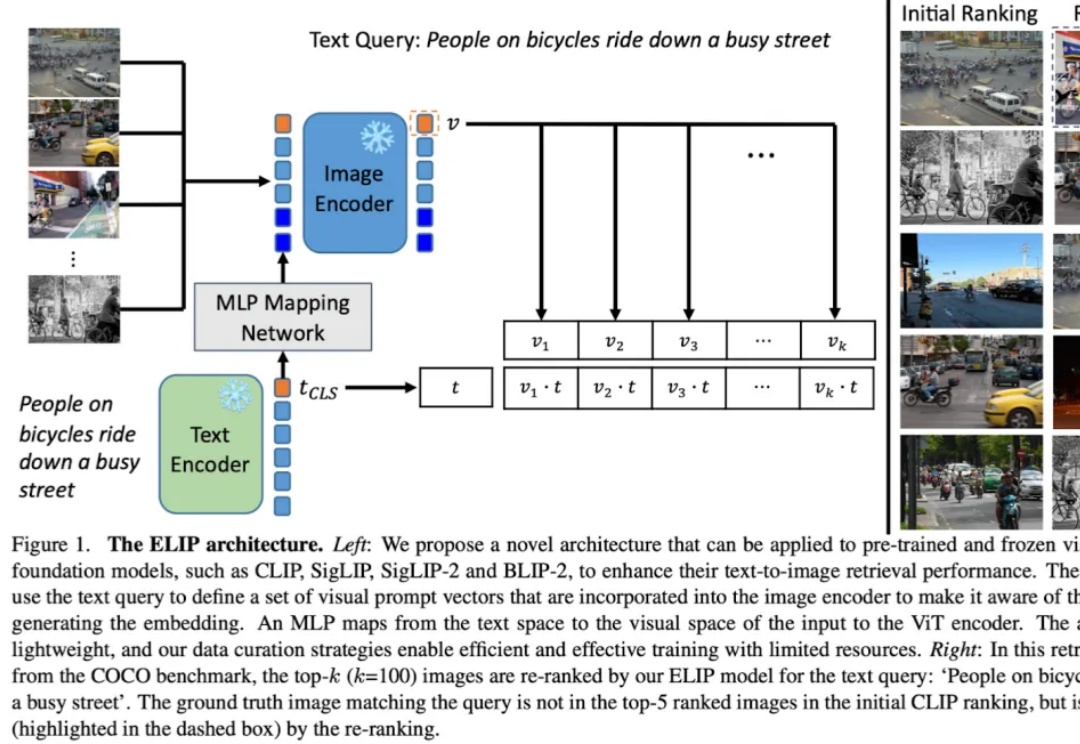
多模态图片检索是计算机视觉和多模态机器学习领域很重要的一个任务。现在大家做多模态图片检索一般会用 CLIP/SigLIP 这种视觉语言大模型,因为他们经过了大规模的预训练,所以 zero-shot 的能力比较强。

彭超曾在华为印度、阿里任消费硬件业务1号位;联合创始人齐炜祯为Multi-token架构开创学者,被Deepseek、Qwen引入预训练方法。

预训练的核心是推动损失函数下降,这是我们一直追求的唯一目标。

在某种程度上,GPT-5可以被视作是o3.1。 该观点出自OpenAI研究副总裁Jerry Tworek的首次播客采访,而Jerry其人,正是o1模型的主导者之一。

LLaVA 于 2023 年提出,通过低成本对齐高效连接开源视觉编码器与大语言模型,使「看图 — 理解 — 对话」的多模态能力在开放生态中得以普及,明显缩小了与顶级闭源模型的差距,标志着开源多模态范式的重要里程碑。
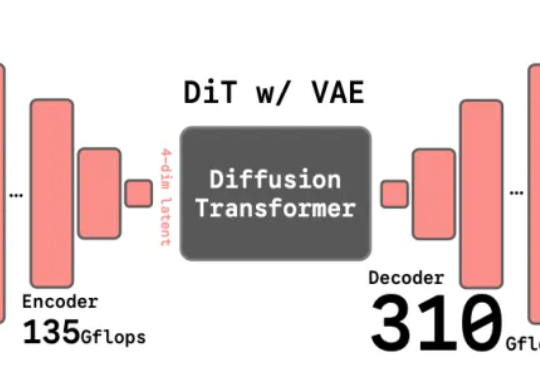
谢赛宁团队最新研究给出了答案——VAE的时代结束,RAE将接力前行。其中表征自编码器RAE(Representation Autoencoders)是一种用于扩散Transformer(DiT)训练的新型自动编码器,其核心设计是用预训练的表征编码器(如DINO、SigLIP、MAE 等)与训练后的轻量级解码器配对,从而替代传统扩散模型中依赖的VAE(变分自动编码器)。

为破解机器人产业「一机一调」的开发困境,智源研究院开源了通用「小脑基座」RoboBrain-X0。它创新地学习任务「做什么」而非「怎么动」,让一个预训练模型无需微调,即可驱动多种不同构造的真实机器人,真正实现了零样本跨本体泛化。
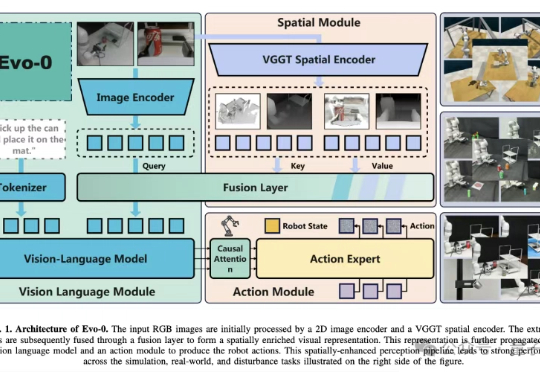
VLA模型通常建立在预训练视觉语言模型(VLM)之上,仅基于2D图像-文本数据训练,缺乏真实世界操作所需的3D空间理解能力。