
OpenAI大溃败!GPT-5「换皮」GPT-4o,两年半预训练0突破
OpenAI大溃败!GPT-5「换皮」GPT-4o,两年半预训练0突破OpenAI,亟需一场翻身仗!今天,全网最大的爆料:GPT-5基石实为GPT-4o。自4o发布之后,内部预训练屡屡受挫,几乎沦为「弃子」。
来自主题: AI资讯
8005 点击 2025-12-01 10:03
 搜索
搜索
OpenAI,亟需一场翻身仗!今天,全网最大的爆料:GPT-5基石实为GPT-4o。自4o发布之后,内部预训练屡屡受挫,几乎沦为「弃子」。
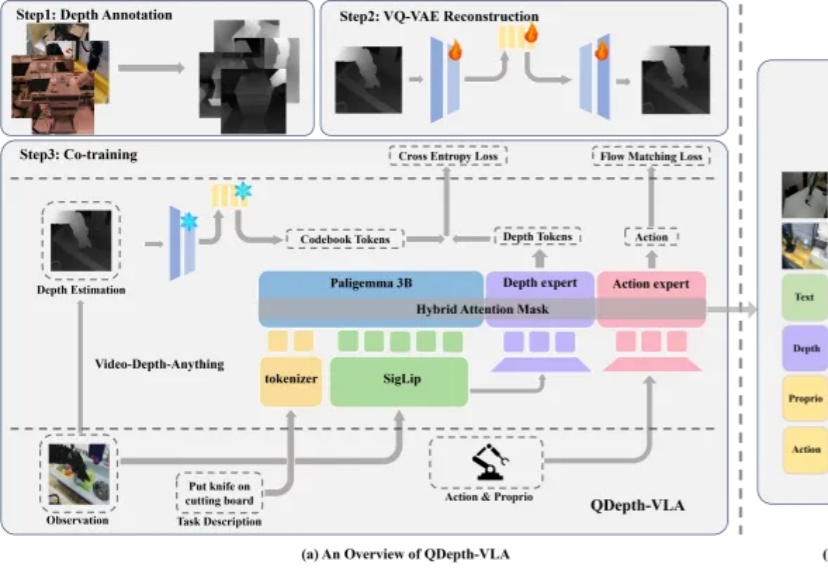
视觉-语言-动作模型(VLA)在机器人操控领域展现出巨大潜力。通过赋予预训练视觉-语言模型(VLM)动作生成能力,机器人能够理解自然语言指令并在多样化场景中展现出强大的泛化能力。然而,这类模型在应对长时序或精细操作任务时,仍然存在性能下降的现象。

AI正从「规模时代」,重新走向「科研时代」。这是Ilya大神在最新采访中发表的观点。这一次,Ilya一顿输出近2万字,信息量爆炸,几乎把当下最热门的AI话题都聊了个遍:Ilya认为,目前主流的「预训练 + Scaling」路线已经明显遇到瓶颈。与其盲目上大规模,不如把注意力放回到「研究范式本身」的重构上。

在视觉处理任务中,Vision Transformers(ViTs)已发展成为主流架构。然而,近期研究表明,ViT 模型的密集特征中会出现部分与局部语义不一致的伪影(artifact),进而削弱模型在精细定位类任务中的性能表现。因此,如何在不耗费大量计算资源的前提下,保留 ViT 模型预训练核心信息并消除密集特征中的伪影?

无需额外训练即可适配预训练生成模型的编辑方法,凭借灵活、高效的特性,已成为视觉生成领域的研究热点。这类方法通过操控 Attention 机制(如 Prompt-to-Prompt、MasaCtrl)实现文本引导编辑,但当前技术存在两大核心痛点,严重限制其在复杂场景的应用
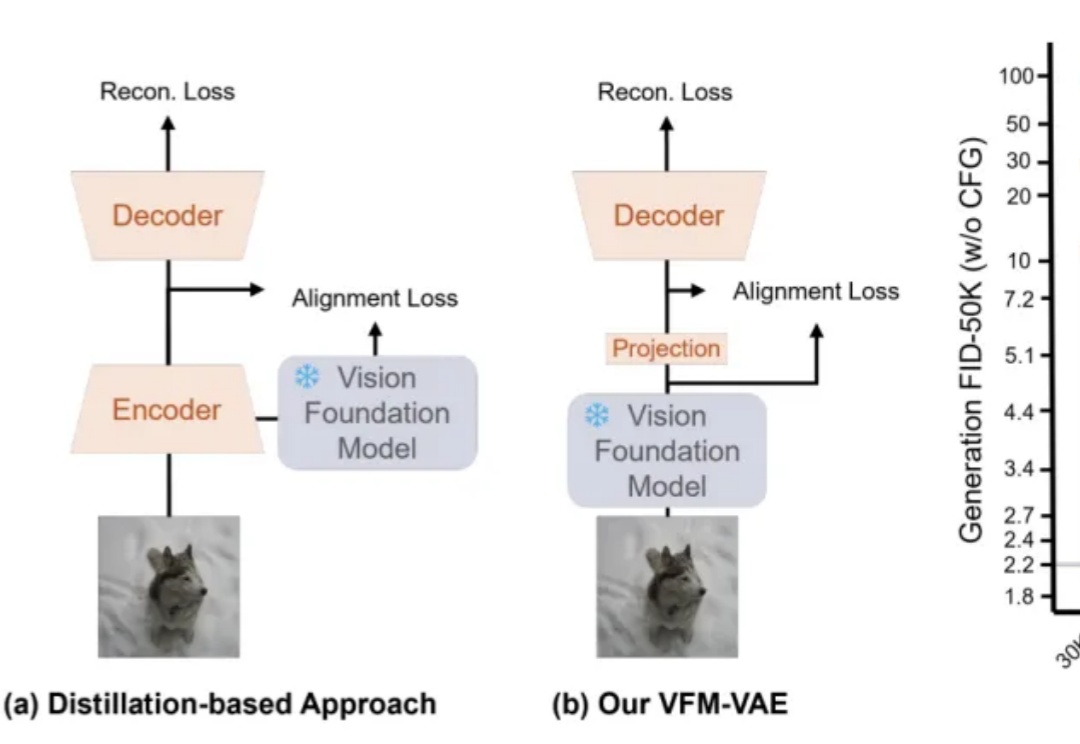
近期,RAE(Diffusion Transformers with Representation Autoencoders)提出以「 冻结的预训练视觉表征」直接作为潜空间,以显著提升扩散模型的生成性能。
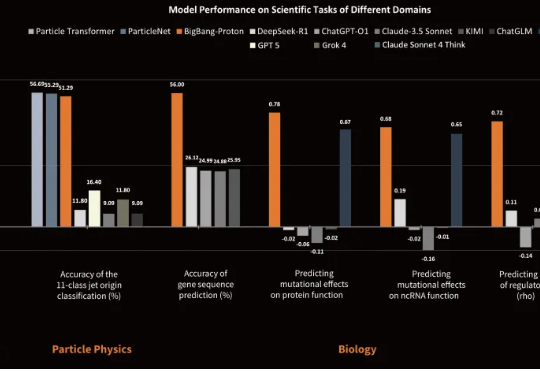
近日,专注于研发物质世界基座模型的公司超越对称(上海)技术有限公司(超对称)发布了新版基座模型 BigBang-Proton,成功实现多个真实世界的专业学科问题与 LLM 的统一预训练和推理,挑战了 Sam Altman 和主流的 AGI 技术路线。

当前机器人领域,基础模型主要基于「视觉-语言预训练」,这样可将现有大型多模态模型的语义泛化优势迁移过来。但是,机器人的智能确实能随着算力和数据的增加而持续提升吗?我们能预测这种提升吗?
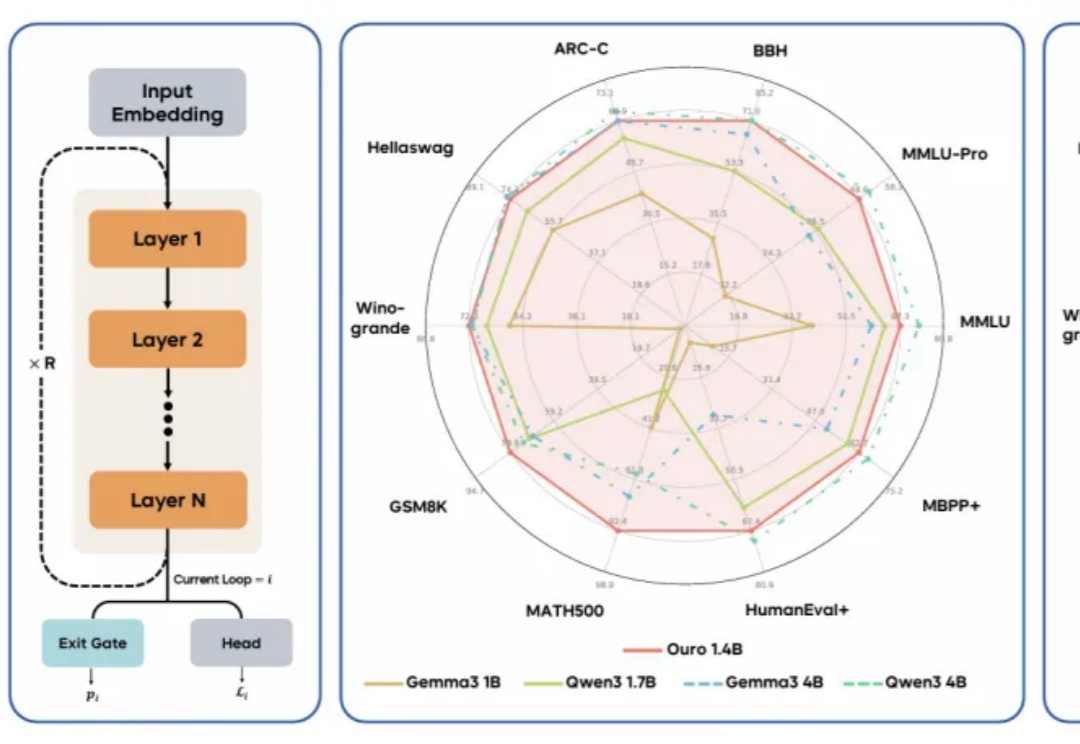
现代 LLM 通常依赖显式的文本生成过程(例如「思维链」)来进行「思考」训练。这种策略将推理任务推迟到训练后的阶段,未能充分挖掘预训练数据中的潜力。
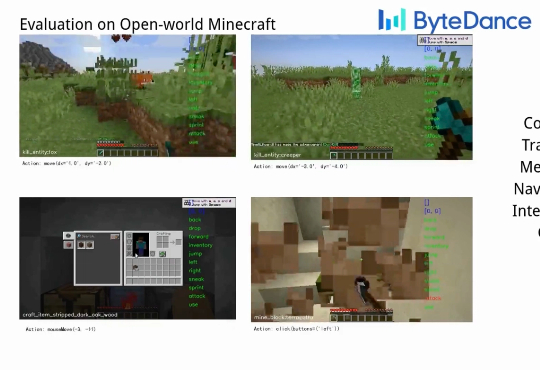
Game-TARS基于统一、可扩展的键盘—鼠标动作空间训练,可在操作系统、网页与模拟环境中进行大规模预训练。依托超5000亿标注量级的多模态训练数据,结合稀疏推理(Sparse-Thinking) 与衰减持续损失(decaying continual loss),大幅提升了智能体的可扩展性和泛化性。