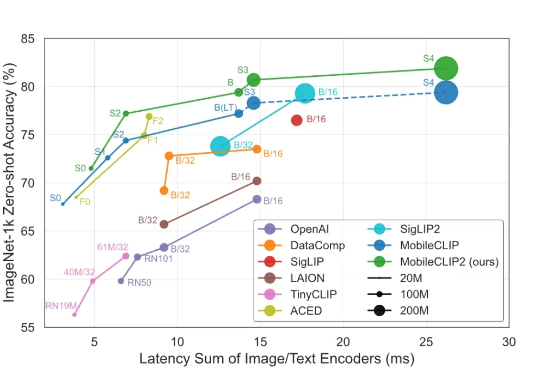
苹果最新模型,5年前的iPhone能跑
苹果最新模型,5年前的iPhone能跑智东西9月1日消息,苹果又公布了大模型研发新进展! 8月28日,苹果在arXiv发布新论文,介绍新一代多模态基础模型MobileCLIP2及其背后的多模态强化训练机制,同天在GitHub、Hugging Face上开源了模型的预训练权重和数据生成代码。
来自主题: AI技术研报
8240 点击 2025-09-02 11:04
 搜索
搜索
智东西9月1日消息,苹果又公布了大模型研发新进展! 8月28日,苹果在arXiv发布新论文,介绍新一代多模态基础模型MobileCLIP2及其背后的多模态强化训练机制,同天在GitHub、Hugging Face上开源了模型的预训练权重和数据生成代码。
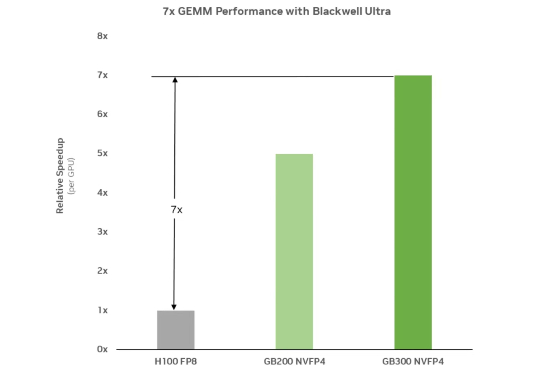
前些天,DeepSeek 在发布 DeepSeek V3.1 的文章评论区中,提及了 UE8M0 FP8 的量化设计,声称是针对即将发布的下一代国产芯片设计。
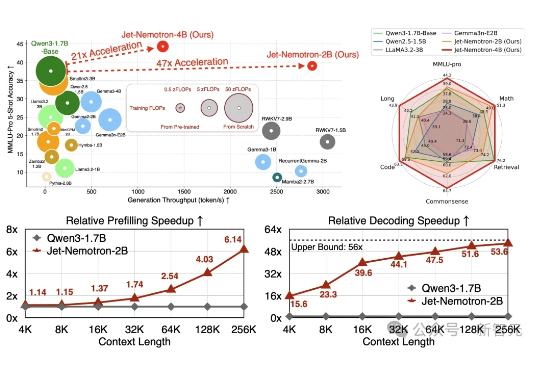
Jet-Nemotron是英伟达最新推出的小模型系列(2B/4B),由全华人团队打造。其核心创新在于提出后神经架构搜索(PostNAS)与新型线性注意力模块JetBlock,实现了从预训练Transformer出发的高效架构优化。
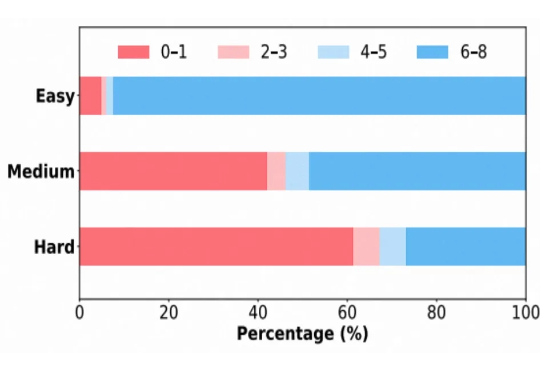
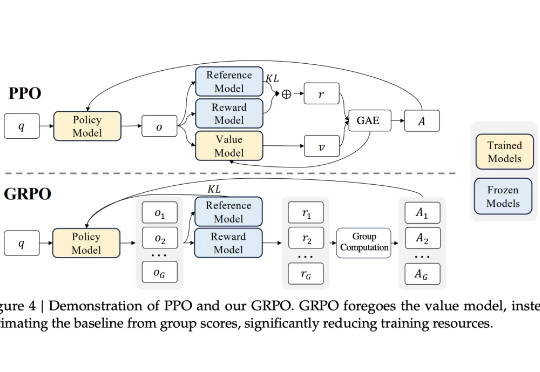
近年来,强化学习(Reinforcement Learning, RL)在提升大语言模型(LLM)复杂推理能力方面展现出显著效果,广泛应用于数学解题、代码生成等任务。通过 RL 微调的模型常在推理性能上超越仅依赖监督微调或预训练的模型。
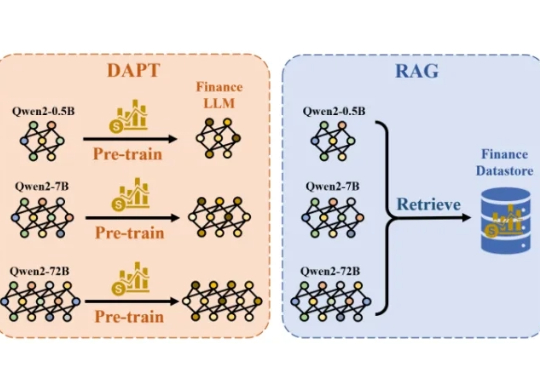
一个小解码器让所有模型当上领域专家!华人团队新研究正在引起热议。 他们提出了一种比目前业界主流采用的DAPT(领域自适应预训练)和RAG(检索增强生成)更方便、且成本更低的方法。
众所周知,大型语言模型的训练通常分为两个阶段。第一阶段是「预训练」,开发者利用大规模文本数据集训练模型,让它学会预测句子中的下一个词。第二阶段是「后训练」,旨在教会模型如何更好地理解和执行人类指令。

OpenAI前研究员、Meta「AI梦之队员」毕书超在哥大指出:AGI就在眼前,突破需高质数据、好奇驱动探索与高效算法;Scaling Law依旧有效,规模决定智能,终身学习才是重点。
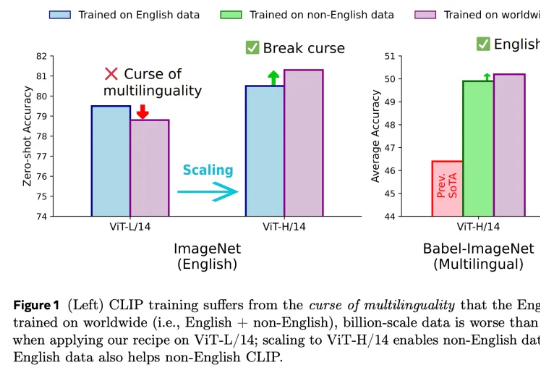
在人工智能领域,对比语言 - 图像预训练(CLIP) 是一种流行的基础模型,由 OpenAI 提出
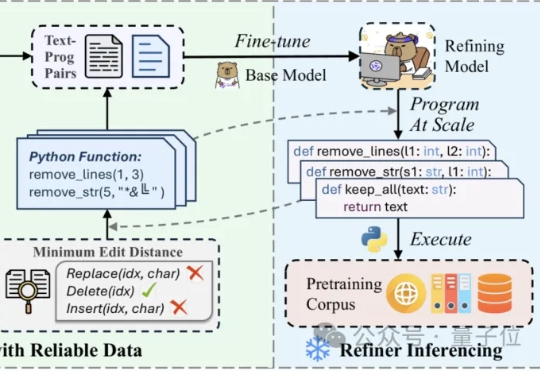
在噪声污染严重影响预训练数据的质量时,如何能够高效且精细地精炼数据? 中科院计算所与阿里Qwen等团队联合提出RefineX,一个通过程序化编辑任务实现大规模、精准预训练数据精炼的新框架。

随着基础大模型在通用能力上的边际效益逐渐递减、大模型技术红利向产业端渗透,AI的技术范式也开始从原来的注重“预训练”向注重“后训练”转移。后训练(Post-training),正从过去锦上添花的“调优”环节,演变为决定模型最终价值的“主战场”。