
视频生成太慢?英伟达、谢赛宁等发布TMD框架,实现70倍加速
视频生成太慢?英伟达、谢赛宁等发布TMD框架,实现70倍加速近年来,大规模视频扩散模型在视频生成领域取得了显著进展。然而,采样效率低下仍然是这类模型的核心瓶颈。
来自主题: AI技术研报
9475 点击 2026-03-11 15:05
 搜索
搜索
近年来,大规模视频扩散模型在视频生成领域取得了显著进展。然而,采样效率低下仍然是这类模型的核心瓶颈。

香港科技大学 & 北航 & 商汤等提出了一个专门面向视频生成扩散模型的 QAT 范式 ——QVGen,在 3-bit / 4-bit 都能把质量拉回来,并且让 4-bit 首次接近全精度表现成为现实。该论文现已被 ICLR 高分接收:rebuttal 前 88666(top 1.4%),rebuttal 后 88886 (top 0.5%)。

近年来,视频扩散模型在 “真实感、动态性、可控性” 上进展飞快,但它们大多仍停留在纯 RGB 空间。模型能生成好看的视频,却缺少对三维几何的显式建模。这让许多世界模型(world model)导向的应用(空间推理、具身智能、机器人、自动驾驶仿真等)难以落地,因为这些任务不仅需要像素,还需要完整地模拟 4D 世界。

就在一周前,全宇宙最火爆的推理框架 SGLang 官宣支持了 Diffusion 模型,好评如潮。团队成员将原本在大语言模型推理中表现突出的高性能调度与内核优化,扩展到图像与视频扩散模型上,相较于先前的视频和图像生成框架,速度提升最高可达 57%:
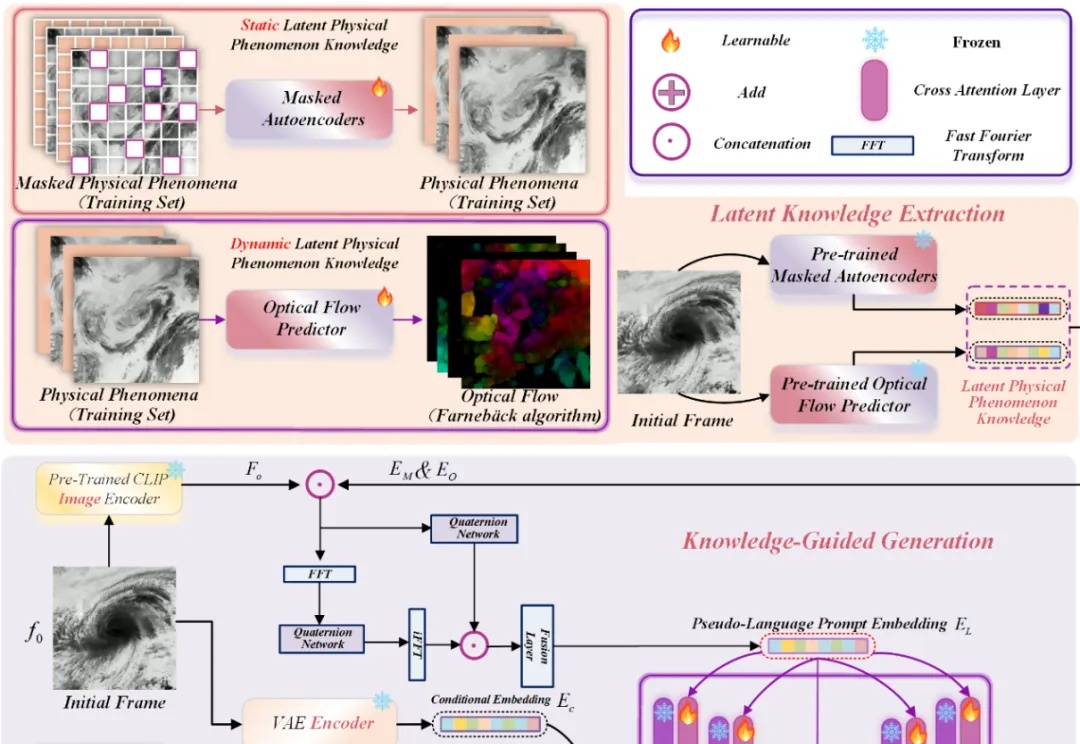
近年来,Stable Diffusion、CogVideoX 等视频生成模型在自然场景中表现惊艳,但面对科学现象 —— 如流体模拟或气象过程 —— 却常常 “乱画”:如下视频所示,生成的流体很容易产生违背物理直觉的现象,比如气旋逆向旋转或整体平移等等。
近年来,随着扩散模型(Diffusion Models)和扩散 Transformer(DiT)在视频生成领域的广泛应用,AI 合成视频的质量和连贯性有了飞跃式提升。像 OpenAI Sora、HunyuanVideo、Wan2.1 等大模型,已经能够生成结构清晰、细节丰富且高度连贯的长视频内容,为数字内容创作、虚拟世界和多媒体娱乐带来了巨大变革。
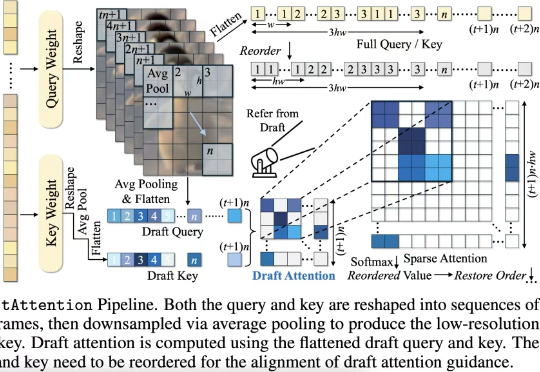
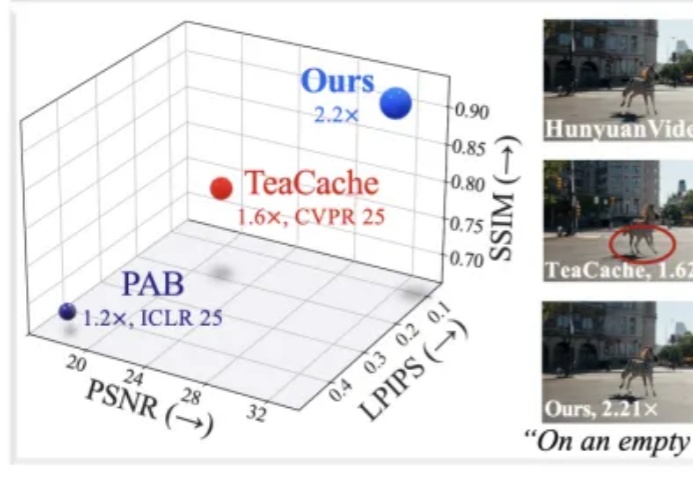
在高质量视频生成任务中,扩散模型(Diffusion Models)已经成为主流。然而,随着视频长度和分辨率的提升,Diffusion Transformer(DiT)模型中的注意力机制计算量急剧增加,成为推理效率的最大瓶颈。

扩散模型在视频合成任务中取得了显著成果,但其依赖迭代去噪过程,带来了巨大的计算开销。尽管一致性模型(Consistency Models)在加速扩散模型方面取得了重要进展,直接将其应用于视频扩散模型却常常导致时序一致性和外观细节的明显退化。

三维场景是构建世界模型、具身智能等前沿科技的关键环节之一。

最近,来自大连理工和莫纳什大学的团队提出了物理真实的视频生成框架 VLIPP。通过利用视觉语言模型来将物理规律注入到视频扩散模型的方法来提升视频生成中的物理真实性。