都让让!赛博女娲蒸馏一切,让乔布斯马斯克集体给你打工
都让让!赛博女娲蒸馏一切,让乔布斯马斯克集体给你打工继skill同事之后,有聪明人迁移泛化了一下: 既然可以蒸馏任何人,那为什么不让乔布斯马斯克给我打工呢?
来自主题: AI技术研报
8185 点击 2026-04-21 09:22
 搜索
搜索
继skill同事之后,有聪明人迁移泛化了一下: 既然可以蒸馏任何人,那为什么不让乔布斯马斯克给我打工呢?

办公室里,一排排工位整整齐齐,每个人对着屏幕敲敲打打,看起来和平常没什么两样。
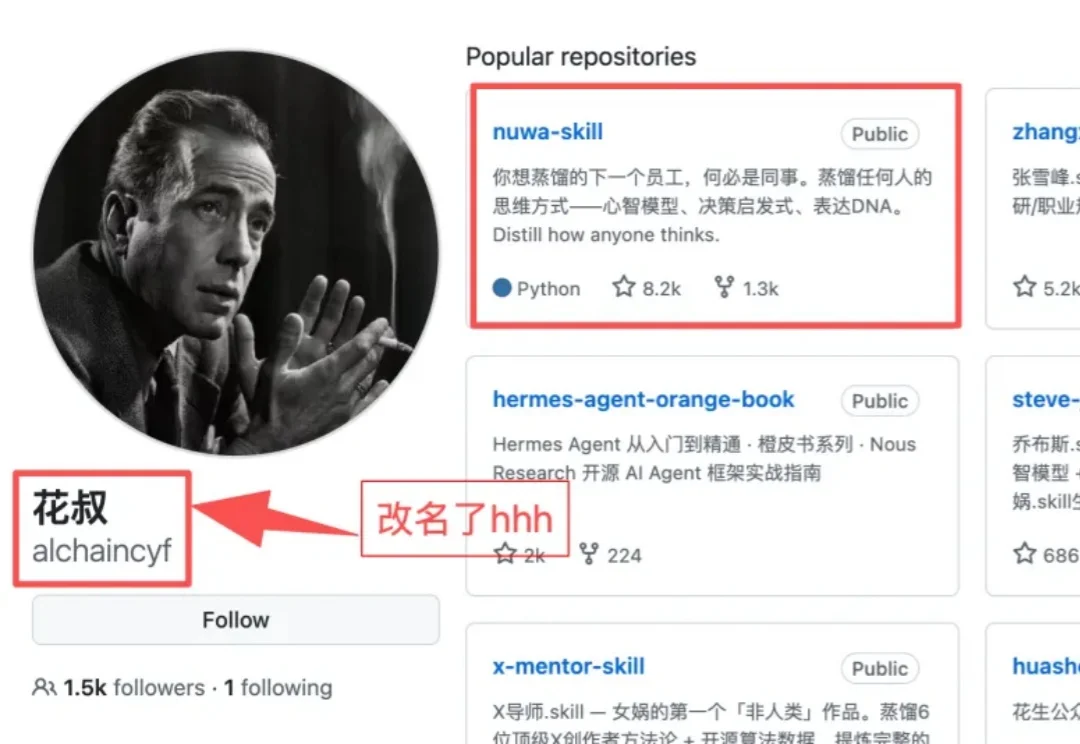
「小猫补光灯」的作者花生...啊不...这人改名叫花叔了...hhhh,又整了一个新活:一周 8000 多个 star

近期,一个叫“同事.skill”的GitHub项目5天收获超过6600颗星,冲上热搜。紧接着,“前任.skill”“老板.skill”“父母.skill”十余个衍生项目接连涌现。网友辣评:“同事,散是Token,聚是Skill。”
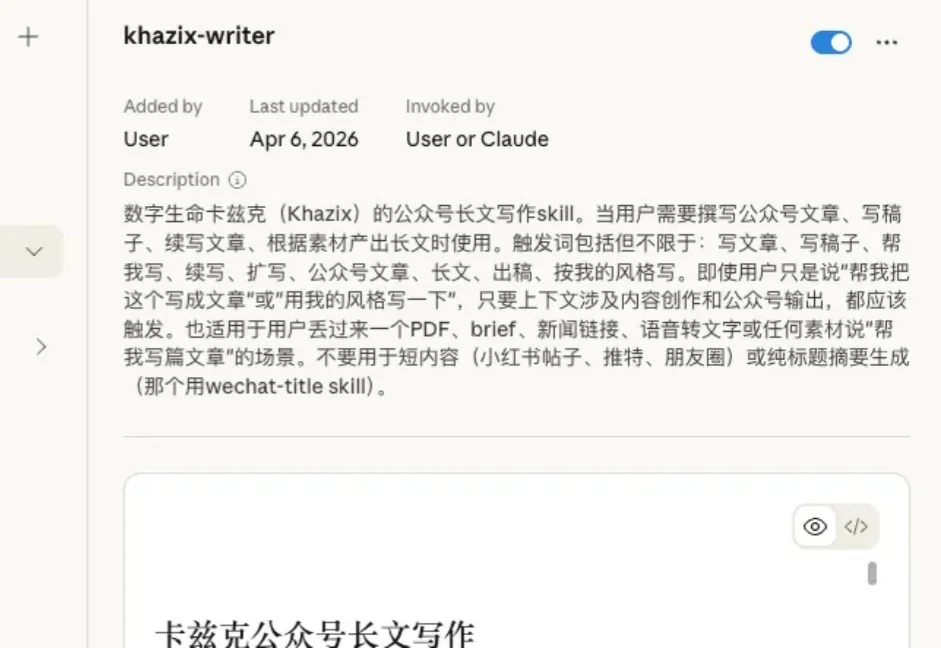
故事是这样的。 最近各种把同事、把前任、把各种知识蒸馏成Skill的东西特别火。
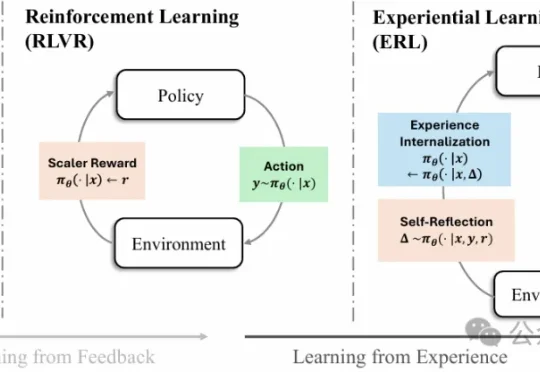
强化学习已经成为大模型后训练阶段的核心方法之一,但一个长期存在的难题始终没有真正解决:现实环境中的反馈往往稀疏且延迟,模型很难从简单的奖励信号中推断出应该如何调整行为。

此事件震动了整个硅谷。虽然此前因为抨击其他 AI 公司「蒸馏」其模型,Anthropic 成为了众矢之的,但目前 Anthropic 在科技界获得了巨大的声援。包括竞争对手 OpenAI、谷歌都公开表态支持 Anthropic 坚守底线的决定。

最近,炸裂消息一个接一个。首先,DeepSeek V4将在一周内上线。第二,它跳过英伟达,把访问权限首先给了某国内芯片厂商。另外,Anthropic因为蒸馏事件,也被群嘲了。

今天,美国大模型独角兽Anthropic连续发布多则推文、博客,指控DeepSeek、月之暗面和MiniMax三家中国AI实验室,正对Claude进行“工业级规模的蒸馏攻击”。

刚刚, Anthropic 发推称,DeepSeek、Moonshot AI和MiniMax三家国内的 AI 公司对Claude进行大规模的蒸馏攻击。OK, A 社你真的很讨厌中国公司了。简单说就是:这三家公司用大量假账号,疯狂地向 Claude 提问,然后拿 Claude 的回答去训练自己的模型。