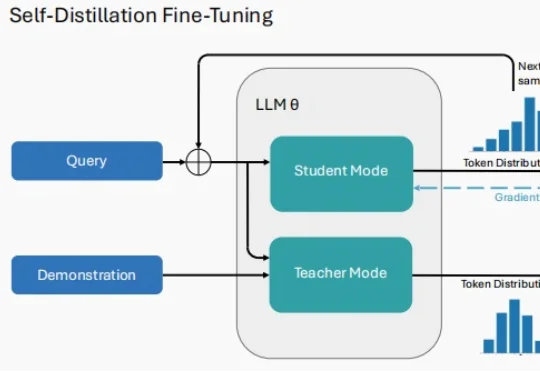
2026开年关键词:Self-Distillation,大模型真正走向「持续学习」
2026开年关键词:Self-Distillation,大模型真正走向「持续学习」2026 年刚拉开序幕,大模型(LLM)领域的研究者们似乎达成了一种默契。 当你翻开最近 arXiv 上最受关注的几篇论文,会发现一个高频出现的词汇:Self-Distillation。
来自主题: AI技术研报
7176 点击 2026-02-10 14:17
 搜索
搜索
2026 年刚拉开序幕,大模型(LLM)领域的研究者们似乎达成了一种默契。 当你翻开最近 arXiv 上最受关注的几篇论文,会发现一个高频出现的词汇:Self-Distillation。

今天凌晨,月之暗面核心团队在社交媒体平台Reddit上举行了一场有问必答(AMA)活动。三位联合创始人杨植麟(CEO)、周昕宇(算法团队负责人)和吴育昕与全球网友从0点聊到3点,把许多关键问题都给聊透了,比如Kimi K2.5是否蒸馏自Claude、Kimi K3将带来的提升与改变,以及如何在快速迭代与长期基础研究之间取得平衡。

什么样的思维链,能「教会」学生更好地推理?
随着大模型步入规模化应用深水区,日益高昂的推理成本与延迟已成为掣肘产业落地的核心瓶颈。在 “降本增效” 的行业共识下,从量化、剪枝到模型蒸馏,各类压缩技术竞相涌现,但往往难以兼顾性能损耗与通用性。

香港大学(The University of Hong Kong)与 Adobe Research 联合发布 Self-E(Self-Evaluating Model):一种无需预训练教师蒸馏、从零开始训练的任意步数文生图框架。其目标非常直接:让同一个模型在极少步数也能生成语义清晰、结构稳定的图像,同时在 50 步等常规设置下保持顶级质量,并且随着步数增加呈现单调提升。

2025年底,最令人印象深刻的AI圈大事莫过于Gemini 3 Flash的发布。

近日,Waymo 发布了一篇深度博客,详细介绍了该公司的 AI 战略以及以 Waymo 基础模型为核心的整体 AI 方法。

今年以来,开源项目LightX2V 及其 4 步视频生成蒸馏模型在 ComfyUI 社区迅速走红,单月下载量超过 170 万次。越来越多创作者用它在消费级显卡上完成高质量视频生成,把“等几分钟出一段视频”变成“边看边出片”。

前些天,一项「AI 传心术」的研究在技术圈炸开了锅:机器不用说话,直接抛过去一堆 Cache 就能交流。让人们直观感受到了「去语言化」的高效,也让机器之心那条相关推文狂揽 85 万浏览量。参阅报道《用「传心术」替代「对话」,清华大学联合无问芯穹、港中文等机构提出 Cache-to-Cache 模型通信新范式》。

目前,最先进的对齐方法是使用知识蒸馏(Knowledge Distillation, KD)在所有 token 上最小化 KL 散度。然而,最小化全局 KL 散度并不意味着 token 的接受率最大化。由于小模型容量受限,草稿模型往往难以完整吸收目标模型的知识,导致直接使用蒸馏方法的性能提升受限。在极限场景下,草稿模型和目标模型的巨大尺寸差异甚至可能导致训练不收敛。