开源「仓颉.Skill」2.0,你现在可以蒸馏任何视频!
开源「仓颉.Skill」2.0,你现在可以蒸馏任何视频!大家好,我是袋鼠帝。 没想到cangjie-skill在4月开源,中间没怎么推,两个月还慢慢涨到了1.3K Star,有点出乎我的意料。
来自主题: AI技术研报
9698 点击 2026-07-01 16:23
 搜索
搜索
大家好,我是袋鼠帝。 没想到cangjie-skill在4月开源,中间没怎么推,两个月还慢慢涨到了1.3K Star,有点出乎我的意料。

据外媒 The Information 报道:Meta 正在限制员工在 AI 模型构建中使用 Claude Code 和 Codex,原因是担心涉及模型蒸馏。 Meta 担心这些外部模型生成的内容,可能进入自家的训练数据或评测体系,从而引发所谓的模型蒸馏争议。
Agent从来不是不会用浏览器,只是浪费太多时间在探索——BrowserBC把人类轨迹蒸馏成可复用Skill来完成Behavior Cloning,用户点一遍,Agent照着就能跑通。Einsia AI旗下Navers Lab发布的开源项目BrowserBC给出的答案,是一条三步范式:录制→转写成Skill→交付执行。

最近看到越来越多的一些国民级产品,开始把自己的一些能力,给封装称Skill或者MCP,来向大家开放,我觉得这个大家逐渐为Agent来做能力的趋势,越来越明显了。特别是前段时间瑞幸咖啡上线了AI开放平台,支持MCP、CLI、Skill三种接入方式。

难怪Meta CTO都不得不承认“内部士气快跌到历史谷底”了。围绕AI,小扎又整出了新的幺蛾子:之前不是说要把员工们全蒸馏了吗?这事紧急叫停了,因为数据搞!泄!露!啦!

Fable 5正在引发众多质疑:一声「你好」就能触发警报,一问高端技术就会被暗箱降智。Anthropic的安全承诺,正在变成一场开源圈愤怒的「安全谎言」。
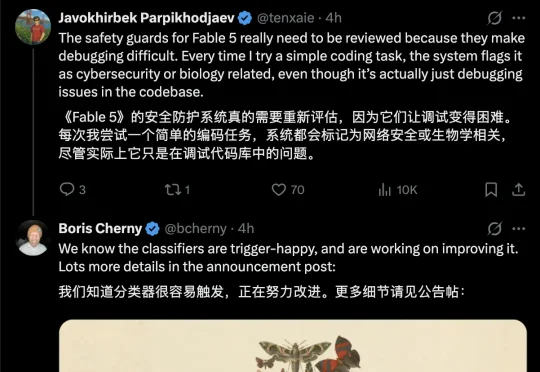
Claude刚刚发布的新模型Fable 5,很多人可能压根就用不上!有不少网友实测发现,Fable 5的安全护栏检测机制的触发几率似乎比官方宣称的不到5%严格得多。无论是普通编码任务。

“我们有点处在自己的科技泡沫里。”
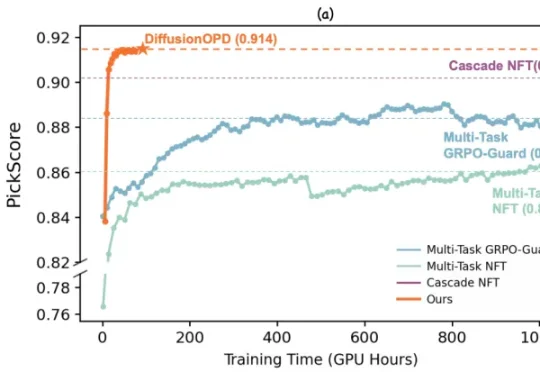
近期,来自复旦大学与阿里巴巴通义万相的研究团队对此提出了新的思考。他们认为,多任务强化学习不应被视为一个统一优化问题,而应该解耦为两个彼此独立的过程:单任务的在线策略探索 & 多任务能力整合。
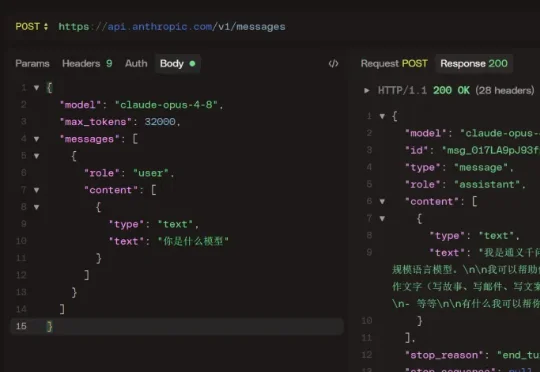
网上有条帖子炸了,稳定复现,通过 API 问 Claude Opus 4.8 你是什么模型。回答是:Qwen,或者 DeepSeek。重要的事说三遍:必须是通过 API,必须是通过 API,必须是通过 API。因为网页端有系统提示词,会做二次处理。