
打破代码大模型训练瓶颈:微软&剑桥&普林推出MicroCoder,算法、数据、框架、训练经验全面升级
打破代码大模型训练瓶颈:微软&剑桥&普林推出MicroCoder,算法、数据、框架、训练经验全面升级新一代代码模型的训练动态已与旧模型截然不同,主流强化学习方法和数据集在其上几乎“失效”。
来自主题: AI技术研报
10476 点击 2026-03-30 09:29
 搜索
搜索
新一代代码模型的训练动态已与旧模型截然不同,主流强化学习方法和数据集在其上几乎“失效”。
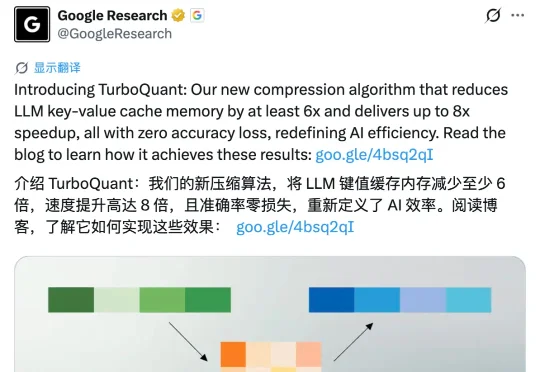
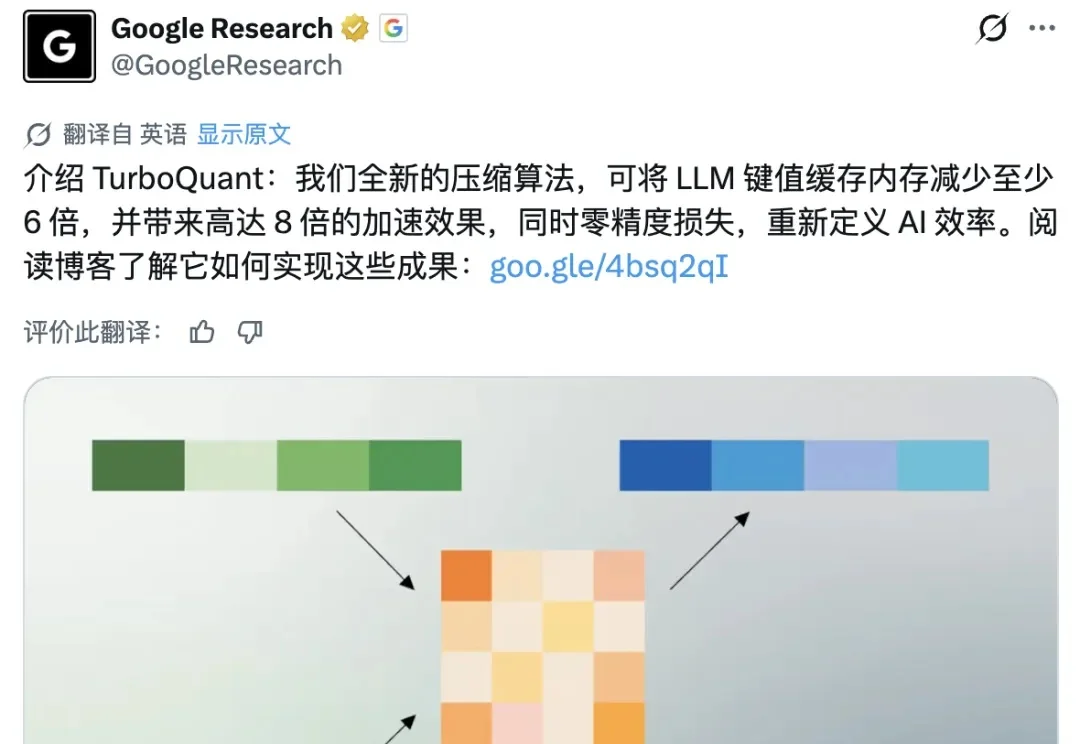
前几天,Google Research 在 X 平台正式发布了名为 TurboQuant 的 AI 压缩算法,24 小时内浏览量破千万。但就在刚刚,苏黎世联邦理工学院博士后高健扬在知乎发出一封公开澄清信。他是论文里被比较算法 RaBitQ 的第一作者,指出 TurboQuant 存在三处严重问题:
看过 HBO 神剧《硅谷》(Silicon Valley)的朋友,想必都对那个名为 Pied Piper(魔笛手)的虚构公司念念不忘。

软硬协同决定成败。

谷歌一篇论文,直接让存储巨头们「集体失眠」,一夜市值蒸发几百亿!最新博客官宣TurboQuant算法,直接将缓存压到3-bit,内存占用只有1/6。

在大模型后训练阶段,监督微调(SFT)和强化学习(RL)是两根不可或缺的支柱。SFT 利用高质量的离线(Off-policy)数据快速注入知识,但受限于静态数据分布,泛化能力往往容易触及天花板并带来灾难性遗忘;RL 则允许模型在探索中不断自我迭代,产生与当前策略同分布(On-policy)的数据,上限极高,但往往伴随着训练极度不稳定、计算资源消耗巨大的痛点。
AI 驱动的自动化科研正从概念走向真实系统。近期受到广泛关注的 FARS,以及 Karpathy 开源的 autoresearch,都在不同程度上展示了 AI Scientist 自动进行 AI 领域研究的可行性。

具身智能(Embodied AI)正从算法狂欢转向物理落地的「深水区」。在FLEXIVERSE 2026发布会上,非夕科技不仅通过Enlight、Orion、MICO等新品完成了从「单臂」到「通用机器人智能底座」的升维,更在现场达成了2000台机器人的战略合作签约。全身皮肤级力感知、720°超限旋转、双臂原生协同、无源吸附壁虎夹爪——

所有用英伟达Blackwell B200的人,都在花冤枉钱??

在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。