# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近期,阿里巴巴 ROLL 团队(淘天未来生活实验室与阿里巴巴智能引擎团队)联合上海交通大学、香港科技大学推出「3A」协同优化框架 ——Async 架构(Asynchronous Training)、Asymmetric PPO(AsyPPO)与 Attention 机制(Attention-based Reasoning Rhythm),「3A」彼此间并非孤立的技术堆砌,而是深度耦合,致力于共同推动「强化学习用于大语言模型(RL4LLM)」迈向高效、精细与可解释的新范式。
具体来看,ROLL Flash 以解耦为核心,通过「细粒度并行」与「采样 - 训练解耦」两大原则,将生成、环境交互、奖励计算与模型训练彻底流水线化,实现全链路异步执行,显著提升 GPU 利用率,同时通过「异步比」机制保障训练稳定性,集成主流 Off-policy 算法等,使得异步训练效果能与同步训练相媲美。
算法架构层面,AsyPPO 首次系统论证了评论家的参数规模与其价值估计能力并无必然关联,仅需两个小型评论家,即可在显著降低计算资源消耗的同时,提升推理性能与训练鲁棒性。
更进一步,团队创新性地对 Attention 进行重新定义 —— 它不仅是语言模型前向计算中的中间产物,更是揭示模型推理过程内在逻辑的「结构化蓝图」,并基于此设计了一种推理结构感知的动态奖励分配机制,使强化学习的优化目标与模型内生的推理节奏精准对齐,显著提升了训练效率与策略可解释性。
接下来详细了解一下「3A」协同优化框架是如何推动(RL4LLM)迈向新范式的。
文末有彩蛋,走过路过不要错过!ROCK & ROLL!
近年来,强化学习(RL)已成为提升大语言模型(LLM)在数学推理、代码生成、智能体(Agent)决策等复杂任务中能力的关键技术。然而,当前主流的同步 RL 训练系统在资源利用率和扩展性方面面临挑战。在处理长尾生成或等待外部环境(如代码编译器、游戏引擎)反馈时,GPU 资源常处于闲置状态,显著影响了模型迭代的效率。
为解决这一瓶颈,淘天未来生活实验室与阿里巴巴智能引擎团队联合推出了新一代高性能 RL 训练系统 ——ROLL Flash。它通过原生的异步设计,将传统的同步训练流水线重构为高效的「生产 - 消费」模式,旨在最大化资源利用率,加速大规模 RL 训练。
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
图 1: ROLL Flash 训练加速概览
传统的同步 RL 训练遵循一个严格的「生成 - 评估 - 学习」流程,要求批处理中的所有任务同步进行。在 LLM 的应用场景下,响应长度呈现明显的「长尾分布」,最长响应的生成时间可能是中位数的 20 倍以上。这种模式的局限性愈发凸显:
这些问题共同导致了 GPU 利用率的显著下降,使得大规模、长序列的 RL 训练成本高昂且耗时。
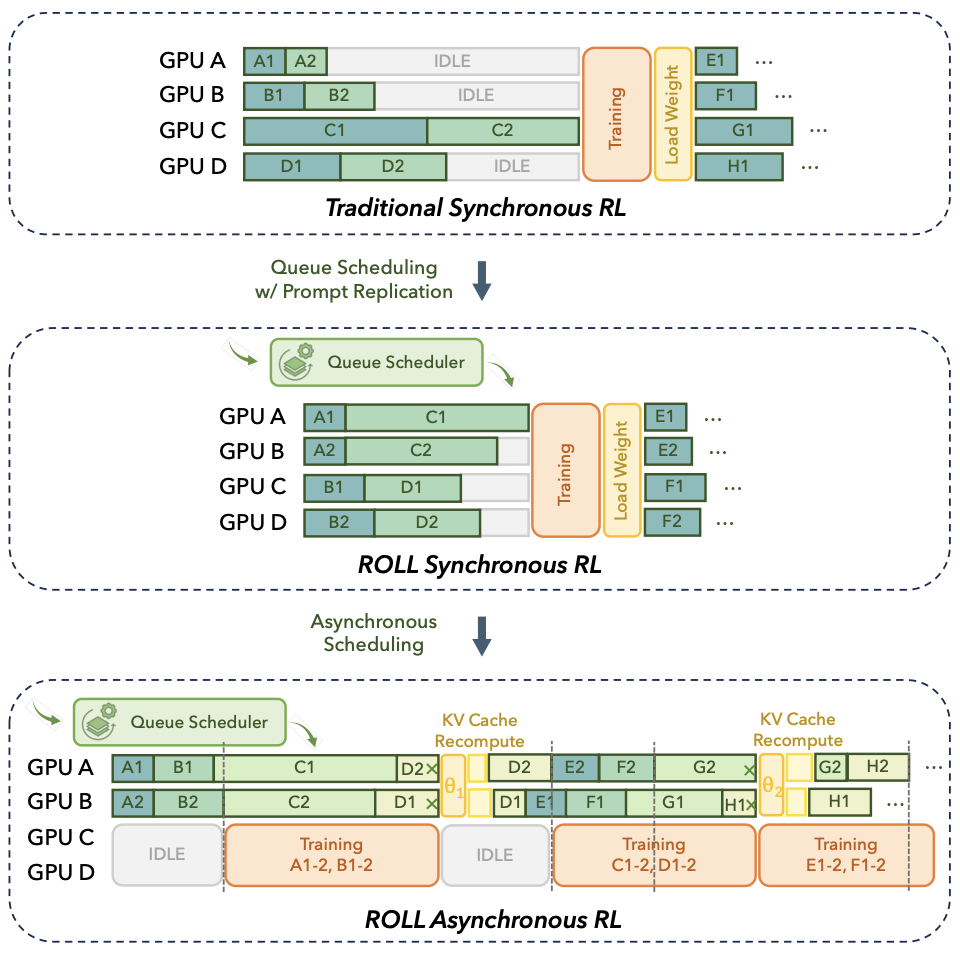
ROLL Flash 的核心思想是解耦。基于两大设计原则 —— 细粒度并行(Fine-grained Parallelism)与采样 - 训练解耦(Rollout–Train Decoupling),它将原本紧密耦合的各个环节分解,实现了生成、环境交互、奖励计算与模型训练的全流水线并行。
通过该设计,当一部分计算资源因等待环境而阻塞时,系统的其他部分能够无缝处理其他轨迹的生成或执行模型参数的更新,从而最大化 GPU 的利用率。
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
图 2: ROLL 同步与异步框架概览。ROLL Flash 引入了队列调度、候选生成并行化和异步架构,显著优于传统同步训练。
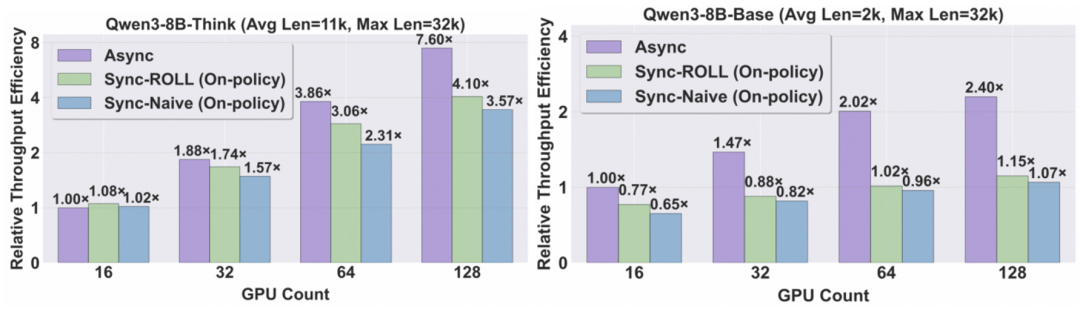
ROLL Flash 在多个主流 RL 任务上取得了显著的性能提升,并在百卡规模下展示了近乎线性的扩展能力。
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
图 3: 不同架构下吞吐量随 GPU 数量的扩展表现。上图为长序列场景(Qwen3-8B-Think 模型),下图为短序列场景(Qwen3-8B-Base 模型)。
ROLL Flash 的高性能源于其系统层面的四项关键技术,以及为保证异步训练稳定性而引入的创新机制。
1. 队列调度(Queue Scheduling)
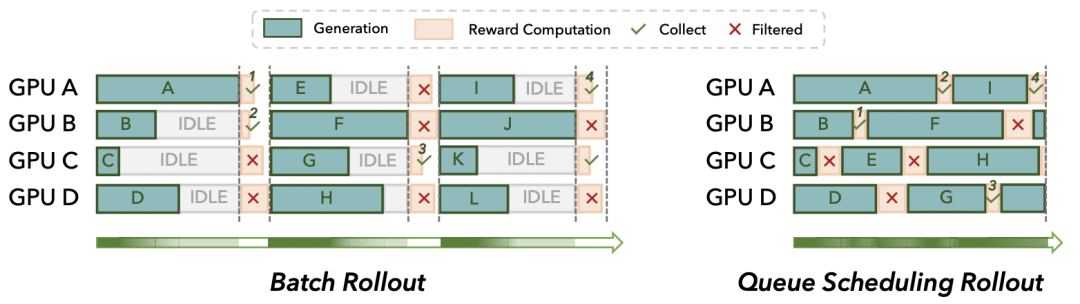
为每个独立的采样任务(Prompt)建立专属队列。任务完成后,其占用的 GPU 资源立即被释放并分配给新任务,从而消除批处理中的「长尾」效应。该设计在需要动态过滤样本的场景下,能极大加速高质量样本的收集效率。
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
图 4: 批处理模式(上)因长尾效应和同步点导致 GPU 空闲,而队列调度模式(下)通过流水线化执行,实现了更高的资源利用率。
实验证明,队列调度在不同批大小配置下均能稳定减少生成时间,在 128 * 8 的配置下,带来了 2.5 倍的加速。
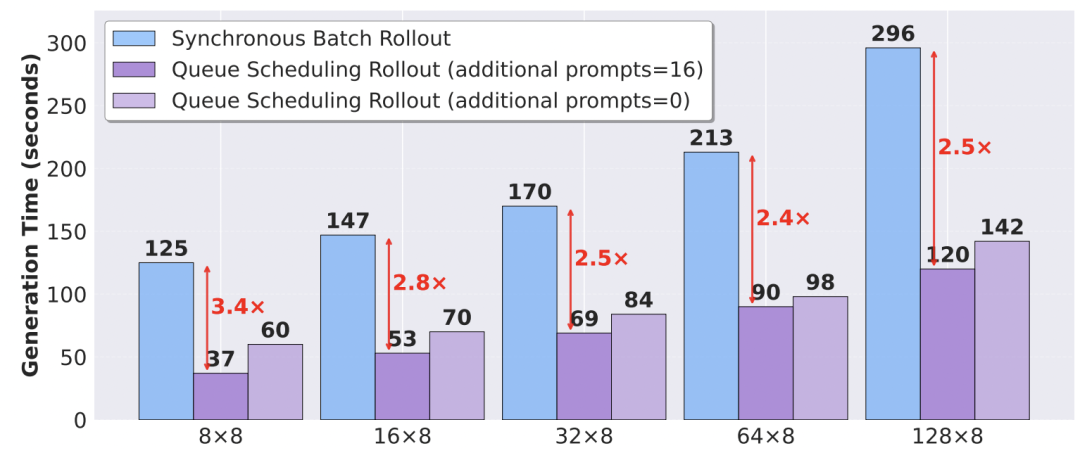 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
图 5: 队列调度在不同配置下的加速效果。
2. 候选生成并行化(Prompt Replication)
对于需要为单个 Prompt 生成多个候选答案的场景,系统会将其拆分为多个独立的、生成单个答案的任务,并分散至不同 GPU 并行执行。这种「一对多」到「多对一」的转换为缓解长尾延迟提供了有效途径。实验表明,该技术在多候选生成的场景下,最高可带来 1.95 倍的性能提升。
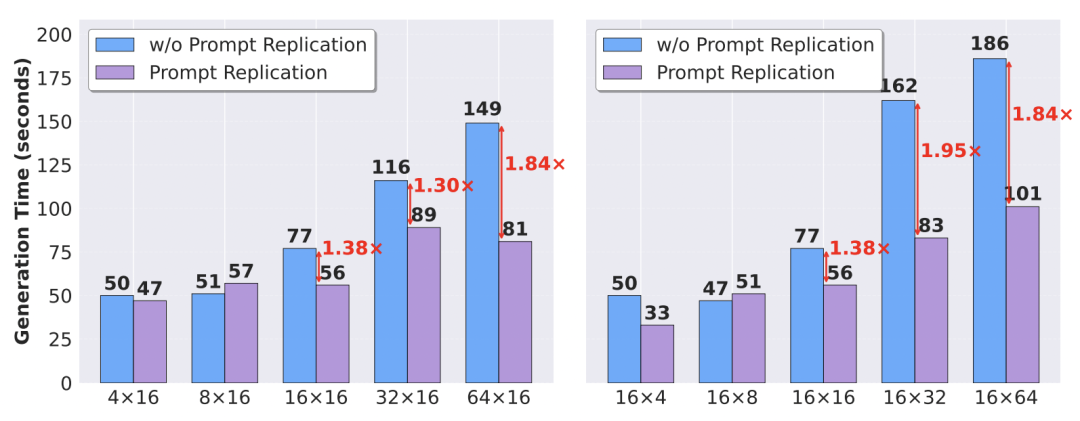 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
图 6: 候选生成并行化在不同配置下的加速效果。
3. 环境交互异步化(Environment-Level Async Rollout)
在智能体与环境交互期间,GPU 资源被立即释放用于处理其他轨迹的计算任务,实现计算与 I/O 等待的重叠。在环境交互延迟波动较大的 Agentic 任务中,该设计能带来显著的性能提升。在 ALFWorld 真实环境上的测试显示,该技术带来了 1.58 倍的加速。
4. 冗余环境部署(Redundant Environment Rollout)
通过部署冗余的环境实例组,有效应对环境中偶然出现的慢响应或无响应(fail-slow/fail-stop)问题,提升训练过程的鲁棒性。实验证明,在真实 Agentic 环境(如 SWE-bench 和 ALFWorld)中,该技术能在异步化的基础上带来额外的 7%-16% 的吞吐提升。
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
图 7: 在真实 Agentic 环境(SWE-bench, ALFWorld)中,环境交互异步化和冗余环境部署均带来了显著的端到端训练时间缩减。
异步训练虽然高效,但也可能因「样本陈旧性」(Stale Samples)问题影响模型收敛。ROLL Flash 通过两大设计确保了性能与稳定性的双赢。
异步比(Asynchronous Ratio)
团队引入了 异步比 (Asynchronous Ratio, ) 参数,它定义了训练所用样本与当前最新模型版本之间的最大可容忍差距。通过此参数,可以在样本新鲜度与资源利用率之间进行权衡。实验表明,在多数场景下,一个较小的异步比(如 2)就足以获得接近完整的性能提升,同时避免了严重的样本陈旧问题。
兼容主流 Off-policy 算法
为解决样本陈旧性带来的潜在性能损失,ROLL Flash 集成了多种主流的 Off-policy RL 算法(如 Decoupled PPO, TOPR, TIS, CISPO)。实验证明,这些算法甚至是基础的 GRPO 能有效补偿异步训练带来的影响,使得最终模型性能与同步训练相媲美。
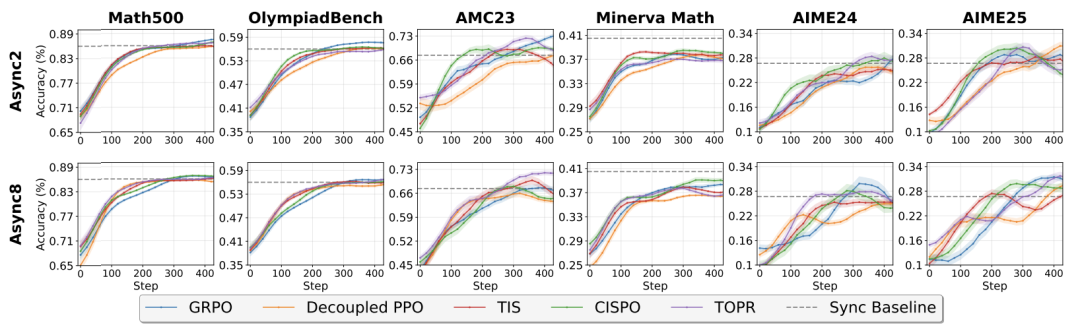 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
图 8: 在异步比为 2 和 8 的设置下,多种 Off-policy 算法的性能与同步训练(Sync)基线相当,证明了异步训练的稳定性和有效性。
ROLL Flash 不仅是一个系统层面的优化,更推动了大规模 RL 训练范式的演进。它将 RL 训练从传统的、步调一致的同步模式,转变为一个持续进行数据生产与模型消费的异步模式。
这意味着:
对于致力于提升模型数学推理、代码生成能力,或构建与真实世界交互的 LLM 智能体的研究者和工程师而言,ROLL Flash 提供了一个更高效、稳定和经济的训练解决方案。
在大语言模型(LLM)与强化学习(RL)深度融合的浪潮中,无 critic 的 RLVR 范式已成为主流的后训练算法。
然而,一个长期被忽视的问题是:是否真的需要一个与策略模型规模相当的 “巨型评论家”(critic)?是否可以实现 critic 的轻量化,重新激发 PPO 的部署潜力?
阿里巴巴 ROLL 团队、香港科技大学和 Mila 的最新研究给出了否定答案。论文《Asymmetric Proximal Policy Optimization: Mini-Critics Boost LLM Reasoning》中提出 AsyPPO—— 一种面向 LLM 的轻量化、高稳定 PPO 变体,首次系统性揭示了评论家的参数规模与其价值估计能力并无必然关联,并由此解锁了更高效、更经济的 RL4LLM 训练新路径。
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
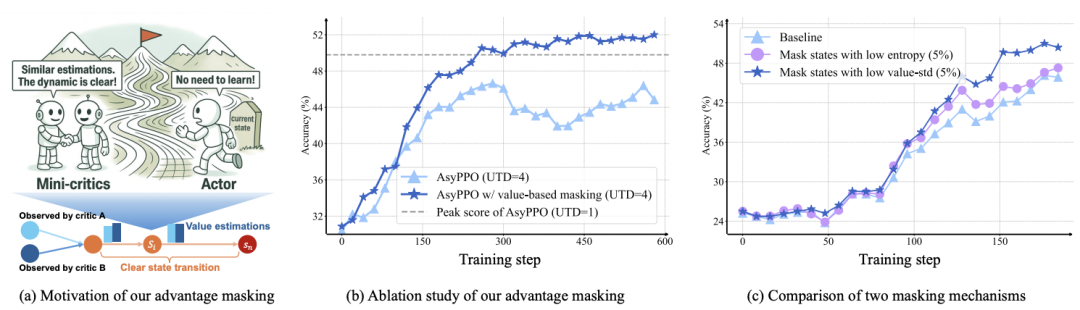
1.Critic 是策略训练稳定性的天然「压舱石」
在 LLM 的 PPO 训练中,优势函数(advantage)的估计偏差极易引发训练崩溃。研究发现,一个结构合理、训练充分的 critic 能通过逐状态(state-wise)显著提升训练鲁棒性。
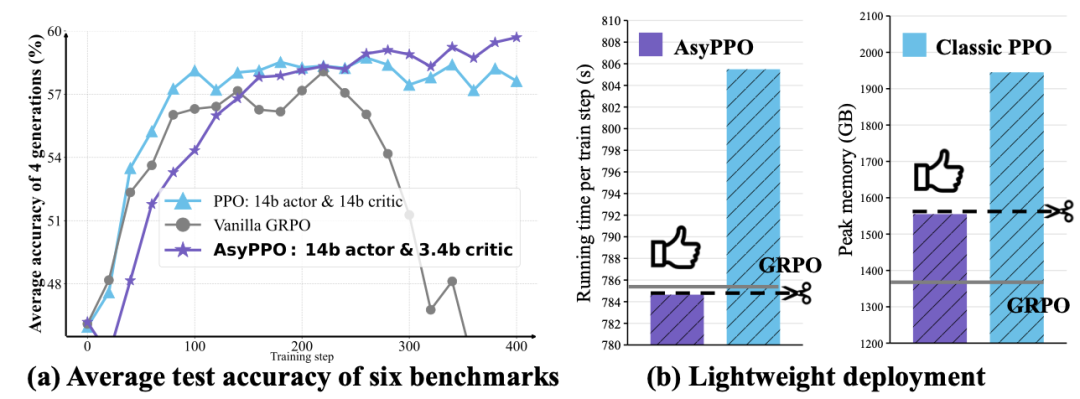 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
2.「小而美」的评论家同样可靠
实验表明,仅需两个轻量级评论家(参数量远小于策略模型),即可实现与巨型 critic 相当甚至更优的价值估计性能。这意味着 RL 后训练不再需要为 critic 配置昂贵的专用计算资源。
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
3. Critic 不仅评估,更能引导策略优化
评论家之间的一致性与分歧性蕴含丰富信号 —— 可被用于动态重构策略损失,实现「智能」的探索与利用平衡。
基于上述洞察,AsyPPO 引入两项关键技术:
创新点一:多样化微型评论家聚合
通过非重叠的提示级数据划分(prompt-level data partitioning),训练多个轻量 critic。仅需两个 critic 即可有效校正优势估计偏差,计算开销极低,却显著提升训练稳定性。
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
创新点二:不确定性感知的策略损失重构
动态分析多个 critic 对同一状态的价值估计:
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
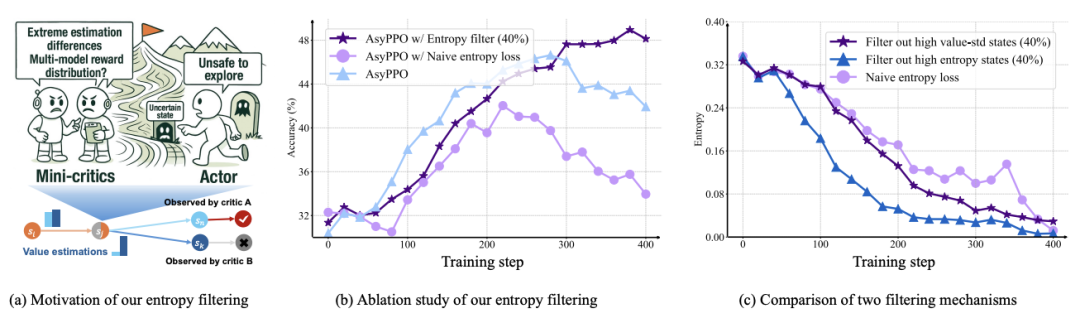 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
AsyPPO 不仅在算法层面实现突破,更带来显著工程价值:
AsyPPO 的提出具有广泛的社区价值与长远意义:
这项工作为 critic-based RL 算法在 LLM 后训练中的规模化应用扫清了关键障碍,证明了「小模型也能驱动大智能」,也为构建高效、稳定、普惠的大模型强化学习生态迈出了重要一步。
大型语言模型在复杂推理任务上取得了显著成功,但其内部推理机制仍是一个黑箱。当前强化学习方法通常对整个生成序列应用统一的信用分配,模糊了关键步骤与常规步骤之间的区别。这种不匹配限制了数据效率、可解释性以及在挑战性推理任务上的性能提升。
本文探索一个重要问题:「通过更深入地把握模型内部的推理模式(例如识别其何时进行思考、何时检索信息、何处构成关键决策节点),能否更有效地实现对模型推理能力的强化?」
本研究通过注意力动力学这一独特视角,揭示了 LLM 内部固有的推理节奏,为更透明、有效的优化提供了可能。
阿里巴巴 ROLL 团队与上海交通大学联合发表论文,探索了基于注意力机制的模型内部机理分析,并将 RL 过程对齐模型内在机制以实现效率和性能的提升:
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
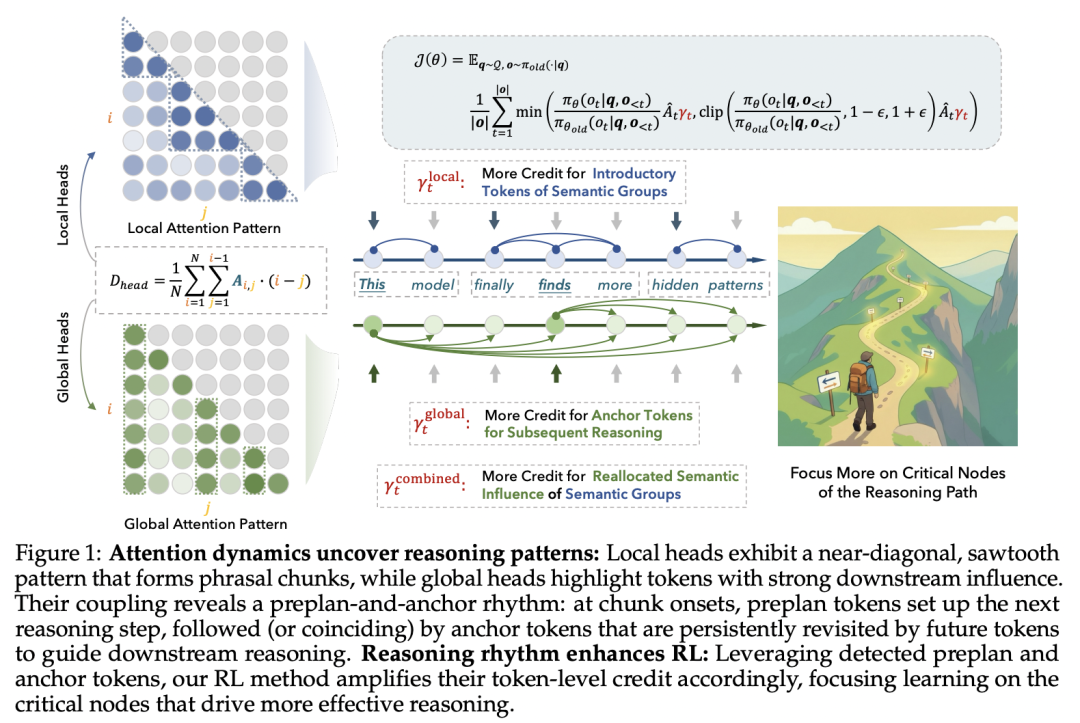
研究团队从两个互补视角分析注意力机制:局部(向后)视角衡量 token 对邻近上下文与远程上下文的依赖程度,全局(向前)视角衡量 token 对后续 token 的下游影响。
通过对 Qwen3-4B-Base 模型在 GSM8K 数据集上的分析,研究者根据注意力头的平均注意力跨度将其分类为局部关注 Map 和全局关注 Map。
局部关注型聚合注意力图展现出沿对角线的锯齿状模式,跟踪短语或语义块。在语义块内部(如习惯性表达「by the way」),注意力保持高度局部化;而在新块开始时,注意力突然回溯到更早的上下文。全局关注型聚合注意力图则突出显示具有广泛下游影响的稀疏锚定 token,这些 token 被许多后续位置反复访问,充当语义枢纽。
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
基于上述观察,研究团队设计了两个关键指标:
1.Windowed Average Attention Distance (WAAD):
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
该指标衡量在裁剪窗口内 token 回溯的距离,强调模型是否必须超越直接邻居来解决歧义。低 WAAD 值表示块内的紧密局部延续(谷值),而峰值表示在块边界处的长距离回溯。
2.Future Attention Influence (FAI):
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
该指标通过平均 token 从未来位置接收的注意力来量化其全局重要性。高 FAI token 通常对应关键逻辑路点,如关键定义、中间结果或决策点。
通过联合分析 WAAD 和 FAI 的动态模式,研究团队发现了一个一致的双拍节奏:
这种耦合模式通过三个实证耦合得到验证:WAAD 峰值保持更高的 token 熵;接收头和全局关注头识别出共享的锚定;FAI 峰值跟随或与 WAAD 峰值重合。
定量分析显示,这些耦合相对于随机机会都有显著提升(+42.47% 到 + 171.49%)。
最终,从分析中可以得到如下机理:
基于上述发现,研究团队设计了三种针对关键推理节点的强化学习信用分配策略:
Attention Map 的获取:在 RL 框架中获取 Attention Map 的关键在于绕过默认推理 / 训练引擎(如 vLLM 和 Megatron)对完整注意力矩阵的丢弃机制。由于这些系统为节省显存通常使用 Flash Attention 并丢弃中间注意力权重,作者引入了一个专用的辅助模型 actor_attn(基于标准 Transformer 实现),在每次由 actor_infer 生成完整响应后,将原始 prompt 与生成的 response 拼接成完整序列,并在此辅助模型上执行一次额外的前向传播。
在此过程中,从网络中间三分之一区域(如第⌊L/3⌋到⌊2L/3⌋层)均匀采样若干层的完整注意力图,作为模型推理节律的代表性快照。该操作仅增加一次前向计算开销,且在 actor_train 每次策略更新后同步其权重至 actor_attn,确保注意力分析与当前策略一致。
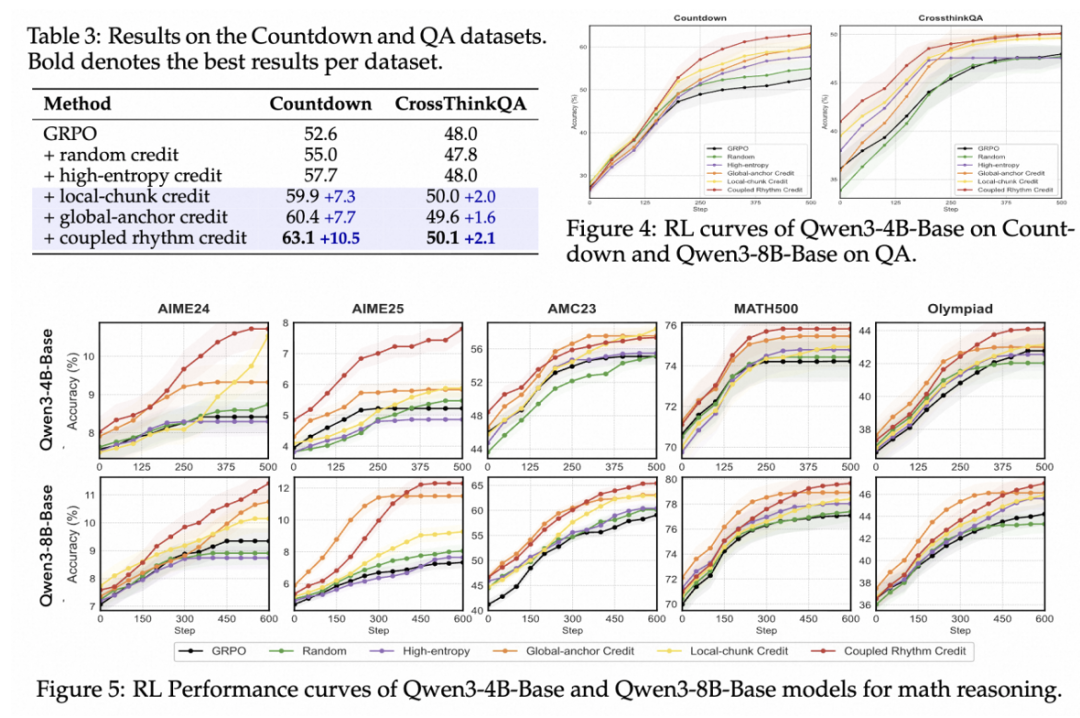
研究团队在多个推理任务上评估了所提方法的有效性:
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
在 Countdown 任务上,耦合节奏信用策略达到 63.1%,显著优于 GRPO 基线 (52.6%)。局部块和全局锚定信用方案也带来一致提升,而随机或基于熵的 token 选择提供边际或无改进。在 CrossThink-QA 上,所有信用感知变体都显示出一致改进,最佳变体耦合节奏信用达到 50.1%。
在数学推理基准上,所提方法在所有设置下都一致优于 GRPO 基线和简单替代方案。值得注意的是,耦合节奏信用在最具挑战性的任务上取得了最强增益,如 Qwen3-8B 在 AIME25 上提升 + 5.0 个百分点,在 AMC23 上提升 + 6.3 个百分点。这些增益在不同序列长度下都很稳健:在扩展的 8K 上下文中,耦合节奏信用仍然提供一致改进。
注意力内在信号的指引可将 LLM 的强化学习从「盲目试错」推向「结构引导」,使大家能够:
接下来,团队将探索模型内在注意力信号在多智能体协作、工具调用、自我反思等高级推理场景中的应用,并开源相关工具链,助力社区构建透明、高效、结构化的下一代 LLM 训练范式。
你是否也有这些痛苦经历?
那么,你一定不能错过阿里巴巴最新开源的 ROCK(Reinforcement Open Construction Kit),将为你提供:
有了 ROCK,让你:
晚上启动 Agentic RL 训练任务后:安心盖上电脑,美美地睡个好觉,不用半夜爬起来检查进程(告别熊猫眼), 甚至可以关掉钉钉通知(老板:?)
第二天早晨醒来:
从此告别:
 算法->机理,推动RL4LLM全栈协同优化">
算法->机理,推动RL4LLM全栈协同优化">
未来,ROLL 团队将继续深耕 RL for LLM 的系统与算法协同创新,致力于打造易用、高效、可扩展的开源生态,为社区提供坚实的基础设施。
团队相信,通过解决工程与系统层面的瓶颈,将极大释放算法的创新潜力。欢迎每一位对 LLM 与 RL 充满热情的开发者 Star、试用开源项目,并贡献代码,与大家一起,推动 LLM 强化学习走向更广阔的实用化与规模化未来!
文章来自于“机器之心”,作者 “机器之心编辑部”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
