刚刚,谷歌AI破解外星人难题!打破十年纪录,自己写算法震撼诺奖得主
刚刚,谷歌AI破解外星人难题!打破十年纪录,自己写算法震撼诺奖得主谷歌DeepMind又放大招了:AlphaEvolve自主写算法,一口气改写5个经典拉姆齐数下界,打破了尘封十年的数学纪录!诺奖得主Hassabis和图灵奖得主LeCun都纷纷点赞——AI,正在彻底改变数学突破的方式!
来自主题: AI资讯
8719 点击 2026-03-14 20:41
 搜索
搜索
谷歌DeepMind又放大招了:AlphaEvolve自主写算法,一口气改写5个经典拉姆齐数下界,打破了尘封十年的数学纪录!诺奖得主Hassabis和图灵奖得主LeCun都纷纷点赞——AI,正在彻底改变数学突破的方式!

AI 时代,最贵的护城河不是算法,而是安全。

让AI像Kaggle顶尖选手一样设计算法,需要几步?
来自马里兰大学、圣路易斯华盛顿大学、北卡罗来纳大学教堂山分校等机构的研究团队提出了 Parallel-Probe。不同于直接从算法设计出发,该研究首先通过引入 2D Probing,对 online 并行推理过程中的全局动态性进行了系统性刻画。

是不是经常纠结于 VLA(视觉 - 语言 - 动作)模型的训练技巧?面对层出不穷的 VLA 算法,是不是常常感到眼花缭乱,不知道哪种数据模态、训练策略最有效? 别急,丰田研究院(TRI)和清华大学刚刚

近日,深度学习领域重要底层优化技术 FlashAttention 迎来大版本更新。FlashAttention 核心作者、普林斯顿大学助理教授 Tri Dao 表示,在 Blackwell GPU 上,即使瓶颈截然不同,注意力机制的执行速度现在也几乎与矩阵乘法一样快了!

就在刚刚,Claude独立攻克了图论猜想,写《计算机程序设计艺术》的计算机泰斗高德纳彻底震惊了!这一次,AI在自动推理和解决创造性问题上,又达到了全新的里程碑。
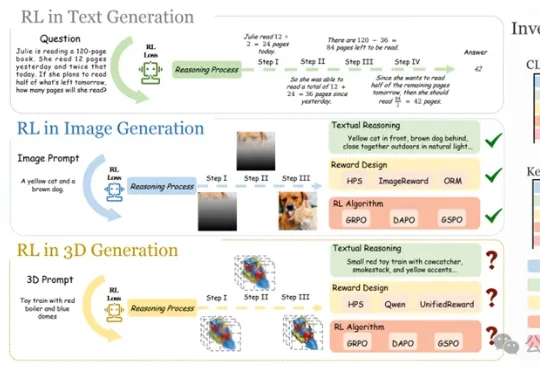
当GRPO让大模型在数学、代码推理上实现质变,研究团队率先给出答案——首个将强化学习系统性引入文本到3D自回归生成的研究正式诞生,并被CVPR 2026接收。该研究不只是简单移植2D经验,而是针对3D生成的独特挑战,从奖励设计、算法选择、评测基准到训练范式,做了一套完整的系统性探索。
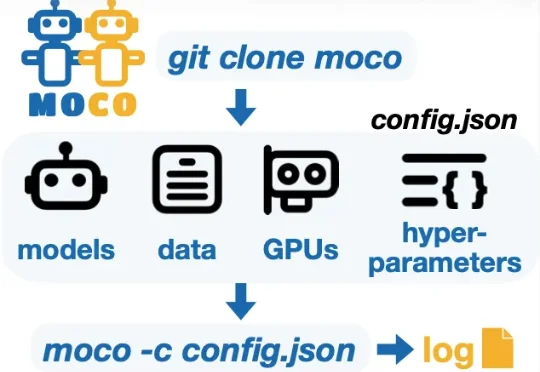
为了支持多模型协同研究并加速这一未来愿景的实现,华盛顿大学 (University of Washington) 冯尚彬团队联合斯坦福大学、哈佛大学等研究人员提出 MoCo—— 一个针对多模型协同研究的 Python 框架。MoCo 支持 26 种在不同层级实现多模型交互的算法,研究者可以灵活自定义数据集、模型以及硬件配置,比较不同算法,优化自身算法,以此构建组合式人工智能系统。MoCo 为设计、

在经济学和博弈论的世界里,找到「纳什均衡」往往意味着找到了复杂局势下的最优解。多所顶尖高校的研究人员开发出了一位名为PrimeNash的「AI数学家」,不仅能像人类专家一样推导公式,还能解决许多连传统算法都束手无策的复杂博弈难题,成果已发表在Cell Press旗下的交叉学科期刊Nexus上。