
炸裂!DeepMind 发布 Lyria 2 音乐生成模型!
炸裂!DeepMind 发布 Lyria 2 音乐生成模型!Google DeepMind正式发布其最新的音乐生成模型Lyria2,标志着音乐创作领域人工智能又一重大突破。该新模型具备高保真音频生成和专业音质,为音乐家、制作人和创作者提供了更强大的工具。
来自主题: AI资讯
10526 点击 2025-04-27 09:16
 搜索
搜索
Google DeepMind正式发布其最新的音乐生成模型Lyria2,标志着音乐创作领域人工智能又一重大突破。该新模型具备高保真音频生成和专业音质,为音乐家、制作人和创作者提供了更强大的工具。
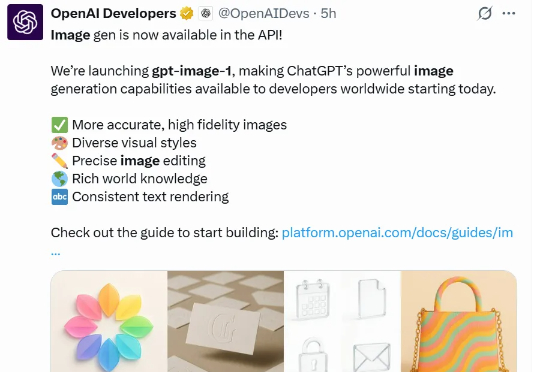
上个月,OpenAI 在 ChatGPT 中引入了图像生成功能,广受欢迎:仅在第一周,全球就有超过 1.3 亿用户创建了超过 7 亿张图片。就在刚刚,OpenAI 又宣布了一个好消息:他们正式在 API 中推出驱动 ChatGPT 多模态体验的原生模型 ——gpt-image-1,让开发者和企业能够轻松将高质量、专业级的图像生成功能直接集成到自己的工具和平台中。
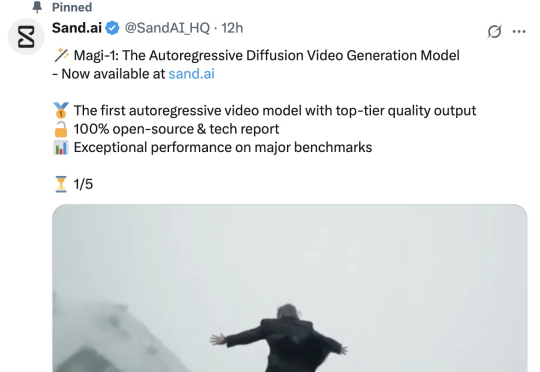
新国产AI视频生成模型横空出世,一夜间全网刷屏。Magi-1,首个实现顶级画质输出的自回归视频生成模型,模型权重、代码100%开源。整整61页的技术报告中还详细介绍了创新的注意力改进和推理基础设施设计,给人一种视频版DeepSeek的感觉。

可以生成无限时长的视频生成模型终于来了!

基于Transformer的自回归架构在语言建模上取得了显著成功,但在图像生成领域,扩散模型凭借强大的生成质量和可控性占据了主导地位。
“史上最强视觉生成模型”,现在属于快手。一基双子的可灵AI基础模型——文/图生图的可图、文/图生视频的可灵,都重磅升级到2.0版本。可图2.0,对比MidJourney 7.0,胜负比「(good+same) / (same+bad)」超300%,对比FLUX超过150%;

自数字人技术Omnihuman-1引起行业关注之后,字节智能创作团队再放大招。全新DreamActor-M1横空出世,一张照片一段视频,就能生成电影级视频,精准迁移表情动作,还支持多种画风。

本篇论文是由南洋理工大学 S-Lab 与普渡大学提出的无分类引导新范式,支持所有 Flow Matching 的生成模型。目前已被集成至 Diffusers 与 ComfyUI。
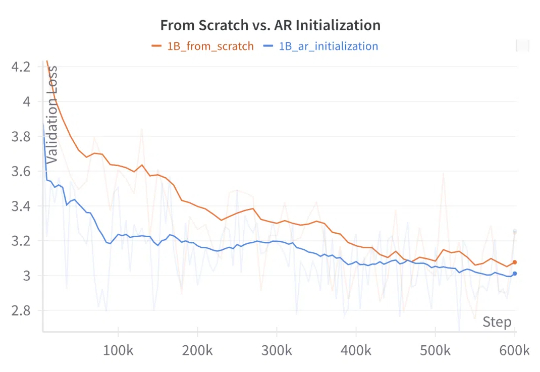
语言是离散的,所以适合用自回归模型来生成;而图像是连续的,所以适合用扩散模型来生成。在生成模型发展早期,这种刻板印象广泛存在于很多研究者的脑海中。
Runway带着新一代视频生成模型Gen-4杀回来了!