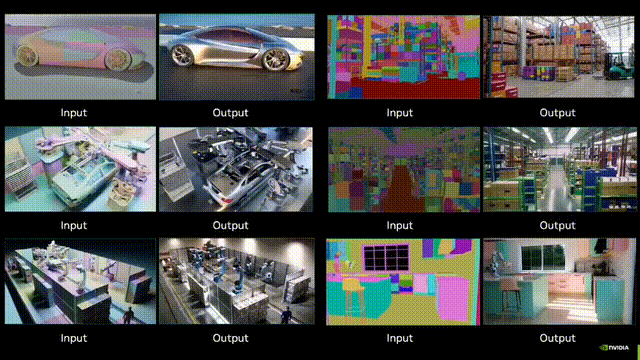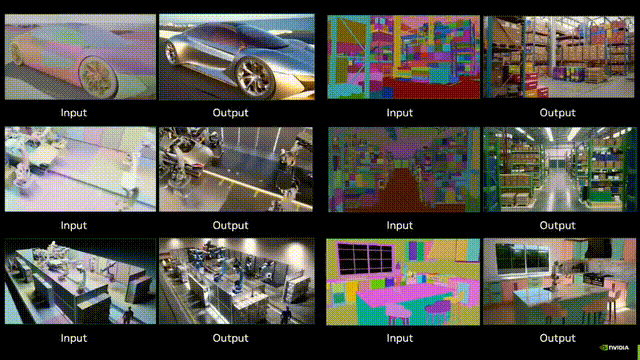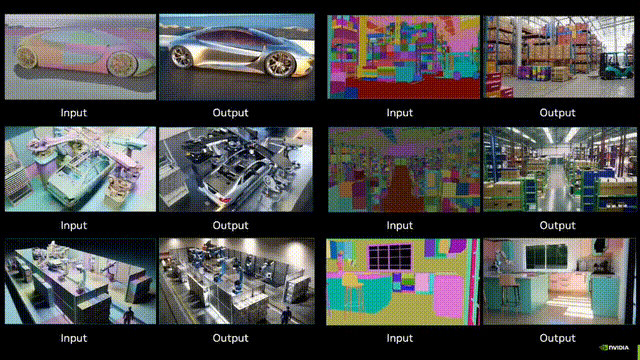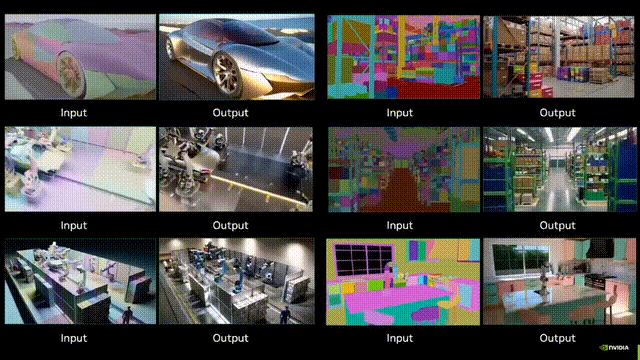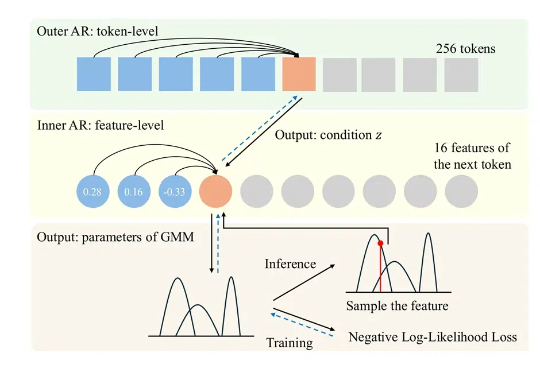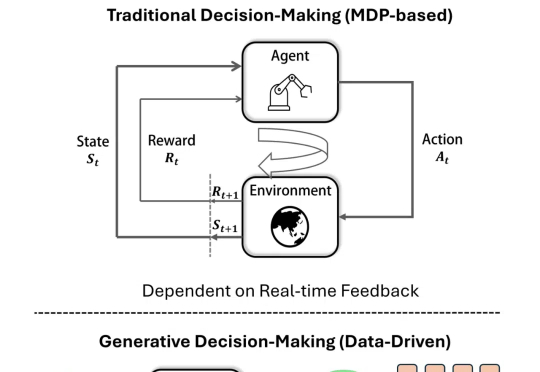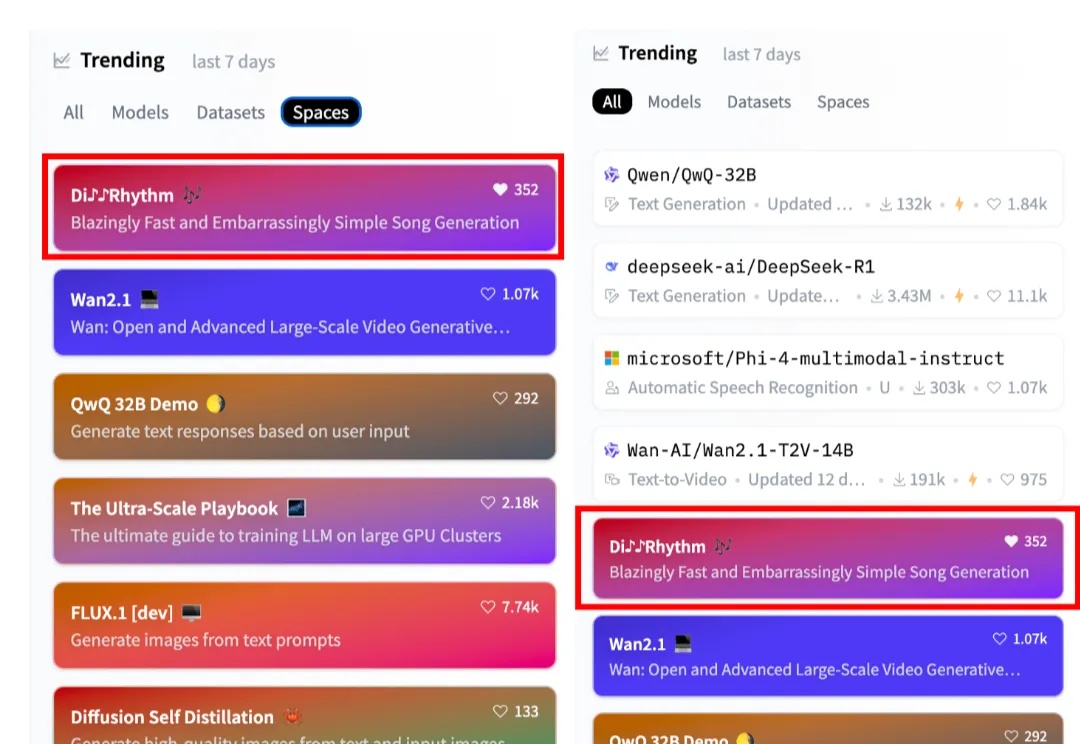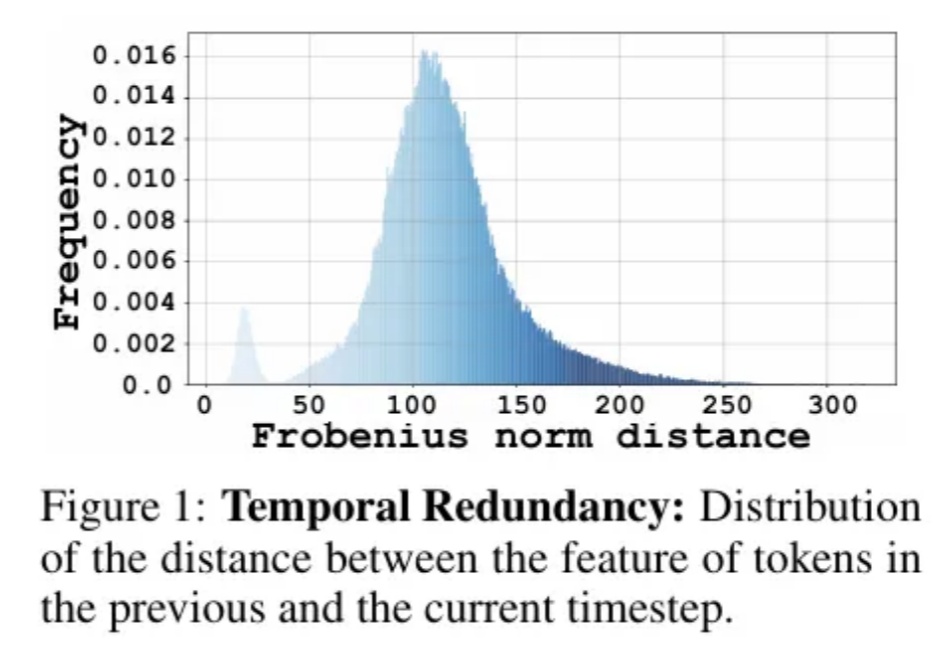
Adobe黑科技:视频扩散降维图像编辑,ObjectMover秒懂物理规律
Adobe黑科技:视频扩散降维图像编辑,ObjectMover秒懂物理规律论文第一作者为余鑫,香港大学三年级博士生,通讯作者为香港大学齐晓娟教授。主要研究方向为生成模型及其在图像和 3D 中的应用,发表计算机视觉和图形学顶级会议期刊论文数十篇,论文数次获得 Oral, Spotlight 和 Best Paper Honorable Mention 等荣誉。此项研究工作为作者于 Adobe Research 的实习期间完成。
来自主题: AI技术研报
10231 点击 2025-03-30 10:46