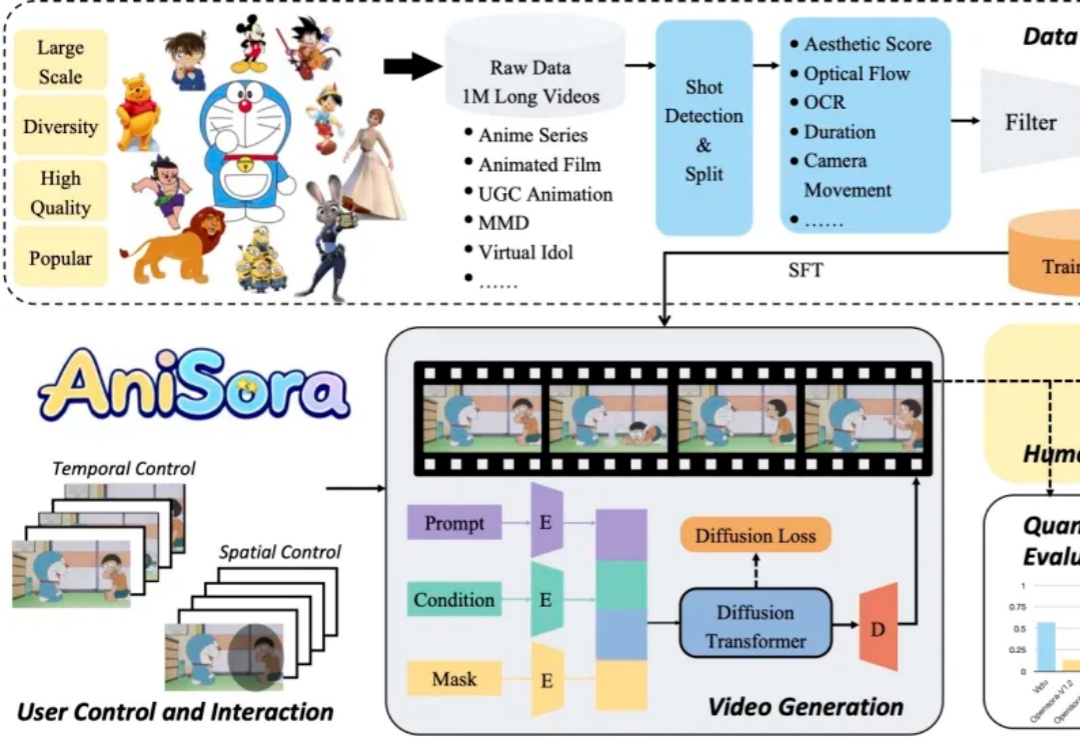
Index-AniSora:B站开源动画生成模型,斩获多项SOTA入选IJCAI25
Index-AniSora:B站开源动画生成模型,斩获多项SOTA入选IJCAI25B 站开源动画视频生成模型 Index-AniSora,支持番剧、国创、漫改动画、VTuber、动画 PV、鬼畜动画等多种二次元风格视频镜头一键生成!
来自主题: AI技术研报
9280 点击 2025-05-19 16:46
 搜索
搜索
B 站开源动画视频生成模型 Index-AniSora,支持番剧、国创、漫改动画、VTuber、动画 PV、鬼畜动画等多种二次元风格视频镜头一键生成!
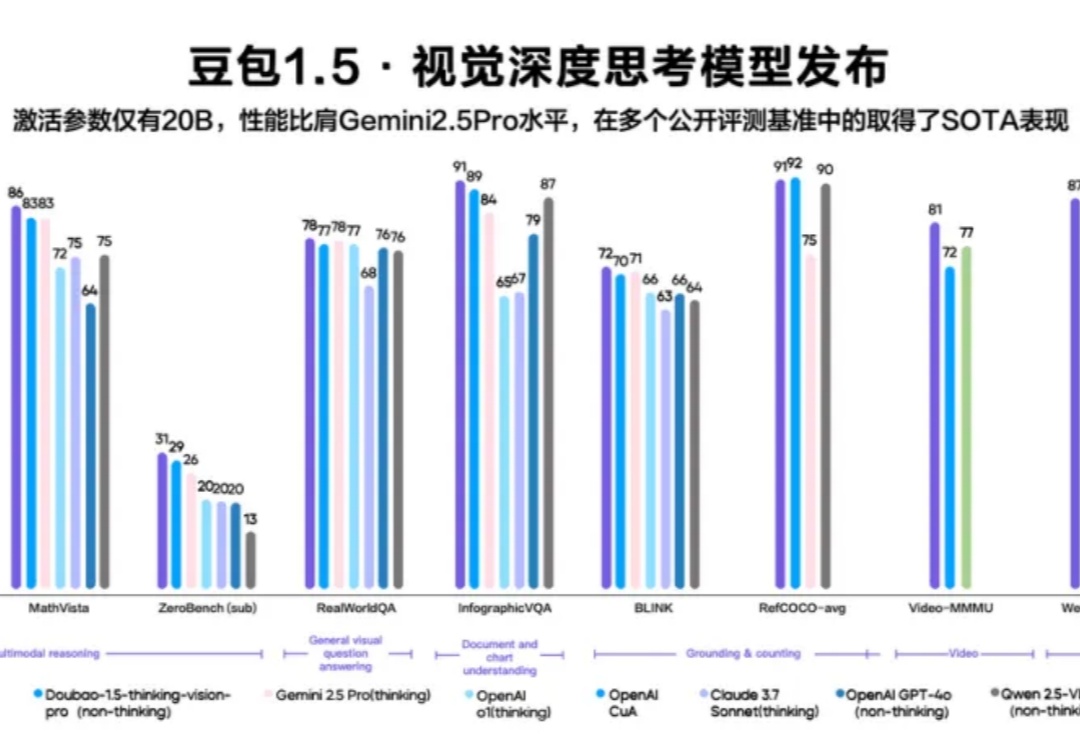
5月13日,在 FORCE LINK AI 创新巡展·上海站,火山引擎发布豆包·视频生成模型 Seedance 1.0 lite、豆包1.5·视觉深度思考模型,升级豆包·音乐模型。同时,Data Agent 正式亮相、Trae 接入豆包深度思考模型并全新升级。火山引擎正在以更强大的模型矩阵、更丰富的智能体工具,帮助企业打通从业务到智能体的应用链路。

近年来,生成式人工智能(Generative AI)技术的突破性进展,特别是文本到图像 T2I 生成模型的快速发展,已经使 AI 系统能够根据用户输入的文本提示(prompt)生成高度逼真的图像。从早期的 DALL・E 到 Stable Diffusion、Midjourney 等模型,这一领域的技术迭代呈现出加速发展的态势。
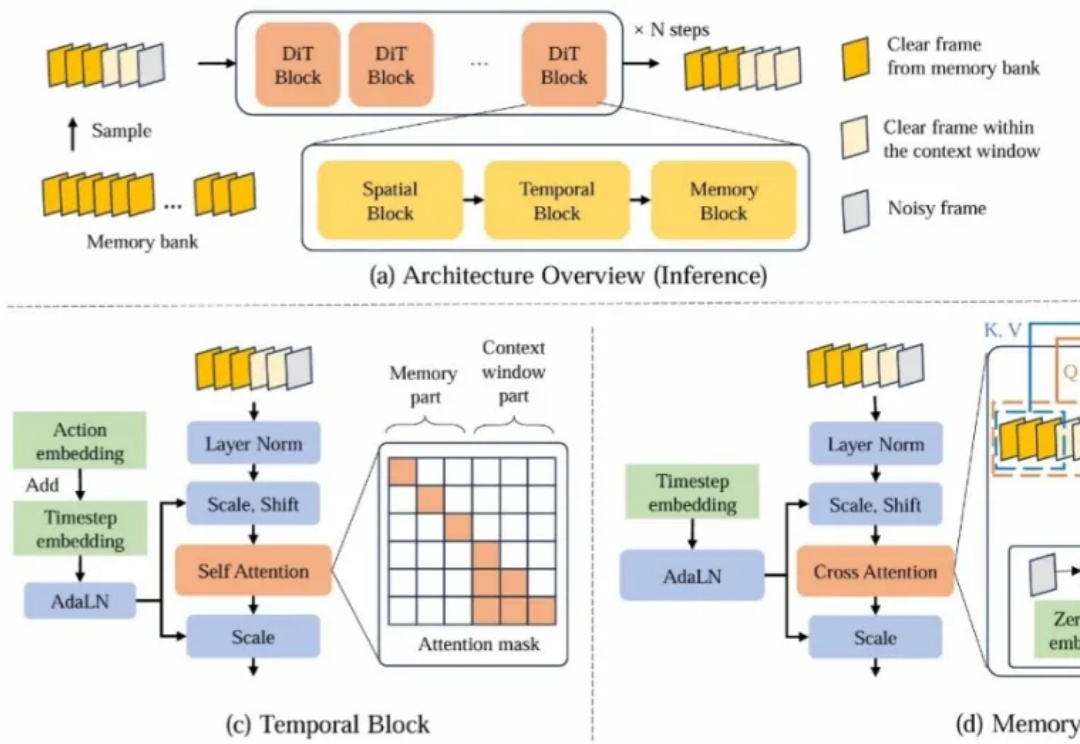
近年来,基于视频生成模型的可交互世界生成引发了广泛关注。尽管现有方法在生成质量和交互能力上取得了显著进展,但由于上下文时间窗口受限,生成的世界在长时序下严重缺乏一致性。

Sora、可灵等视频生成模型令人惊艳的性能表现使得创作者仅依靠文本输入就能够创作出高质量的视频内容。然而,我们常见的电影片段通常是由导演在一个场景中精心布置多个目标的运动、摄像机拍摄角度后再剪辑而成的。例如,在拍摄赛车追逐的场景时,镜头通常跟随赛车运动,并通过扣人心弦的超车时刻来展示赛事的白热化。

刚刚,鹅厂开源“自定义”视频生成模型HunyuanCustom。
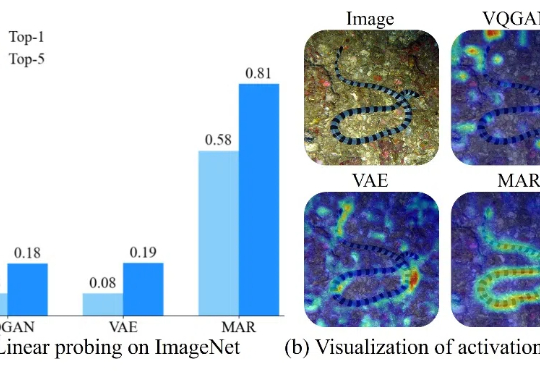
GPT-4o 生图功能的出现揭示了统一理解与生成模型的巨大潜力,然而如何在同一个框架内协调图像理解与生成这两种不同粒度的任务,是一个巨大的挑战。
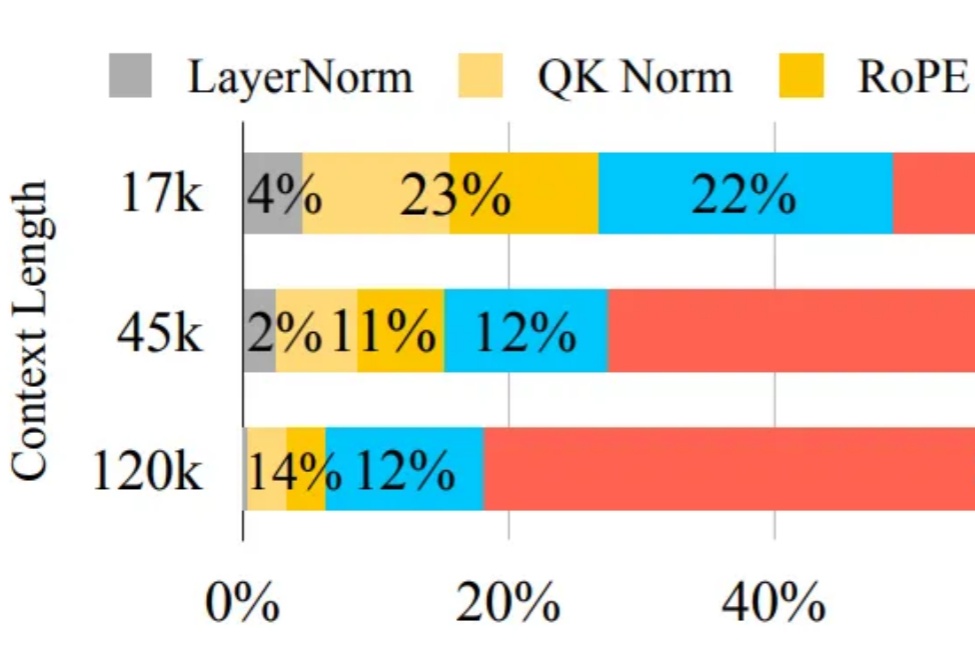
自 OpenAI 发布 Sora 以来,AI 视频生成技术进入快速爆发阶段。凭借扩散模型强大的生成能力,我们已经可以看到接近现实的视频生成效果。但在模型逼真度不断提升的同时,速度瓶颈却成为横亘在大规模应用道路上的最大障碍。
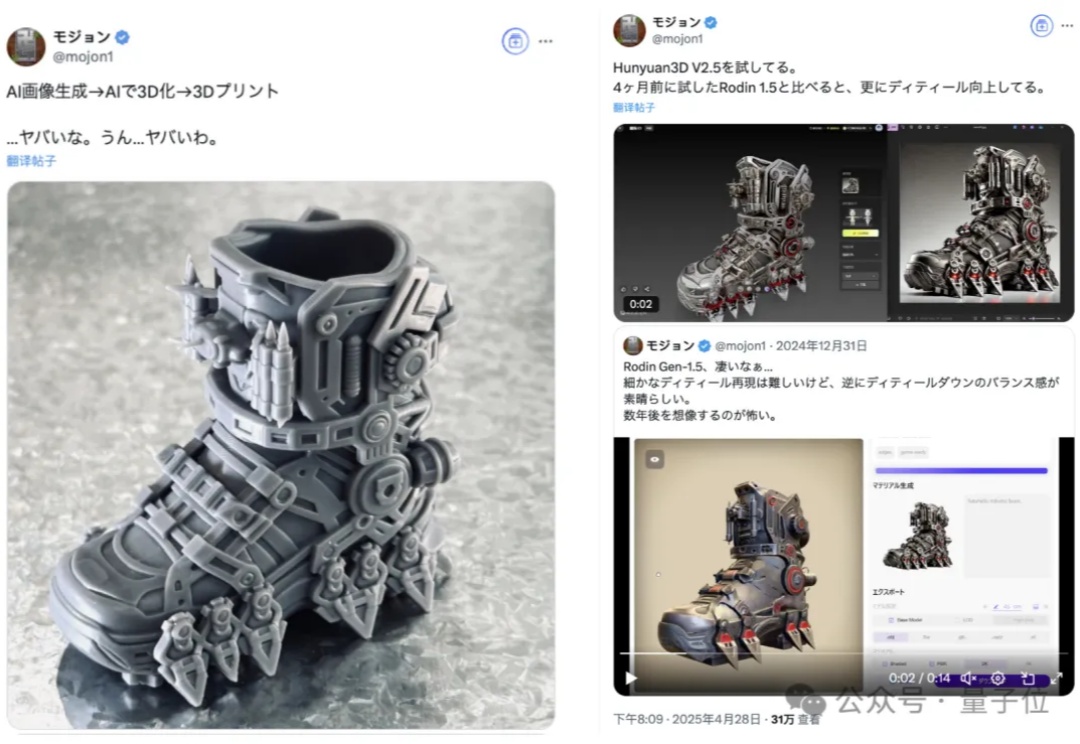
鹅厂最新的3D生成模型,狠狠地圈了一波粉,甚至有人拿它来创作小游戏动画了。

随着 Deepseek 等强推理模型的成功,强化学习在大语言模型训练中越来越重要,但在视频生成领域缺少探索。复旦大学等机构将强化学习引入到视频生成领域,经过强化学习优化的视频生成模型,生成效果更加自然流畅,更加合理。并且分别在 VDC(Video Detailed Captioning)[1] 和 VBench [2] 两大国际权威榜单中斩获第一。