
WithAnyone重磅开源:这可能是你见过最自然的AI合照模型
WithAnyone重磅开源:这可能是你见过最自然的AI合照模型和任何人,去任何地方!复旦大学携手阶跃星辰打破 “复制粘贴” 魔咒,重磅推出全新 AI 合照生成模型 WithAnyone —— 只需上传照片,就能一键生成自然、真实、毫无违和感的 AI 合照!
来自主题: AI技术研报
10875 点击 2025-11-17 10:20
 搜索
搜索
和任何人,去任何地方!复旦大学携手阶跃星辰打破 “复制粘贴” 魔咒,重磅推出全新 AI 合照生成模型 WithAnyone —— 只需上传照片,就能一键生成自然、真实、毫无违和感的 AI 合照!
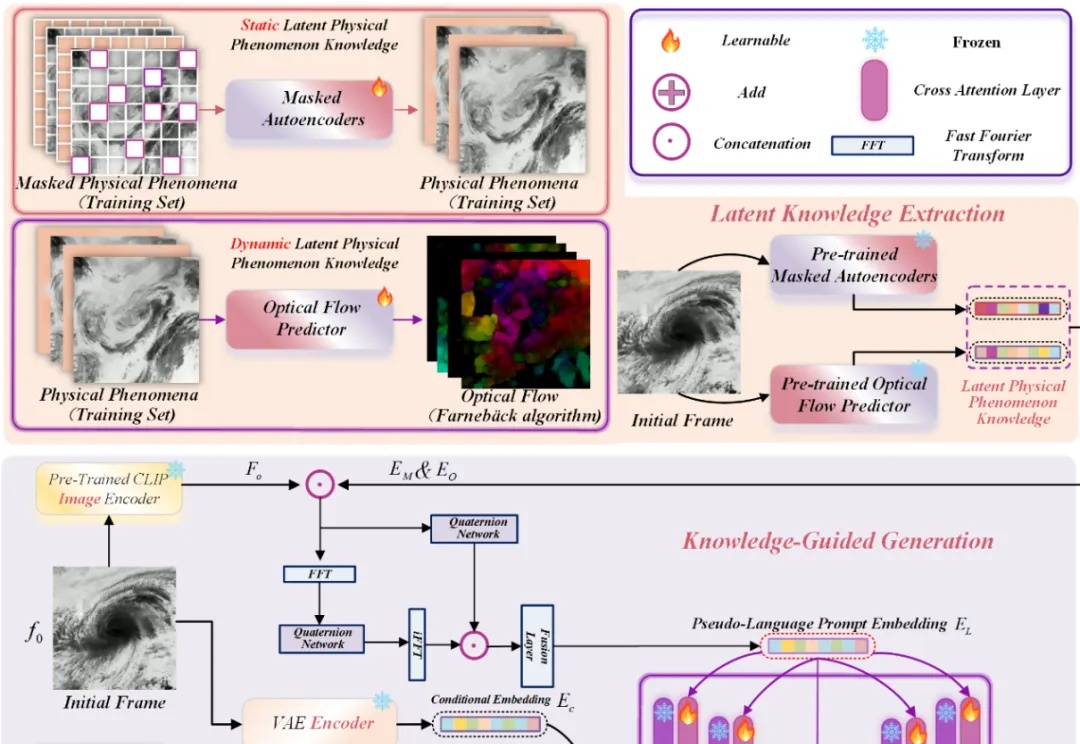
近年来,Stable Diffusion、CogVideoX 等视频生成模型在自然场景中表现惊艳,但面对科学现象 —— 如流体模拟或气象过程 —— 却常常 “乱画”:如下视频所示,生成的流体很容易产生违背物理直觉的现象,比如气旋逆向旋转或整体平移等等。

Marble,终于来了。 没错,就是两个月前在 AI 圈刷屏的那个 3D 世界生成模型。就在刚刚,李飞飞旗下的 World Labs 公司官宣向全体用户开放,还一次性放出了一大波新功能。 多模态生成:

近日,诺贝尔奖得主、美国华盛顿大学教授大卫·贝克(David Baker)和团队再次将 AI 成果送上 Nature,他们开发出一种基于 AI 的蛋白质结构生成模型 RFdiffusion,能在指定病毒表面特定表位的情况下,辅助人类从头设计出能够与之结合的抗体结构。
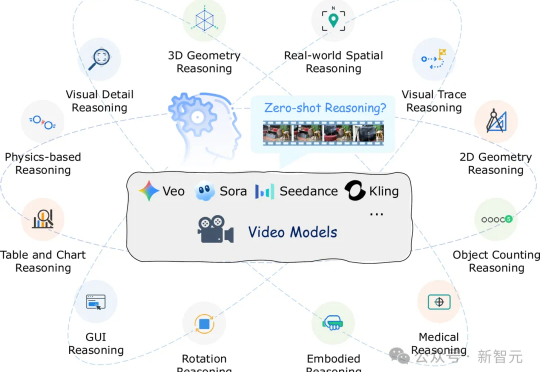
视频生成模型如Veo-3能生成逼真视频,但有研究发现其推理能力存疑。香港中文大学、北京大学、东北大学的研究者们设计了12项测试,发现模型只能模仿表面模式,未真正理解因果。这项研究为视频模型推理能力评估提供基准,指明未来研究方向。

近年来,基于扩散模型的图像生成技术发展迅猛,催生了Stable Diffusion、Midjourney等一系列强大的文生图应用。然而,当前主流的训练范式普遍依赖一个核心组件——变分自编码器(VAE),这也带来了长久以来困扰研究者们的几个问题:
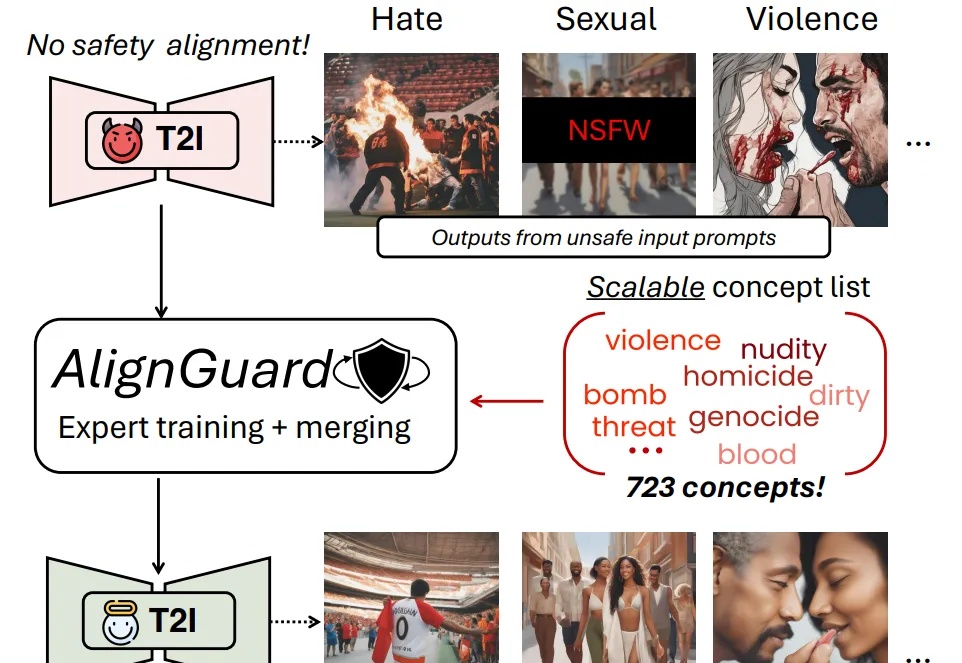
随着文图生成模型的广泛应用,模型本身有限的安全防护机制使得用户有机会无意或故意生成有害的图片内容,并且该内容有可能会被恶意使用。现有的安全措施主要依赖文本过滤或概念移除的策略,只能从文图生成模型的生成能力中移除少数几个概念。
美团,你是跨界上瘾了是吧!(doge)没错,最新开源SOTA视频模型,又是来自这家“送外卖”的公司。模型名为LongCat-Video,参数13.6B,支持文生/图生视频,视频时长可达数分钟。
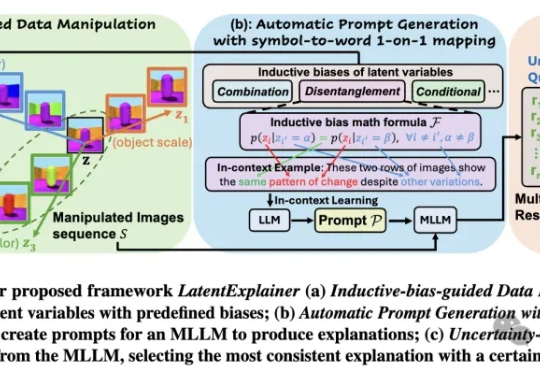
我们被「黑箱」困住了!深度生成模型虽能创造逼真内容,但其内部运作机制如同「黑箱」,潜变量的意义难以捉摸。埃默里大学团队提出LatentExplainer框架,巧妙地将潜在变量转化为易懂解释,大幅提升模型解释质量与可靠性。
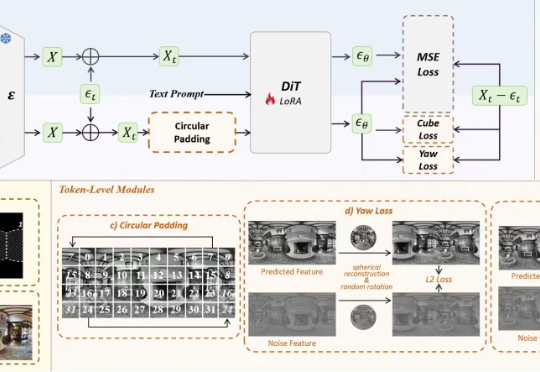
空间智能领域的全景数据稀缺问题,有解了。影石研究院团队,推出了基于DiT架构的全景图像生成模型DiT360。通过全新的全景图像生成框架,DiT360能够实现高质量的全景生成。