
刚刚,谷歌Veo 3.1迎来重大更新,硬刚Sora 2
刚刚,谷歌Veo 3.1迎来重大更新,硬刚Sora 2正如前几天网上泄露与传闻所预料的那样,深夜,谷歌发布了最新的 AI 视频生成模型 Veo 3.1。Veo 3.1 带来了更丰富的音频、叙事控制,以及更逼真的质感还原。在 Veo 3 的基础上,Veo 3.1 进一步提升了提示词遵循度,并在以图生视频时提供更高的视听质量。
来自主题: AI资讯
9370 点击 2025-10-16 09:48
 搜索
搜索
正如前几天网上泄露与传闻所预料的那样,深夜,谷歌发布了最新的 AI 视频生成模型 Veo 3.1。Veo 3.1 带来了更丰富的音频、叙事控制,以及更逼真的质感还原。在 Veo 3 的基础上,Veo 3.1 进一步提升了提示词遵循度,并在以图生视频时提供更高的视听质量。
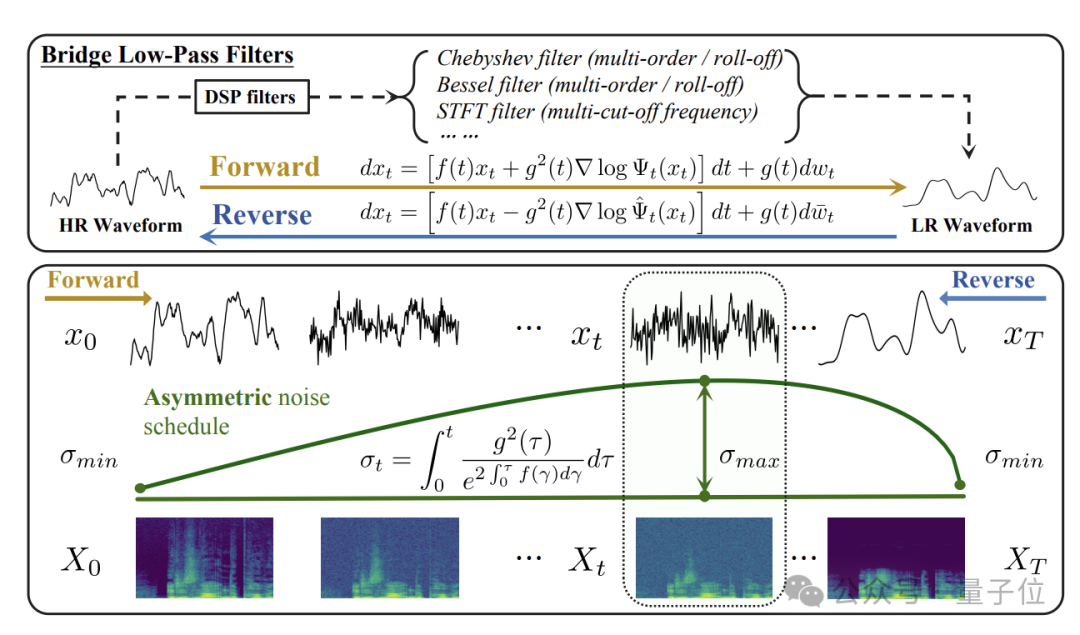
在这一背景下,清华大学与生数科技(Shengshu AI)团队围绕桥类生成模型与音频超分任务展开系统研究,先后在语音领域顶级会议ICASSP 2025和机器学习顶级会议NeurIPS 2025发表了两项连续成果:

本研究由新加坡国立大学 ShowLab 团队主导完成。 共一作者 Yanzhe Chen 陈彦哲(博士生)与 Kevin Qinghong Lin 林庆泓(博士生)均来自 ShowLab@NUS,分别聚焦于多模态理解以及智能体(Agent)研究。 项目负责人为新加坡国立大学校长青年助理教授 Mike Zheng Shou 寿政。

今天凌晨,马斯克的大模型独角兽xAI祭出最新视频生成模型Imagine v0.9,免费向所有用户开放。一周前,OpenAI发布了旗舰视频和音频生成模型Sora 2,此次更新或许是马斯克对Sora 2的直接回应。

业界首个高质量原生3D组件生成模型来了!来自腾讯混元3D团队。现有的3D生成算法通常会生成一体化的3D模型,而下游应用通常需要语义可分解的3D形状,即3D物体的每一个组件需要单独地生成出来。

我一个 AI 圈的,为啥会关注到电影圈呢?倒不是因为我爱看电影,而是因为电影节的放映单元,突然冒出来了我们圈子里几个“老熟人”:Seedream(图像创作模型)、Seedance(视频生成模型)、即梦 AI。
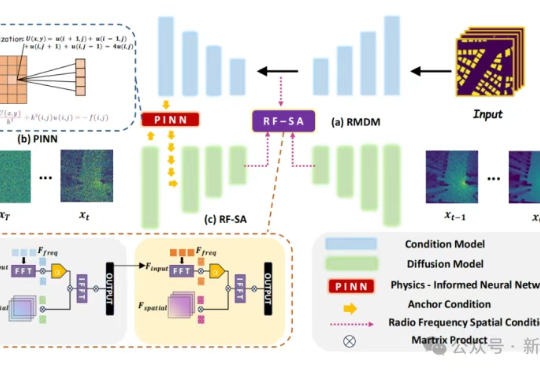
抢滩6G前夜,AI加物理正在重塑无线电地图产业格局。香港科技大学(广州)等机构联手重磅发布PhyRMDM框架,打破认知盲区,将物理约束与生成模型能力融合一体,显著提升高精度无线电地图的生成质量与稳定性。这一成果已被顶会ACM MM 2025接收。
夸克“造点”AI发布了!直接上大招,Wan2.5+Midjourney V7双强模型联合!夸克“造点”还在今天第一时间,率先接入了阿里自家刚刚发布的视频生成模型通义万相Wan2.5,甚至直接开放了7天免费体验。

刚刚,快手可灵AI基座模型再升级,推出可灵2.5 Turbo视频生成模型。AI视频玩家抹一把老泪,终于有AI视频模型让运动员们拥有不鬼畜自由了!a16z合伙人在𝕏上分享了一个可灵2.5 Turbo生成的视频:
深夜,阿里通义大模型团队连放三个大招:开源原生全模态大模型Qwen3-Omni、语音生成模型Qwen3-TTS、图像编辑模型Qwen-Image-Edit-2509更新。Qwen3-Omni能无缝处理文本、图像、音频和视频等多种输入形式,并通过实时流式响应同时生成文本与自然语音输出。